
") NVIDIA FLARE v2.0 is an open-source federated learning SDK that is making it easier for data scientists to collaborate to develop more generalizable robust AI models by just sharing model weights rather than private data.
NVIDIA FLARE v2.0 is an open-source federated learning SDK that is making it easier for data scientists to collaborate to develop more generalizable robust AI models by just sharing model weights rather than private data.
Federated learning (FL) has become a reality for many real-world applications. It enables multinational collaborations on a global scale to build more robust and generalizable machine learning and AI models. For more information, see Federated learning for predicting clinical outcomes in patients with COVID-19.
NVIDIA FLARE v2.0 is an open-source FL SDK that is making it easier for data scientists to collaborate to develop more generalizable robust AI models by just sharing model weights rather than private data.
For healthcare applications, this is particularly beneficial where data is patient protected, data may be sparse for certain patient types and diseases, or data lacks diversity across instrument types, genders, and geographies.
NVIDIA FLARE
NVIDIA FLARE stands for Federated Learning Application Runtime Environment. It is the engine underlying the NVIDIA Clara Train FL software, which has been used for AI applications in medical imaging, genetic analysis, oncology, and COVID-19 research. The SDK enables researchers and data scientists to adapt their existing machine learning and deep learning workflows to a distributed paradigm and enables platform developers to build a secure, privacy-preserving offering for distributed multiparty collaboration.
NVIDIA FLARE is a lightweight, flexible, and scalable distributed learning framework implemented in Python that is agnostic to your underlying training library. You can bring your own data science workflows implemented in PyTorch, TensorFlow, or even just NumPy, and apply them in a federated setting.
Maybe you’d like to implement the popular federated averaging (FedAvg) algorithm. Starting from an initial global model, each FL client trains the model on their local data for a certain amount of time and sends model updates to the server for aggregation. The server then uses the aggregated updates to update the global model for the next round of training. This process is iterated many times until the model converges.
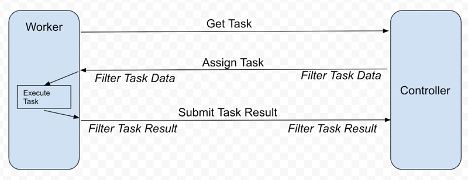
NVIDIA FLARE provides customizable controller workflows to help you implement FedAvg and other FL algorithms, for example, cyclic weight transfer. It schedules different tasks, such as deep learning training, to be executed on the participating FL clients. The workflows enable you to gather the results, such as model updates, from each client and aggregate them to update the global model and send back the updated global models for continued training. Figure 1 shows the principle.
Each FL client acts as a worker requesting the next task to be executed, such as model training. After the controller provides the task, the worker executes it and returns the results to the controller. At each communication, there can be optional filters that process the task data or results, for example, homomorphic encryption and decryption or differential privacy.
Your task for implementing FedAvg could be a simple PyTorch program that trains a classification model for CIFAR-10. Your local trainer could look something like the following code example. For this post, I skip the full training loop for simplicity.
import torch
import torch.nn as nn
import torch.nn.functional as F
from nvflare.apis.dxo import DXO, DataKind, MetaKey, from_shareable
from nvflare.apis.executor import Executor
from nvflare.apis.fl_constant import ReturnCode
from nvflare.apis.fl_context import FLContext
from nvflare.apis.shareable import Shareable, make_reply
from nvflare.apis.signal import Signal
from nvflare.app_common.app_constant import AppConstants
class SimpleNetwork(nn.Module):
def __init__(self):
super(SimpleNetwork, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class SimpleTrainer(Executor):
def __init__(self, train_task_name: str = AppConstants.TASK_TRAIN):
super().__init__()
self._train_task_name = train_task_name
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.model = SimpleNetwork()
self.model.to(self.device)
self.optimizer = torch.optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
self.criterion = nn.CrossEntropyLoss()
def execute(self, task_name: str, shareable: Shareable, fl_ctx: FLContext, abort_signal: Signal) -> Shareable:
"""
This function is an extended function from the superclass.
As a supervised learning-based trainer, the train function will run
training based on model weights from `shareable`.
After finishing training, a new `Shareable` object will be submitted
to server for aggregation."""
if task_name == self._train_task_name:
epoch_len = 1
# Get current global model weights
dxo = from_shareable(shareable)
# Ensure data kind is weights.
if not dxo.data_kind == DataKind.WEIGHTS:
self.log_exception(fl_ctx, f"data_kind expected WEIGHTS but got {dxo.data_kind} instead.")
return make_reply(ReturnCode.EXECUTION_EXCEPTION) # creates an empty Shareable with the return code
# Convert weights to tensor and run training
torch_weights = {k: torch.as_tensor(v) for k, v in dxo.data.items()}
self.local_train(fl_ctx, torch_weights, epoch_len, abort_signal)
# compute the differences between torch_weights and the now locally trained model
model_diff = ...
# build the shareable using a Data Exchange Object (DXO)
dxo = DXO(data_kind=DataKind.WEIGHT_DIFF, data=model_diff)
dxo.set_meta_prop(MetaKey.NUM_STEPS_CURRENT_ROUND, epoch_len)
self.log_info(fl_ctx, "Local training finished. Returning shareable")
return dxo.to_shareable()
else:
return make_reply(ReturnCode.TASK_UNKNOWN)
def local_train(self, fl_ctx, weights, epoch_len, abort_signal):
# Your training routine should respect the abort_signal.
...
# Your local training loop ...
for e in range(epoch_len):
...
if abort_signal.triggered:
self._abort_execution()
...
def _abort_execution(self, return_code=ReturnCode.ERROR) -> Shareable:
return make_reply(return_code)
You can see that your task implementations could be doing many different tasks. You could compute summary statistics on each client and share with the server (keeping privacy constraints in mind), perform preprocessing of the local data, or evaluate already trained models.
During FL training, you can plot the performance of the global model at the beginning of each training round. For this example, we ran with eight clients on a heterogenous data split of CIFAR-10. In the following plot (Figure 2), I show the different configurations that are available in NVIDIA FLARE 2.0 by default:
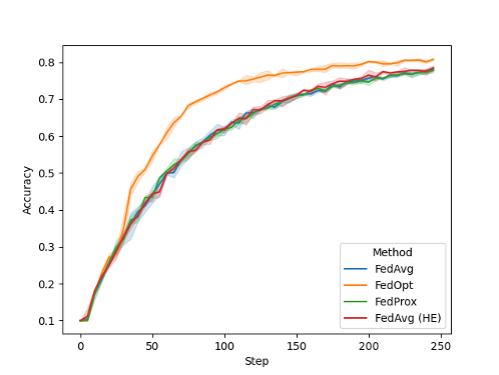
While FedAvg, FedAvg HE, and FedProx perform comparably for this task, you can observe an improved convergence using the FedOpt setting that uses SGD with momentum to update the global model on the server.
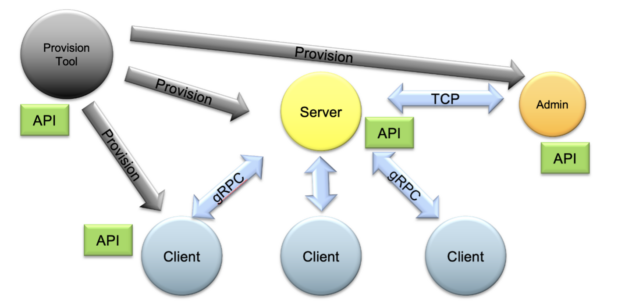
The whole FL system can be controlled using the admin API to automatically start and operate differently configured tasks and workflows. NVIDIA also provides a comprehensive provisioning system that enables the easy and secure deployment of FL applications in the real world but also proof-of-concept studies for running local FL simulations.
Get started
NVIDIA FLARE makes FL accessible to a wider range of applications. Potential use cases include helping energy companies analyze seismic and wellbore data, manufacturers optimize factory operations, and financial firms improve fraud detection models.
For more information and step-by-step examples, see NVIDIA/NVFlare on GitHub.