
Before she entered high school, Ge Dong wanted to be a physicist like her mom, a professor at Shanghai Jiao Tong University.
Month: September 2023
Rafi Nizam is an award-winning independent animator, director, character designer and more. He’s developed feature films at Sony Pictures, children’s series and comedies at BBC and global transmedia content at NBCUniversal.
 On Sept. 12, learn about the connection between MATLAB and NVIDIA Isaac Sim through ROS.
On Sept. 12, learn about the connection between MATLAB and NVIDIA Isaac Sim through ROS.
On Sept. 12, learn about the connection between MATLAB and NVIDIA Isaac Sim through ROS.
With coral reefs in rapid decline across the globe, researchers from the University of Hawaii at Mānoa have pioneered an AI-based surveying tool that monitors reef health from the sky. Using deep learning models and high-resolution satellite imagery powered by NVIDIA GPUs, the researchers have developed a new method for spotting and tracking coral reef Read article >
Creating 3D scans of physical products can be time consuming. Businesses often use traditional methods, like photogrammetry-based apps and scanners, but these can take hours or even days. They also don’t always provide the 3D quality and level of detail needed to make models look realistic in all its applications. Italy-based startup Covision Media is Read article >
Underscoring NVIDIA’s growing relationship with the global technology superpower, Indian Prime Minister Narendra Modi met with NVIDIA founder and CEO Jensen Huang Monday evening. The meeting at 7 Lok Kalyan Marg — as the Prime Minister’s official residence in New Delhi is known — comes as Modi prepares to host a gathering of leaders from Read article >
 Every year, as part of their coursework, students from the University of Warsaw, Poland get to work under the supervision of engineers from the NVIDIA Warsaw…
Every year, as part of their coursework, students from the University of Warsaw, Poland get to work under the supervision of engineers from the NVIDIA Warsaw…
Every year, as part of their coursework, students from the University of Warsaw, Poland get to work under the supervision of engineers from the NVIDIA Warsaw office on challenging problems in deep learning and accelerated computing. We present the work of three M.Sc. students—Alicja Ziarko, Paweł Pawlik, and Michał Siennicki—who managed to significantly reduce the latency in TorToiSe, a multi-stage, diffusion-based, text-to-speech (TTS) model.
Alicja, Paweł, and Michał first learned about the recent advancements in speech synthesis and diffusion models. They chose the combination of classifier-free guidance and progressive distillation, which performs well in computer vision, and adapted it to speech synthesis, achieving a 5x reduction in diffusion latency without a regression in speech quality. Small perceptual speech tests confirmed the results. Notably, this approach does not require costly training from scratch on the original model.
Why speed up diffusion-based TTS?
Since the publication of WaveNet in 2016, neural networks have become the primary models for speech synthesis. In simple applications, such as synthesis for AI-based voice assistants, synthetic voices are almost indistinguishable from human speech. Such voices can be synthesized orders of magnitudes faster than real time, for instance with the NVIDIA NeMo AI toolkit.
However, achieving high expressivity or imitating a voice based on a few seconds of recorded speech (few-shot) is still considered challenging.
Denoising Diffusion Probabilistic Models (DDPMs) emerged as a generative technique that enables the generation of images of great quality and expressivity based on input text. DDPMs can be readily applied to TTS because a frequency-based spectrogram, which graphically represents a speech signal, can be processed like an image.
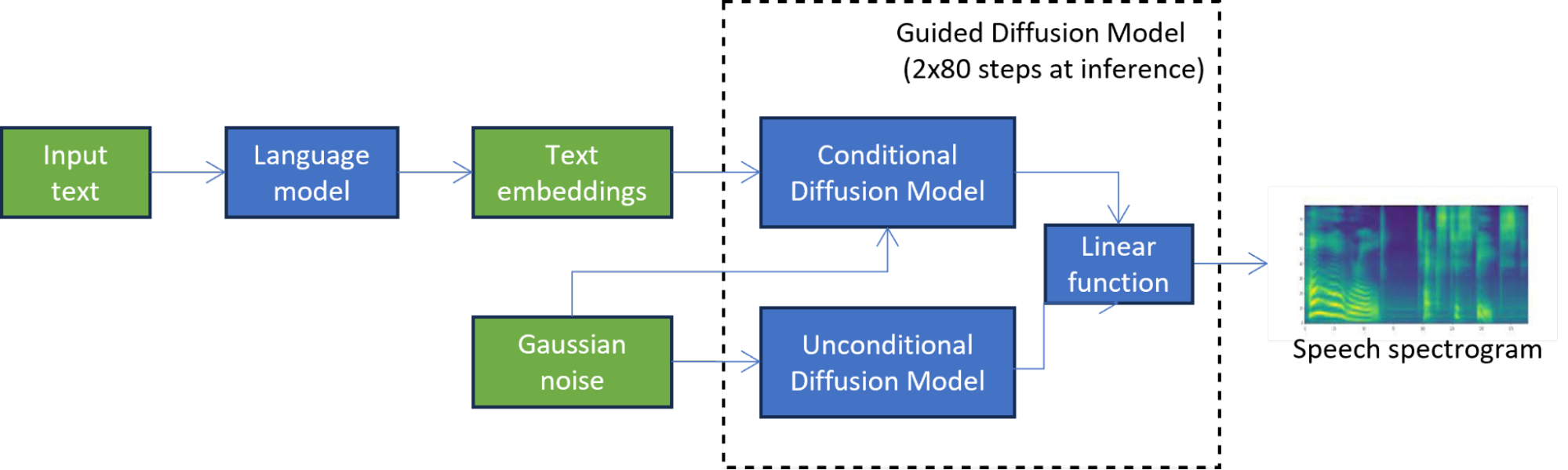
For instance, in TorToiSe, which is a guided diffusion-based TTS model, a spectrogram is generated by combining the results of two diffusion models (Figure 1). The iterative diffusion process involves hundreds of steps to achieve a high-quality output, significantly increasing latency compared to state-of-the-art TTS methods, which severely limits its applications.
In Figure 1, the unconditional diffusion model iteratively refines the initial noise until a high-quality spectrogram is obtained. The second diffusion model is further conditioned on the text embeddings produced by the language model.
Methods for speeding up diffusion
Existing latency reduction techniques in diffusion-based TTS can be divided into training-free and training-based methods.
Training-free methods do not involve training the network used to generate images by reversing the diffusion process. Instead, they only focus on optimizing the multi-step diffusion process. The diffusion process can be seen as solving ODE/SDE equations, so one way to optimize it is to create a better solver like DDPM, DDIM, and DPM, which lowers the number of diffusion steps. Parallel sampling methods, such as those based on Picard iterations or Normalizing Flows, can parallelize the diffusion process to benefit from parallel computing on GPUs.
Training-based methods focus on optimizing the network used in the diffusion process. The network can be pruned, quantized, or sparsified, and then fine-tuned for higher accuracy. Alternatively, its neural architecture can be changed manually or automatically using NAS. Knowledge distillation techniques enable distilling the student network from the teacher network to reduce the number of steps in the diffusion process.
Distillation in diffusion-based TTS
Alicja, Paweł, and Michał decided to use the distillation approach based on promising results in computer vision and its potential for an estimated 5x reduction in latency of the diffusion model at inference. They have managed to adapt progressive distillation to the diffusion part of a pretrained TorToiSe model, overcoming problems like the lack of access to the original training data.
Their approach consists of two knowledge distillation phases:
- Mimicking the guided diffusion model output
- Training another student model
In the first knowledge distillation phase (Figure 2), the student model is trained to mimic the output of the guided diffusion model at each diffusion step. This phase reduces latency by half by combining the two diffusion models into one model.
To address the lack of access to the original training data, text embeddings from the language model are passed through the original teacher model to generate synthetic data used in distillation. The use of synthetic data also makes the distillation process more efficient because the entire TTS, guided diffusion pipeline does not have to be invoked at each distillation step.
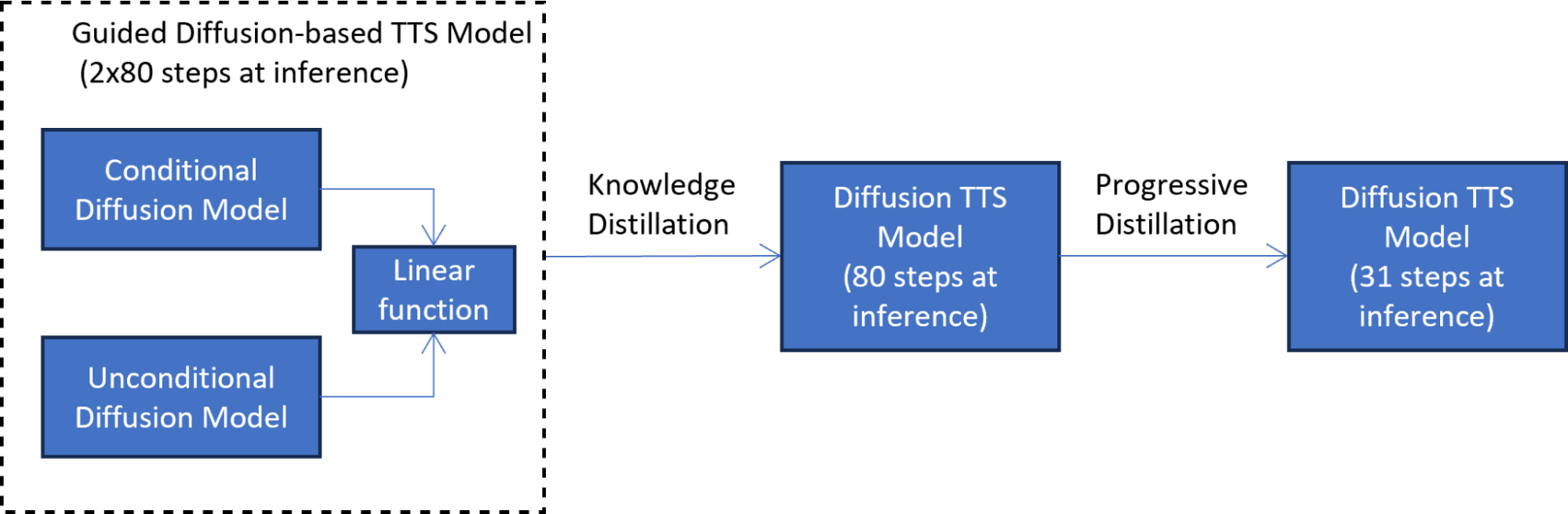
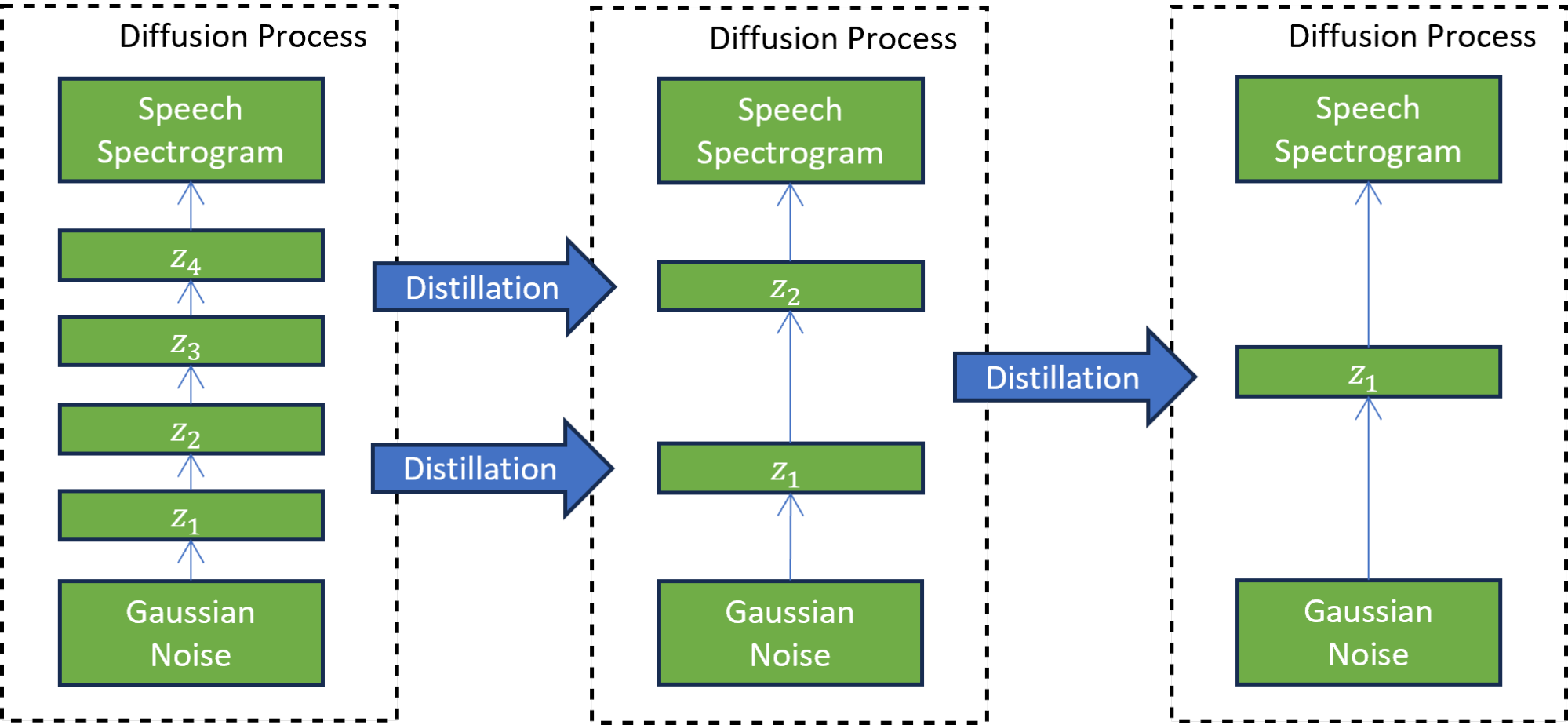
In the second progressive distillation phase (Figure 3), the newly trained student model serves as a teacher to train another student model. In this technique, the student model is trained to mimic the teacher model while reducing the number of diffusion steps by a factor of two. This process is repeated many times to further reduce the number of steps, while each time, a new student serves as the teacher for the next round of distillation.
A progressive distillation with seven iterations reduces the number of inference steps 7^2 times, from 4,000 steps on which the model was trained to 31 steps. This reduction results in a 5x speedup compared to the guided diffusion model, excluding the text embedding calculation cost.
The perceptual pairwise speech test shows that the distilled model (after the second phase) matches the quality of speech produced by the TTS model based on guided distillation.
As an example, listen to audio samples in Table 1 generated by the progressive distillation-based TTS model. The samples match the quality of the audio samples from the guided diffusion-based TTS model. If we simply reduced the number of distillation steps to 31, instead of using progressive distillation, the quality of the generated speech deteriorates significantly.
|
Speaker |
Guided diffusion-based TTS model (2×80 diffusion steps) |
Diffusion-based TTS after progressive distillation (31 diffusion steps) |
Guided diffusion-based TTS model (naive reduction to 31 diffusion steps) |
|---|---|---|---|
| Female 1 |
Audio | Audio | Audio |
| Female 2 | Audio | Audio | Audio |
| Female 3 | Audio | Audio | Audio |
| Male 1 | Audio | Audio | Audio |
Conclusion
Collaborating with academia and assisting young students in shaping their future in science and engineering is one of the core NVIDIA values. Alicja, Paweł, and Michał’s successful project exemplifies the NVIDIA Warsaw, Poland office partnership with local universities.
The students managed to solve the challenging problem of speeding up the pretrained, diffusion-based, text-to-speech (TTS) model. They designed and implemented a knowledge distillation-based solution in the complex field of diffusion-based TTS, achieving a 5x speedup of the diffusion process. Most notably, their unique solution based on synthetic data generation is applicable to pretrained TTS models without access to the original training data.
We encourage you to explore NVIDIA Academic Programs and try out the NVIDIA NeMo Framework to create complete conversational AI (TTS, ASR, or NLP/LLM) solutions for the new era of generative AI.
Categories
Advanced API Performance: Shaders
 This post covers best practices when working with shaders on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced…
This post covers best practices when working with shaders on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced…
This post covers best practices when working with shaders on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
Shaders play a critical role in graphics programming by enabling you to control various aspects of the rendering process. They run on the GPU and are responsible for manipulating vertices, pixels, and other data.
- General shaders
- Compute shaders
- Pixel shaders
- Vertex shaders
- Geometry, domain, and hull shaders
General shaders
These tips apply to all types of shaders.
Recommended
- Avoid warp-divergent constant buffer view (CBV) and immediate constant buffer (ICB) reads.
- Constant buffer reads are most effective when threads in a warp access data uniformly. If you need divergent reads, use shader resource view (SRVs).
- Typical cases where SRVs should be preferred over CBVs include the following:
- Bones or skinning data
- Lookup tables, like precomputed random numbers
- To optimize buffers and group shared memory, use manual bit packing. When creating structures for packing data, consider the range of values a field can hold and choose the smallest datatype that can encompass this range.
- Optimize control flow by providing hints of the expected runtime behavior.
- Make sure to enable compile flag -all-resources-bound for DXC (or D3DCOMPILE_ALL_RESOURCES_BOUND in FXC) if possible. This enables a larger set of driver-side optimizations.
- Consider using the [FLATTEN] and [BRANCH] keywords where appropriate.
- A conditional branch may prevent the compiler from hoisting long-latency instructions, such as texture fetches.
- The [FLATTEN] keyword hints that the compiler is free to hoist and start the load operations before the statement has been evaluated.
- Use Root Signature 1.1 to specify static data and descriptors to enable the driver to make the most optimal shader optimizations.
- Keep the register use to a minimum. Register allocation could limit occupancy and may force the driver to spill registers to memory.
- Prefer the use of gather instructions when loading single channel texture quads.
- This will cut down the expected latency by almost 4x compared to the equivalent operation constructed from consecutive sample instructions.
- Prefer structured buffers over raw buffers.
- Structured buffers have stricter alignment requirements, which enables the driver to schedule more efficient load instructions.
- Consider using numerical approximations or precomputed lookup tables of transcendental functions (exp, log, sin, cos, sqrt) in math-intensive shaders, for instance, physics simulations and denoisers.
- To promote a fast path in the TEX unit, with up to 2x speedup, use point filtering in certain circumstances:
- Low-resolution textures where point filtering is already an accurate representation.
- Textures that are being accessed at their native resolution.
Not recommended
- Don’t assume that half-precision floats are always faster than full precision and the reverse.
- On NVIDIA Ampere GPUs, it’s just as efficient to execute FP32 as FP16 instructions. The overhead of converting between precision formats may just end up with a net loss.
- NVIDIA Turing GPUs may benefit from using FP16 math, as FP16 can be issued at twice the rate of FP32.
Compute shaders
Compute shaders are used for general-purpose computations, from data processing and simulations to machine learning.
Recommended
- Consider using wave intrinsics over group shared memory when possible for communication across threads.
- Wave intrinsics don’t require explicit thread synchronization.
- Starting from SM 6.0, HLSL supports warp-wide wave intrinsics natively without the need for vendor-specific HLSL extensions. Consider using vendor-specific APIs only when the expected functionality is missing. For more information, see Unlocking GPU Intrinsics in HLSL.
- To increase atomic throughput, use wave instructions to coalesce atomic operations across a warp.
- To maximize cache locality and to improve L1 and L2 hit rate, try thread group ID swizzling for full-screen compute passes.
- A good starting point is to target a thread group size corresponding to between two or eight warps. For instance, thread group size 8x8x1 or 16x16x1 for full-screen passes. Make sure to profile your shader and tune the dimensions based on profiling results.
Not recommended
- Do not make your thread group size difficult to scale per platform and GPU architecture.
- Specialization constants can be used in Vulkan to set the dimensions at pipeline creation time whereas HLSL requires the thread group size to be known at shader compile time.
- Be careless of thread group launch latency.
- If your CS has early-out conditions that are expected to early out in most cases, it might be better to choose larger thread group dimensions and cut down on the total number of thread groups launched.
Pixel shaders
Pixel shaders, also known as fragment shaders, are used to calculate effects on a per-pixel basis.
Recommended
- Prefer the use of depth bounds test or stencil and depth testing over manual depth tests in pixel shaders.
- Depth and stencil tests may discard entire 16×16 raster tiles down to individual pixels. Make sure that Early-Z is enabled.
- Be mindful of the use patterns that may force the driver to disable Early-Z testing:
- Conditional z-writes such as clip and discard
- As an alternative consider using null blend ops instead
- Pixel shader depth write
- Writing to UAV resources
- Conditional z-writes such as clip and discard
- Consider converting your full screen pass to a compute shader if there’s a large difference in latency between warps.
Not recommended
- Don’t use raster order view (ROV) techniques pervasively.
- Guaranteeing order doesn’t come for free.
- Always compare with alternative approaches like advanced blending ops and atomics.
Vertex shaders
Vertex shaders are used to calculate effects on a per-vertex basis.
Recommended
- Prefer the use of compressed vertex formats.
- Prefer the use of SRVs for skinning data over CBVs. This is a typical case of divergent CBV reads.
Geometry, domain, and hull shaders
Geometry, domain, and hull shaders are used to control, evaluate, and generate geometry, enabling tessellation to create a dynamic generation of surfaces and objects.
Recommended
- Replace the geometry, domain, and hull shaders with the mesh shading capabilities introduced in NVIDIA Turing.
- Enable the fast geometry path with the following configuration:
- Fixed topology: Neither an expansion or reduction in the number of vertices.
- Fixed primitive type: The input primitive type is equal to the output primitive type.
- Immutable per-vertex attributes: The application cannot change the vertex attributes and can only copy them from the input to the output.
- Mutable per-primitive attributes: The application can compute a single value for the whole primitive, which then is passed to the fragment shader stage. For example, it can compute the area of the triangle.
Acknowledgments
Thanks to Ryan Prescott, Ana Mihut, Katherine Sun, and Ivan Fedorov.