
Bill Dally — one of the world’s foremost computer scientists and head of NVIDIA’s research efforts — will describe the forces driving accelerated computing and AI in his keynote address at Hot Chips, an annual gathering of leading processor and system architects. Dally will detail advances in GPU silicon, systems and software that are delivering Read article >
Month: August 2023
Bill Dally — one of the world’s foremost computer scientists and head of NVIDIA’s research efforts — will describe the forces driving accelerated computing and AI in his keynote address at Hot Chips, an annual gathering of leading processor and system architects. Dally will detail advances in GPU silicon, systems and software that are delivering Read article >
Categories
Event: Speech AI Day
 On Sept. 20, join experts from leading companies at NVIDIA-hosted Speech AI Day.
On Sept. 20, join experts from leading companies at NVIDIA-hosted Speech AI Day.
On Sept. 20, join experts from leading companies at NVIDIA-hosted Speech AI Day.
Categories
Google at Interspeech 2023

This week, the 24th Annual Conference of the International Speech Communication Association (INTERSPEECH 2023) is being held in Dublin, Ireland, representing one of the world’s most extensive conferences on research and technology of spoken language understanding and processing. Experts in speech-related research fields gather to take part in oral presentations and poster sessions and to build collaborations across the globe.
We are excited to be a Platinum Sponsor of INTERSPEECH 2023, where we will be showcasing more than 20 research publications and supporting a number of workshops and special sessions. We welcome in-person attendees to drop by the Google Research booth to meet our researchers and participate in Q&As and demonstrations of some of our latest speech technologies, which help to improve accessibility and provide convenience in communication for billions of users. In addition, online attendees are encouraged to visit our virtual booth in Topia where you can get up-to-date information on research and opportunities at Google. Visit the @GoogleAI Twitter account to find out about Google booth activities (e.g., demos and Q&A sessions). You can also learn more about the Google research being presented at INTERSPEECH 2023 below (Google affiliations in bold).
Board and Organizing Committee
ISCA Board, Technical Committee Chair: Bhuvana Ramabhadran
Area Chairs include:
Analysis of Speech and Audio Signals: Richard Rose
Speech Synthesis and Spoken Language Generation: Rob Clark
Special Areas: Tara Sainath
Satellite events
VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23)
Organizers include: Arsha Nagrani
ISCA Speech Synthesis Workshop (SSW12)
Speakers include: Rob Clark
Keynote talk – ISCA Medalist
Bridging Speech Science and Technology — Now and Into the Future
Speaker: Shrikanth Narayanan
Survey Talk
Speech Compression in the AI Era
Speaker: Jan Skoglund
Special session papers
Cascaded Encoders for Fine-Tuning ASR Models on Overlapped Speech
Richard Rose, Oscar Chang, Olivier Siohan
TokenSplit: Using Discrete Speech Representations for Direct, Refined, and Transcript-Conditioned Speech Separation and Recognition
Hakan Erdogan, Scott Wisdom, Xuankai Chang*, Zalán Borsos, Marco Tagliasacchi, Neil Zeghidour, John R. Hershey
Papers
DeePMOS: Deep Posterior Mean-Opinion-Score of Speech
Xinyu Liang, Fredrik Cumlin, Christian Schüldt, Saikat Chatterjee
O-1: Self-Training with Oracle and 1-Best Hypothesis
Murali Karthick Baskar, Andrew Rosenberg, Bhuvana Ramabhadran, Kartik Audhkhasi
Re-investigating the Efficient Transfer Learning of Speech Foundation Model Using Feature Fusion Methods
Zhouyuan Huo, Khe Chai Sim, Dongseong Hwang, Tsendsuren Munkhdalai, Tara N. Sainath, Pedro Moreno
MOS vs. AB: Evaluating Text-to-Speech Systems Reliably Using Clustered Standard Errors
Joshua Camp, Tom Kenter, Lev Finkelstein, Rob Clark
LanSER: Language-Model Supported Speech Emotion Recognition
Taesik Gong, Josh Belanich, Krishna Somandepalli, Arsha Nagrani, Brian Eoff, Brendan Jou
Modular Domain Adaptation for Conformer-Based Streaming ASR
Qiujia Li, Bo Li, Dongseong Hwang, Tara N. Sainath, Pedro M. Mengibar
On Training a Neural Residual Acoustic Echo Suppressor for Improved ASR
Sankaran Panchapagesan, Turaj Zakizadeh Shabestary, Arun Narayanan
MD3: The Multi-dialect Dataset of Dialogues
Jacob Eisenstein, Vinodkumar Prabhakaran, Clara Rivera, Dorottya Demszky, Devyani Sharma
Dual-Mode NAM: Effective Top-K Context Injection for End-to-End ASR
Zelin Wu, Tsendsuren Munkhdalai, Pat Rondon, Golan Pundak, Khe Chai Sim, Christopher Li
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Yochai Blau, Rohan Agrawal, Lior Madmony, Gary Wang, Andrew Rosenberg, Zhehuai Chen, Zorik Gekhman, Genady Beryozkin, Parisa Haghani, Bhuvana Ramabhadran
How to Estimate Model Transferability of Pre-trained Speech Models?
Zih-Ching Chen, Chao-Han Huck Yang*, Bo Li, Yu Zhang, Nanxin Chen, Shuo-yiin Chang, Rohit Prabhavalkar, Hung-yi Lee, Tara N. Sainath
Improving Joint Speech-Text Representations Without Alignment
Cal Peyser, Zhong Meng, Ke Hu, Rohit Prabhavalkar, Andrew Rosenberg, Tara N. Sainath, Michael Picheny, Kyunghyun Cho
Text Injection for Capitalization and Turn-Taking Prediction in Speech Models
Shaan Bijwadia, Shuo-yiin Chang, Weiran Wang, Zhong Meng, Hao Zhang, Tara N. Sainath
Streaming Parrotron for On-Device Speech-to-Speech Conversion
Oleg Rybakov, Fadi Biadsy, Xia Zhang, Liyang Jiang, Phoenix Meadowlark, Shivani Agrawal
Semantic Segmentation with Bidirectional Language Models Improves Long-Form ASR
W. Ronny Huang, Hao Zhang, Shankar Kumar, Shuo-yiin Chang, Tara N. Sainath
Universal Automatic Phonetic Transcription into the International Phonetic Alphabet
Chihiro Taguchi, Yusuke Sakai, Parisa Haghani, David Chiang
Mixture-of-Expert Conformer for Streaming Multilingual ASR
Ke Hu, Bo Li, Tara N. Sainath, Yu Zhang, Francoise Beaufays
Real Time Spectrogram Inversion on Mobile Phone
Oleg Rybakov, Marco Tagliasacchi, Yunpeng Li, Liyang Jiang, Xia Zhang, Fadi Biadsy
2-Bit Conformer Quantization for Automatic Speech Recognition
Oleg Rybakov, Phoenix Meadowlark, Shaojin Ding, David Qiu, Jian Li, David Rim, Yanzhang He
LibriTTS-R: A Restored Multi-speaker Text-to-Speech Corpus
Yuma Koizumi, Heiga Zen, Shigeki Karita, Yifan Ding, Kohei Yatabe, Nobuyuki Morioka, Michiel Bacchiani, Yu Zhang, Wei Han, Ankur Bapna
PronScribe: Highly Accurate Multimodal Phonemic Transcription from Speech and Text
Yang Yu, Matthew Perez*, Ankur Bapna, Fadi Haik, Siamak Tazari, Yu Zhang
Label Aware Speech Representation Learning for Language Identification
Shikhar Vashishth, Shikhar Bharadwaj, Sriram Ganapathy, Ankur Bapna, Min Ma, Wei Han, Vera Axelrod, Partha Talukdar
* Work done while at Google
The verdict is in: A GeForce NOW Ultimate membership raises the bar on gaming. Members have been tackling the Ultimate KovvaK’s challenge head-on and seeing for themselves how the power of Ultimate improves their gaming with 240 frames per second streaming. The popular training title that helps gamers improve their aim fully launches in the Read article >
Categories
Wanna help judge SoME3?
There has been great progress towards adapting large language models (LLMs) to accommodate multimodal inputs for tasks including image captioning, visual question answering (VQA), and open vocabulary recognition. Despite such achievements, current state-of-the-art visual language models (VLMs) perform inadequately on visual information seeking datasets, such as Infoseek and OK-VQA, where external knowledge is required to answer the questions.
 |
| Examples of visual information seeking queries where external knowledge is required to answer the question. Images are taken from the OK-VQA dataset. |
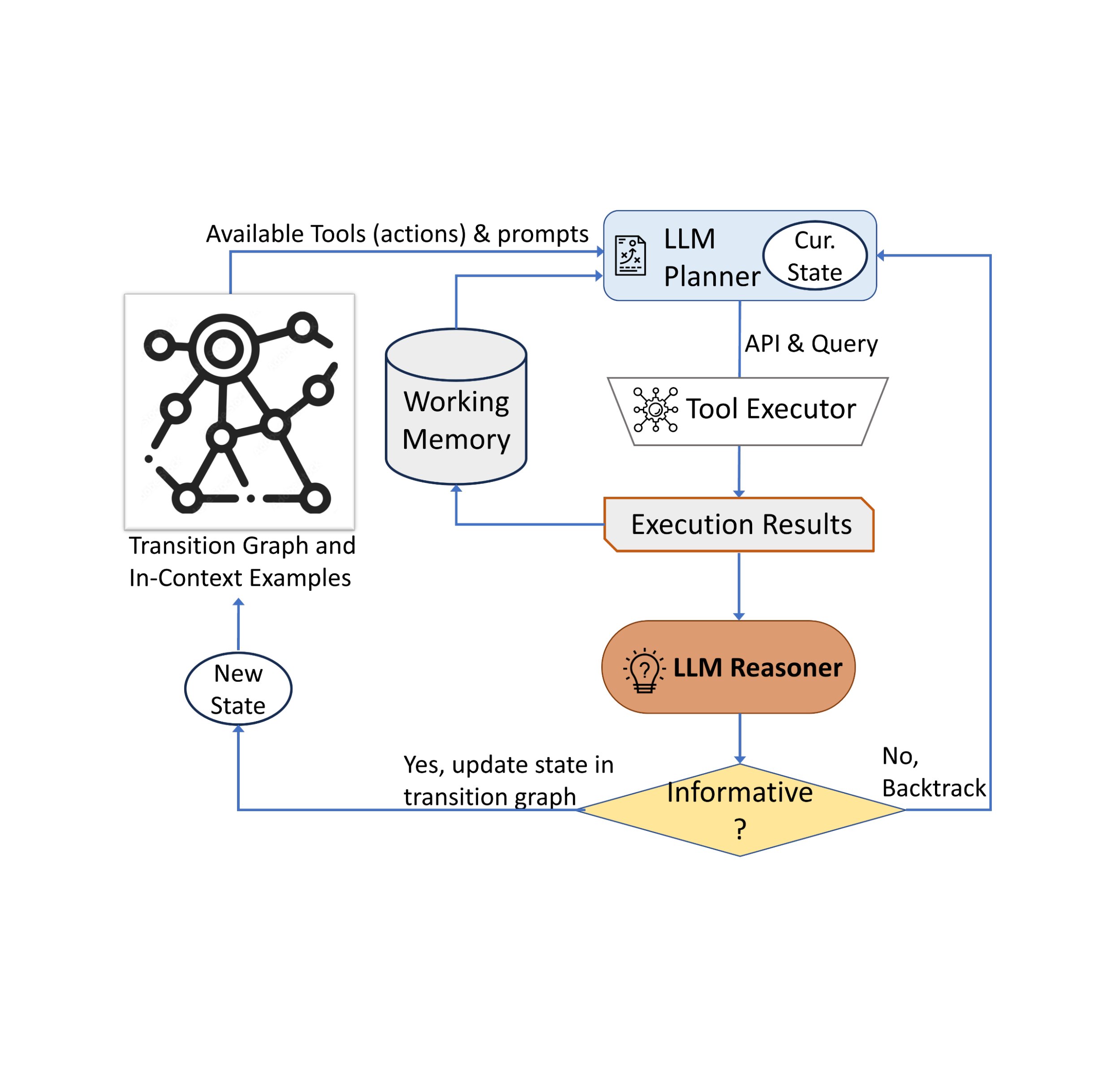
In “AVIS: Autonomous Visual Information Seeking with Large Language Models”, we introduce a novel method that achieves state-of-the-art results on visual information seeking tasks. Our method integrates LLMs with three types of tools: (i) computer vision tools for extracting visual information from images, (ii) a web search tool for retrieving open world knowledge and facts, and (iii) an image search tool to glean relevant information from metadata associated with visually similar images. AVIS employs an LLM-powered planner to choose tools and queries at each step. It also uses an LLM-powered reasoner to analyze tool outputs and extract key information. A working memory component retains information throughout the process.
 |
| An example of AVIS’s generated workflow for answering a challenging visual information seeking question. The input image is taken from the Infoseek dataset. |
Comparison to previous work
Recent studies (e.g., Chameleon, ViperGPT and MM-ReAct) explored adding tools to LLMs for multimodal inputs. These systems follow a two-stage process: planning (breaking down questions into structured programs or instructions) and execution (using tools to gather information). Despite success in basic tasks, this approach often falters in complex real-world scenarios.
There has also been a surge of interest in applying LLMs as autonomous agents (e.g., WebGPT and ReAct). These agents interact with their environment, adapt based on real-time feedback, and achieve goals. However, these methods do not restrict the tools that can be invoked at each stage, leading to an immense search space. Consequently, even the most advanced LLMs today can fall into infinite loops or propagate errors. AVIS tackles this via guided LLM use, influenced by human decisions from a user study.
Informing LLM decision making with a user study
Many of the visual questions in datasets such as Infoseek and OK-VQA pose a challenge even for humans, often requiring the assistance of various tools and APIs. An example question from the OK-VQA dataset is shown below. We conducted a user study to understand human decision-making when using external tools.
 |
| We conducted a user study to understand human decision-making when using external tools. Image is taken from the OK-VQA dataset. |
The users were equipped with an identical set of tools as our method, including PALI, PaLM, and web search. They received input images, questions, detected object crops, and buttons linked to image search results. These buttons offered diverse information about the detected object crops, such as knowledge graph entities, similar image captions, related product titles, and identical image captions.
We record user actions and outputs and use it as a guide for our system in two key ways. First, we construct a transition graph (shown below) by analyzing the sequence of decisions made by users. This graph defines distinct states and restricts the available set of actions at each state. For example, at the start state, the system can take only one of these three actions: PALI caption, PALI VQA, or object detection. Second, we use the examples of human decision-making to guide our planner and reasoner with relevant contextual instances to enhance the performance and effectiveness of our system.
 |
| AVIS transition graph. |
General framework
Our approach employs a dynamic decision-making strategy designed to respond to visual information-seeking queries. Our system has three primary components. First, we have a planner to determine the subsequent action, including the appropriate API call and the query it needs to process. Second, we have a working memory that retains information about the results obtained from API executions. Last, we have a reasoner, whose role is to process the outputs from the API calls. It determines whether the obtained information is sufficient to produce the final response, or if additional data retrieval is required.
The planner undertakes a series of steps each time a decision is required regarding which tool to employ and what query to send to it. Based on the present state, the planner provides a range of potential subsequent actions. The potential action space may be so large that it makes the search space intractable. To address this issue, the planner refers to the transition graph to eliminate irrelevant actions. The planner also excludes the actions that have already been taken before and are stored in the working memory.
Next, the planner collects a set of relevant in-context examples that are assembled from the decisions previously made by humans during the user study. With these examples and the working memory that holds data collected from past tool interactions, the planner formulates a prompt. The prompt is then sent to the LLM, which returns a structured answer, determining the next tool to be activated and the query to be dispatched to it. This design allows the planner to be invoked multiple times throughout the process, thereby facilitating dynamic decision-making that gradually leads to answering the input query.
We employ a reasoner to analyze the output of the tool execution, extract the useful information and decide into which category the tool output falls: informative, uninformative, or final answer. Our method utilizes the LLM with appropriate prompting and in-context examples to perform the reasoning. If the reasoner concludes that it’s ready to provide an answer, it will output the final response, thus concluding the task. If it determines that the tool output is uninformative, it will revert back to the planner to select another action based on the current state. If it finds the tool output to be useful, it will modify the state and transfer control back to the planner to make a new decision at the new state.
 |
| AVIS employs a dynamic decision-making strategy to respond to visual information-seeking queries. |
Results
We evaluate AVIS on Infoseek and OK-VQA datasets. As shown below, even robust visual-language models, such as OFA and PaLI, fail to yield high accuracy when fine-tuned on Infoseek. Our approach (AVIS), without fine-tuning, achieves 50.7% accuracy on the unseen entity split of this dataset.
 |
| AVIS visual question answering results on Infoseek dataset. AVIS achieves higher accuracy in comparison to previous baselines based on PaLI, PaLM and OFA. |
Our results on the OK-VQA dataset are shown below. AVIS with few-shot in-context examples achieves an accuracy of 60.2%, higher than most of the previous works. AVIS achieves lower but comparable accuracy in comparison to the PALI model fine-tuned on OK-VQA. This difference, compared to Infoseek where AVIS outperforms fine-tuned PALI, is due to the fact that most question-answer examples in OK-VQA rely on common sense knowledge rather than on fine-grained knowledge. Therefore, PaLI is able to encode such generic knowledge in the model parameters and doesn’t require external knowledge.
 |
| Visual question answering results on A-OKVQA. AVIS achieves higher accuracy in comparison to previous works that use few-shot or zero-shot learning, including Flamingo, PaLI and ViperGPT. AVIS also achieves higher accuracy than most of the previous works that are fine-tuned on OK-VQA dataset, including REVEAL, ReVIVE, KAT and KRISP, and achieves results that are close to the fine-tuned PaLI model. |
Conclusion
We present a novel approach that equips LLMs with the ability to use a variety of tools for answering knowledge-intensive visual questions. Our methodology, anchored in human decision-making data collected from a user study, employs a structured framework that uses an LLM-powered planner to dynamically decide on tool selection and query formation. An LLM-powered reasoner is tasked with processing and extracting key information from the output of the selected tool. Our method iteratively employs the planner and reasoner to leverage different tools until all necessary information required to answer the visual question is amassed.
Acknowledgements
This research was conducted by Ziniu Hu, Ahmet Iscen, Chen Sun, Kai-Wei Chang, Yizhou Sun, David A. Ross, Cordelia Schmid and Alireza Fathi.
Categories
Take a Free NVIDIA Technical Training Course
 Join the free NVIDIA Developer Program and enroll in a course from the NVIDIA Deep Learning Institute.
Join the free NVIDIA Developer Program and enroll in a course from the NVIDIA Deep Learning Institute.
Join the free NVIDIA Developer Program and enroll in a course from the NVIDIA Deep Learning Institute.
 Demand for real-time insights and autonomous decision-making is growing in various industries. To meet this demand, we need scalable edge-solution platforms…
Demand for real-time insights and autonomous decision-making is growing in various industries. To meet this demand, we need scalable edge-solution platforms…
Demand for real-time insights and autonomous decision-making is growing in various industries. To meet this demand, we need scalable edge-solution platforms that can effectively process AI-enabled sensor data right at the source and scale out to on-premises or cloud compute resources.
However, developers face many challenges in using AI and sensor processing at the edge:
- Real-time latency requirements
- The complexity of building and maintaining custom pipelines for AI-enabled sensor processing
- The need for hardware-agnostic solutions to meet heterogeneous hardware needs at the edge
- Multimodality and processing of various sensory modalities
- Integration from edge to on-premises to a cloud-distributed network
- Long-term whole-stack stability
Before NVIDIA Holoscan, no singular platform offered a comprehensive solution that effectively addressed the multitude of edge AI challenges. By seamlessly integrating data movement, accelerated computing, real-time visualization, and AI inferencing, Holoscan ensures optimal application performance. It abstracts away complexities for developers, reduces time to market, and offers the convenience of coding in Python and C++, all in a low-code, high-performance infrastructure.
“The Holoscan platform enables new SaMD (software as a medical device) to be quickly productized with seamless integration with the development environment to enable SaMD productization and fast-track deployment,” said Nhan Ngo Dinh, president of Cosmo Intelligent Medical Devices. “This accelerates the time to market with integrated development programmable using the NVIDIA Holoscan SDK, easy to transition from development to production.”
For edge developers, navigating the heterogeneous landscape of edge devices with varying hardware requirements and architectures can be daunting. Holoscan simplifies this complexity through its hardware-agnostic approach.
The platform provides a unified stack, accommodating a wide range of devices from x86 to aarch64 and NVIDIA Jetson Orin AGX to NVIDIA IGX Orin, catering to different power, size, cost, compute, and configuration needs. This versatility liberates you from hardware constraints while promoting interoperability, maintainability, and scalability across applications.
The v0.6 release of NVIDIA Holoscan introduces new features that empower you to reach new levels of scalability, productivity, and ease of use when building AI-streaming solutions. Specifically, this new set of features enables the following benefits:
- Scalability at the edge through a distributed computing architecture
- Portability, collaboration, and interoperability for platform development
- Advanced profiling with data frame flow tracking for optimal performance
Scalability through distributed computing architecture
For developers with heavy workloads or interested in scaling up and out, the Holoscan v0.6 multi-GPU, multi-node support enables distributed computing. Specifically, you can now deploy distributed applications and use all the resources available on the edge with multiple GPUs on a single node. Or you can deploy a single Holoscan application on separate physical nodes with optimized network communication.
Multi-GPU, multi-node enables sensor processing applications to scale with ever-increasing compute requirements and grants you more flexibility and scalability in your designs. For users, it opens new possibilities with increased processing power, parallel processing, separating workloads based on criticality, post-deployment scale-up without replacing existing units, fault tolerance, and reliability.
Portability, collaboration, and interoperability for platform developers
If you are developing a platform instead of creating standalone products from scratch, Holoscan v0.6 provides a set of new features enabling more scalability and flexibility for broader use and ease of integration:
- App packager: Grants portability through the easy containerization and deployment of the apps, enhancing collaboration and contributions to the platform.
- Multi-backend: Streamlines the transition from model training to AI app building enabled by the plug-and-play deployment of already trained PyTorch models.
- Holoviz volumetric rendering: Provides built-in volumetric rendering in support of medical imaging visualization.
Advanced profiling with data frame flow tracking
The upcoming release includes a data frame flow tracking feature that enables you to measure performance through data frame tracking so that you can quickly adjust bottlenecks. In addition, the new multithreaded scheduler enables applications to run operators in parallel. As a result, the applications have optimized the use of system resources.
Use cases and success stories
The NVIDIA Holoscan SDK has rapidly evolved into an accelerated, full-stack infrastructure, making significant contributions to scalable, software-defined, and real-time processing across various domains.
The following healthcare companies have embraced and built on this technology:
- Medtronic, the largest medical device company in the world, is building a next-generation AI-assisted colonoscopy system (pending FDA approval) on the Holoscan platform.
- Moon Surgical, a Paris-based robotic surgery company, is finalizing the productization of Maestro, an accessible, adaptive surgical-assistant robotics system built on Holoscan and IGX.
- ORSI Academy, a surgical training center in Belgium, has used Holoscan to support first-in-human real-world, robot-assisted surgery for critical operations like the removal of cancerous kidneys.
“Holoscan abstracts away the challenges in building safe and reliable sensor data processing pipelines for medical device applications. Traditionally such pipelines required dedicated teams of specialists to develop and maintain,” said David Noonan, CTO at Moon Surgical. Using Holoscan, we’re able to launch innovative features for our Maestro surgical robotics system with short development timelines while maintaining a lean R&D team.”
Other use cases include AR/VR, radar technology, and scientific instrumentation.
Magic Leap is working on a Holoscan-based solution that combines AI with true augmented reality to revolutionize physician and surgeon training, visualization, and complex procedure performance.
Researchers from the Georgia Tech Research Institute used Holoscan to develop a real-time radar application used in defense, aerospace, meteorology, navigation, and surveillance.
- NVIDIA and Analog Devices collaborated to build a 5G Instrumentation application that leverages Holoscan for compute-intensive signal processing at over 120 Gbps on the NVIDIA IGX platform.
- At Diamond Light Source, a world-renowned synchrotron in the UK, developers used Holoscan and Jax-based Holoscan operators to easily connect Holoscan to existing Ptychography software libraries to speed up image processing and reconstruction.
“With Holoscan, we’ve created an end-to-end data streaming pipeline that enables live ptychographic image processing at the I08-1 beam line, considerably enriching the overall user interaction,” said Paul Quinn, Imaging and Microscopy Science group leader, Diamond Light Source.
Get started with Holoscan 0.6
The release of NVIDIA Holoscan 0.6 marks a significant milestone in the development of edge AI solutions, offering unprecedented scalability, flexibility, and performance. With its diverse range of applications and success stories, Holoscan is shaping the future of AI-enabled sensor processing at the edge, opening new possibilities for various industries worldwide.
To get started developing, see the NVIDIA Holoscan SDK.
Modern neural networks have achieved impressive performance across a variety of applications, such as language, mathematical reasoning, and vision. However, these networks often use large architectures that require lots of computational resources. This can make it impractical to serve such models to users, especially in resource-constrained environments like wearables and smartphones. A widely used approach to mitigate the inference costs of pre-trained networks is to prune them by removing some of their weights, in a way that doesn’t significantly affect utility. In standard neural networks, each weight defines a connection between two neurons. So after weights are pruned, the input will propagate through a smaller set of connections and thus requires less computational resources.
 |
| Original network vs. a pruned network. |
Pruning methods can be applied at different stages of the network’s training process: post, during, or before training (i.e., immediately after weight initialization). In this post, we focus on the post-training setting: given a pre-trained network, how can we determine which weights should be pruned? One popular method is magnitude pruning, which removes weights with the smallest magnitude. While efficient, this method doesn’t directly consider the effect of removing weights on the network’s performance. Another popular paradigm is optimization-based pruning, which removes weights based on how much their removal impacts the loss function. Although conceptually appealing, most existing optimization-based approaches seem to face a serious tradeoff between performance and computational requirements. Methods that make crude approximations (e.g., assuming a diagonal Hessian matrix) can scale well, but have relatively low performance. On the other hand, while methods that make fewer approximations tend to perform better, they appear to be much less scalable.
In “Fast as CHITA: Neural Network Pruning with Combinatorial Optimization”, presented at ICML 2023, we describe how we developed an optimization-based approach for pruning pre-trained neural networks at scale. CHITA (which stands for “Combinatorial Hessian-free Iterative Thresholding Algorithm”) outperforms existing pruning methods in terms of scalability and performance tradeoffs, and it does so by leveraging advances from several fields, including high-dimensional statistics, combinatorial optimization, and neural network pruning. For example, CHITA can be 20x to 1000x faster than state-of-the-art methods for pruning ResNet and improves accuracy by over 10% in many settings.
Overview of contributions
CHITA has two notable technical improvements over popular methods:
- Efficient use of second-order information: Pruning methods that use second-order information (i.e., relating to second derivatives) achieve the state of the art in many settings. In the literature, this information is typically used by computing the Hessian matrix or its inverse, an operation that is very difficult to scale because the Hessian size is quadratic with respect to the number of weights. Through careful reformulation, CHITA uses second-order information without having to compute or store the Hessian matrix explicitly, thus allowing for more scalability.
- Combinatorial optimization: Popular optimization-based methods use a simple optimization technique that prunes weights in isolation, i.e., when deciding to prune a certain weight they don’t take into account whether other weights have been pruned. This could lead to pruning important weights because weights deemed unimportant in isolation may become important when other weights are pruned. CHITA avoids this issue by using a more advanced, combinatorial optimization algorithm that takes into account how pruning one weight impacts others.
In the sections below, we discuss CHITA’s pruning formulation and algorithms.
A computation-friendly pruning formulation
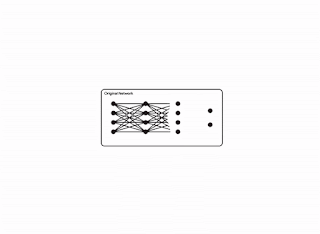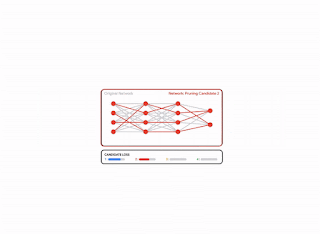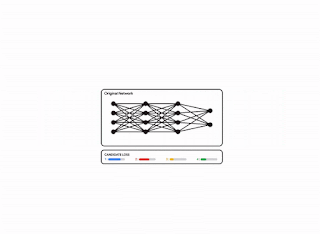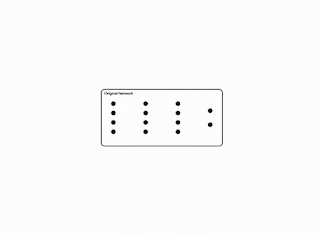
There are many possible pruning candidates, which are obtained by retaining only a subset of the weights from the original network. Let k be a user-specified parameter that denotes the number of weights to retain. Pruning can be naturally formulated as a best-subset selection (BSS) problem: among all possible pruning candidates (i.e., subsets of weights) with only k weights retained, the candidate that has the smallest loss is selected.
 |
| Pruning as a BSS problem: among all possible pruning candidates with the same total number of weights, the best candidate is defined as the one with the least loss. This illustration shows four candidates, but this number is generally much larger. |
Solving the pruning BSS problem on the original loss function is generally computationally intractable. Thus, similar to previous work, such as OBD and OBS, we approximate the loss with a quadratic function by using a second-order Taylor series, where the Hessian is estimated with the empirical Fisher information matrix. While gradients can be typically computed efficiently, computing and storing the Hessian matrix is prohibitively expensive due to its sheer size. In the literature, it is common to deal with this challenge by making restrictive assumptions on the Hessian (e.g., diagonal matrix) and also on the algorithm (e.g., pruning weights in isolation).
CHITA uses an efficient reformulation of the pruning problem (BSS using the quadratic loss) that avoids explicitly computing the Hessian matrix, while still using all the information from this matrix. This is made possible by exploiting the low-rank structure of the empirical Fisher information matrix. This reformulation can be viewed as a sparse linear regression problem, where each regression coefficient corresponds to a certain weight in the neural network. After obtaining a solution to this regression problem, coefficients set to zero will correspond to weights that should be pruned. Our regression data matrix is (n x p), where n is the batch (sub-sample) size and p is the number of weights in the original network. Typically n << p, so storing and operating with this data matrix is much more scalable than common pruning approaches that operate with the (p x p) Hessian.
 |
| CHITA reformulates the quadratic loss approximation, which requires an expensive Hessian matrix, as a linear regression (LR) problem. The LR’s data matrix is linear in p, which makes the reformulation more scalable than the original quadratic approximation. |
Scalable optimization algorithms
CHITA reduces pruning to a linear regression problem under the following sparsity constraint: at most k regression coefficients can be nonzero. To obtain a solution to this problem, we consider a modification of the well-known iterative hard thresholding (IHT) algorithm. IHT performs gradient descent where after each update the following post-processing step is performed: all regression coefficients outside the Top-k (i.e., the k coefficients with the largest magnitude) are set to zero. IHT typically delivers a good solution to the problem, and it does so iteratively exploring different pruning candidates and jointly optimizing over the weights.
Due to the scale of the problem, standard IHT with constant learning rate can suffer from very slow convergence. For faster convergence, we developed a new line-search method that exploits the problem structure to find a suitable learning rate, i.e., one that leads to a sufficiently large decrease in the loss. We also employed several computational schemes to improve CHITA’s efficiency and the quality of the second-order approximation, leading to an improved version that we call CHITA++.
Experiments
We compare CHITA’s run time and accuracy with several state-of-the-art pruning methods using different architectures, including ResNet and MobileNet.
Run time: CHITA is much more scalable than comparable methods that perform joint optimization (as opposed to pruning weights in isolation). For example, CHITA’s speed-up can reach over 1000x when pruning ResNet.
Post-pruning accuracy: Below, we compare the performance of CHITA and CHITA++ with magnitude pruning (MP), Woodfisher (WF), and Combinatorial Brain Surgeon (CBS), for pruning 70% of the model weights. Overall, we see good improvements from CHITA and CHITA++.
 |
| Post-pruning accuracy of various methods on ResNet20. Results are reported for pruning 70% of the model weights. |
 |
| Post-pruning accuracy of various methods on MobileNet. Results are reported for pruning 70% of the model weights. |
Next, we report results for pruning a larger network: ResNet50 (on this network, some of the methods listed in the ResNet20 figure couldn’t scale). Here we compare with magnitude pruning and M-FAC. The figure below shows that CHITA achieves better test accuracy for a wide range of sparsity levels.
 |
| Test accuracy of pruned networks, obtained using different methods. |
Conclusion, limitations, and future work
We presented CHITA, an optimization-based approach for pruning pre-trained neural networks. CHITA offers scalability and competitive performance by efficiently using second-order information and drawing on ideas from combinatorial optimization and high-dimensional statistics.
CHITA is designed for unstructured pruning in which any weight can be removed. In theory, unstructured pruning can significantly reduce computational requirements. However, realizing these reductions in practice requires special software (and possibly hardware) that support sparse computations. In contrast, structured pruning, which removes whole structures like neurons, may offer improvements that are easier to attain on general-purpose software and hardware. It would be interesting to extend CHITA to structured pruning.
Acknowledgements
This work is part of a research collaboration between Google and MIT. Thanks to Rahul Mazumder, Natalia Ponomareva, Wenyu Chen, Xiang Meng, Zhe Zhao, and Sergei Vassilvitskii for their help in preparing this post and the paper. Also thanks to John Guilyard for creating the graphics in this post.