The last few years have seen rapid progress in systems that can automatically process complex business documents and turn them into structured objects. A system that can automatically extract data from documents, e.g., receipts, insurance quotes, and financial statements, has the potential to dramatically improve the efficiency of business workflows by avoiding error-prone, manual work. Recent models, based on the Transformer architecture, have shown impressive gains in accuracy. Larger models, such as PaLM 2, are also being leveraged to further streamline these business workflows. However, the datasets used in academic literature fail to capture the challenges seen in real-world use cases. Consequently, academic benchmarks report strong model accuracy, but these same models do poorly when used for complex real-world applications.
In “VRDU: A Benchmark for Visually-rich Document Understanding”, presented at KDD 2023, we announce the release of the new Visually Rich Document Understanding (VRDU) dataset that aims to bridge this gap and help researchers better track progress on document understanding tasks. We list five requirements for a good document understanding benchmark, based on the kinds of real-world documents for which document understanding models are frequently used. Then, we describe how most datasets currently used by the research community fail to meet one or more of these requirements, while VRDU meets all of them. We are excited to announce the public release of the VRDU dataset and evaluation code under a Creative Commons license.
Benchmark requirements
First, we compared state-of-the-art model accuracy (e.g., with FormNet and LayoutLMv2) on real-world use cases to academic benchmarks (e.g., FUNSD, CORD, SROIE). We observed that state-of-the-art models did not match academic benchmark results and delivered much lower accuracy in the real world. Next, we compared typical datasets for which document understanding models are frequently used with academic benchmarks and identified five dataset requirements that allow a dataset to better capture the complexity of real-world applications:
- Rich Schema: In practice, we see a wide variety of rich schemas for structured extraction. Entities have different data types (numeric, strings, dates, etc.) that may be required, optional, or repeated in a single document or may even be nested. Extraction tasks over simple flat schemas like (header, question, answer) do not reflect typical problems encountered in practice.
- Layout-Rich Documents: The documents should have complex layout elements. Challenges in practical settings come from the fact that documents may contain tables, key-value pairs, switch between single-column and double-column layout, have varying font-sizes for different sections, include pictures with captions and even footnotes. Contrast this with datasets where most documents are organized in sentences, paragraphs, and chapters with section headers — the kinds of documents that are typically the focus of classic natural language processing literature on long inputs.
- Diverse Templates: A benchmark should include different structural layouts or templates. It is trivial for a high-capacity model to extract from a particular template by memorizing the structure. However, in practice, one needs to be able to generalize to new templates/layouts, an ability that the train-test split in a benchmark should measure.
- High-Quality OCR: Documents should have high-quality Optical Character Recognition (OCR) results. Our aim with this benchmark is to focus on the VRDU task itself and to exclude the variability brought on by the choice of OCR engine.
- Token-Level Annotation: Documents should contain ground-truth annotations that can be mapped back to corresponding input text, so that each token can be annotated as part of the corresponding entity. This is in contrast with simply providing the text of the value to be extracted for the entity. This is key to generating clean training data where we do not have to worry about incidental matches to the given value. For instance, in some receipts, the ‘total-before-tax’ field may have the same value as the ‘total’ field if the tax amount is zero. Having token level annotations prevents us from generating training data where both instances of the matching value are marked as ground-truth for the ‘total’ field, thus producing noisy examples.
 |
VRDU datasets and tasks
The VRDU dataset is a combination of two publicly available datasets, Registration Forms and Ad-Buy forms. These datasets provide examples that are representative of real-world use cases, and satisfy the five benchmark requirements described above.
The Ad-buy Forms dataset consists of 641 documents with political advertisement details. Each document is either an invoice or receipt signed by a TV station and a campaign group. The documents use tables, multi-columns, and key-value pairs to record the advertisement information, such as the product name, broadcast dates, total price, and release date and time.
The Registration Forms dataset consists of 1,915 documents with information about foreign agents registering with the US government. Each document records essential information about foreign agents involved in activities that require public disclosure. Contents include the name of the registrant, the address of related bureaus, the purpose of activities, and other details.
We gathered a random sample of documents from the public Federal Communications Commission (FCC) and Foreign Agents Registration Act (FARA) sites, and converted the images to text using Google Cloud’s OCR. We discarded a small number of documents that were several pages long and the processing did not complete in under two minutes. This also allowed us to avoid sending very long documents for manual annotation — a task that can take over an hour for a single document. Then, we defined the schema and corresponding labeling instructions for a team of annotators experienced with document-labeling tasks.
The annotators were also provided with a few sample labeled documents that we labeled ourselves. The task required annotators to examine each document, draw a bounding box around every occurrence of an entity from the schema for each document, and associate that bounding box with the target entity. After the first round of labeling, a pool of experts were assigned to review the results. The corrected results are included in the published VRDU dataset. Please see the paper for more details on the labeling protocol and the schema for each dataset.
 |
| Existing academic benchmarks (FUNSD, CORD, SROIE, Kleister-NDA, Kleister-Charity, DeepForm) fall-short on one or more of the five requirements we identified for a good document understanding benchmark. VRDU satisfies all of them. See our paper for background on each of these datasets and a discussion on how they fail to meet one or more of the requirements. |
We built four different model training sets with 10, 50, 100, and 200 samples respectively. Then, we evaluated the VRDU datasets using three tasks (described below): (1) Single Template Learning, (2) Mixed Template Learning, and (3) Unseen Template Learning. For each of these tasks, we included 300 documents in the testing set. We evaluate models using the F1 score on the testing set.
- Single Template Learning (STL): This is the simplest scenario where the training, testing, and validation sets only contain a single template. This simple task is designed to evaluate a model’s ability to deal with a fixed template. Naturally, we expect very high F1 scores (0.90+) for this task.
- Mixed Template Learning (MTL): This task is similar to the task that most related papers use: the training, testing, and validation sets all contain documents belonging to the same set of templates. We randomly sample documents from the datasets and construct the splits to make sure the distribution of each template is not changed during sampling.
- Unseen Template Learning (UTL): This is the most challenging setting, where we evaluate if the model can generalize to unseen templates. For example, in the Registration Forms dataset, we train the model with two of the three templates and test the model with the remaining one. The documents in the training, testing, and validation sets are drawn from disjoint sets of templates. To our knowledge, previous benchmarks and datasets do not explicitly provide such a task designed to evaluate the model’s ability to generalize to templates not seen during training.
The objective is to be able to evaluate models on their data efficiency. In our paper, we compared two recent models using the STL, MTL, and UTL tasks and made three observations. First, unlike with other benchmarks, VRDU is challenging and shows that models have plenty of room for improvements. Second, we show that few-shot performance for even state-of-the-art models is surprisingly low with even the best models resulting in less than an F1 score of 0.60. Third, we show that models struggle to deal with structured repeated fields and perform particularly poorly on them.
Conclusion
We release the new Visually Rich Document Understanding (VRDU) dataset that helps researchers better track progress on document understanding tasks. We describe why VRDU better reflects practical challenges in this domain. We also present experiments showing that VRDU tasks are challenging, and recent models have substantial headroom for improvements compared to the datasets typically used in the literature with F1 scores of 0.90+ being typical. We hope the release of the VRDU dataset and evaluation code helps research teams advance the state of the art in document understanding.
Acknowledgements
Many thanks to Zilong Wang, Yichao Zhou, Wei Wei, and Chen-Yu Lee, who co-authored the paper along with Sandeep Tata. Thanks to Marc Najork, Riham Mansour and numerous partners across Google Research and the Cloud AI team for providing valuable insights. Thanks to John Guilyard for creating the animations in this post.
 NVIDIA Nsight Developer Tools provide comprehensive access to NVIDIA GPUs and graphics APIs for performance analysis, optimization, and debugging activities….
NVIDIA Nsight Developer Tools provide comprehensive access to NVIDIA GPUs and graphics APIs for performance analysis, optimization, and debugging activities….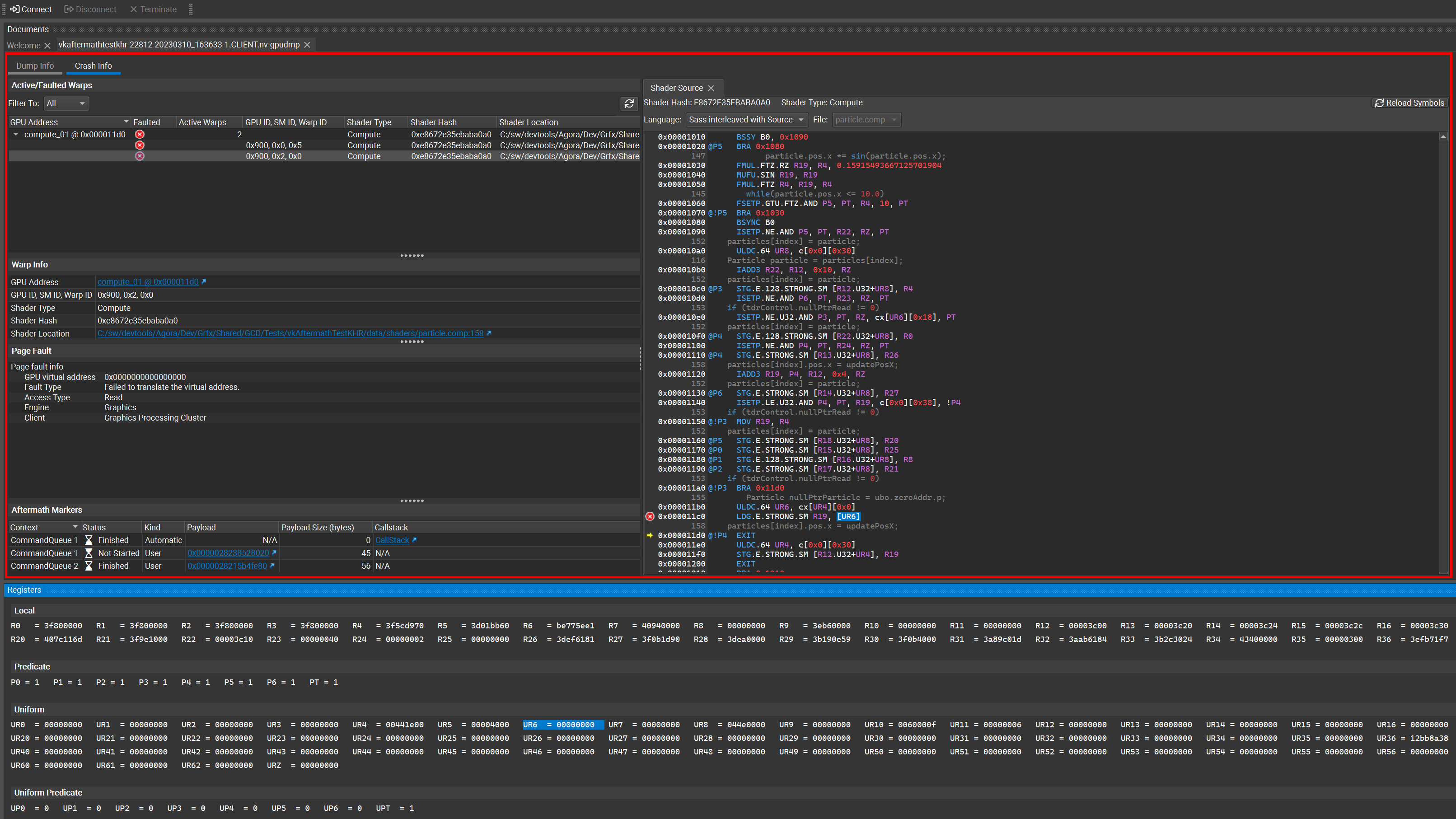
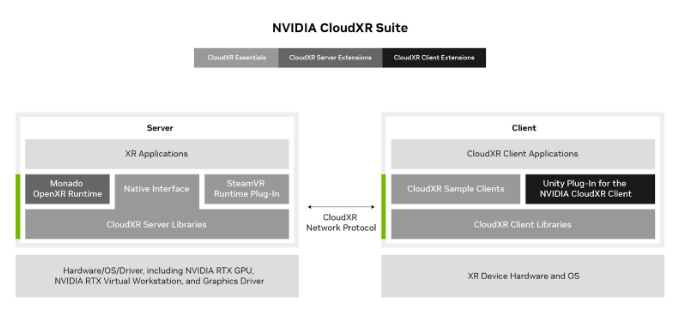
 NVIDIA is providing developers with an advanced platform to create scalable, branded, custom extended reality (XR) products with the new NVIDIA CloudXR Suite….
NVIDIA is providing developers with an advanced platform to create scalable, branded, custom extended reality (XR) products with the new NVIDIA CloudXR Suite….