The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level abstraction building blocks relevant to network applications through an SDK, runtime binaries, and high-level APIs that enable developers to rapidly create applications and services.
NVIDIA DOCA Flow is a newly updated set of software drivers and a steering library in the DOCA Framework. It runs in user space and enables offloading of networking-related operations from the CPU. This in turn enables applications to process high-packet throughput workloads with low latency, conserving CPU resources and reducing power usage.
DOCA Flow also efficiently optimizes the utilization of BlueField DPUs and ConnectX SmartNICs. DOCA is the key to unlocking the potential of BlueField’s acceleration engines, while DOCA Flow grants rapid access to the acceleration engine for packet-steering logic.
Simplify and expedite development
DOCA Flow offers C library APIs for defining hardware-based packet processing pipelines, abstracting the hardware capabilities of BlueField DPUs and ConnectX SmartNICs. This enables developers to construct high-performance and scalable applications for data center and cloud networks, programmatically defining and controlling network traffic flows, implementing network policies, and efficiently managing resources.
DOCA Flow complements and expands upon the core programming capabilities of DPDK, providing additional optimized features tailored specifically for NVIDIA DPUs and NICs. Further, DOCA Flow simplifies the complexities of the networking stack by offering building blocks for implementing basic packet processing pipelines for popular networking use cases, as well as for more sophisticated ones such as Longest Prefix Matching (LPM), Internet Protocol Security (IPsec) encryption or decryption, and creation or modification of entries in the Access Control List (ACL).
Using pre-created networking building blocks enables you to focus on creating your applications instead of writing low-level packet processing routines. This reduces TTM and frees you to focus on the core of your application, as the building blocks are already efficiently optimized for performance. DOCA Flow building blocks make software development easier, and can be used by developers of all experience levels.
Why DPUs are needed
Modern workloads and software-defined networking lead to significant networking overhead on CPU cores. Data centers and cloud networks now start at speeds of 25 or 100 Gbps and scale up to 200 and even 400 Gbps, requiring CPU cores to handle classification, tracking, processing, and steering of network traffic at immense speeds.
Compute virtualization amplifies networking requirements by generating more east/west traffic internally between host VMs and containers, and adding overlay network encapsulation plus microsegmentation to external communication with other servers or storage devices. As a result, much more networking demand is placed on the CPU.
CPU cores come with a significant cost and are not well-suited for efficient network packet processing. High-bandwidth tasks consume more CPU cores, placing unnecessary strain on the server’s valuable compute infrastructure, which could otherwise be utilized more productively for tenant workloads and application data processing.
In contrast, specialized hardware like SmartNICs and DPUs are specifically designed to efficiently handle fast data movement at scale, with reduced power consumption, heat, and overall cost compared to standard CPUs.
Execution pipes
The DOCA Flow library provides APIs that use hardware functions within the BlueField DPU and ConnectX SmartNICs to build generic and reusable execution pipes, where each pipe may consist of match criteria (packet classification) and a set of actions.
Classification enables identifying incoming packets to which logic should be applied, while actions vary and implement the logic that fits each packet’s classification. Using classifications and actions as building blocks provides a flexible method for developing hardware-accelerated network applications including gateways, firewalls, load-balancers, and others.
As mentioned, the actions in the DOCA Flow execution pipe vary and may include, as an example, packet manipulations such as applying Network Address Translation (NAT) logic on MAC addresses, changing source or destination IP addresses, applying overlay network encapsulation, changing header fields, incrementing a counter to measure traffic, and more. Actions may include monitoring traffic through the use of policies, forwarding traffic to different queues–either software queues or hairpin targets, port mirroring or packet sampling for debugging and lawful interception, and dropping packets to enforce policies or access control–all completely offloaded to the DPU or NIC hardware.
Pipes may be chained together through forwarding actions from one pipe to another to form a complete steering tree that defines paths for incoming packets. After executing a predefined action on a packet, the packet may be forwarded to another pipe for further action or inspection, to a software queue, to a hardware hairpin queue, or sent down the wire or dropped.
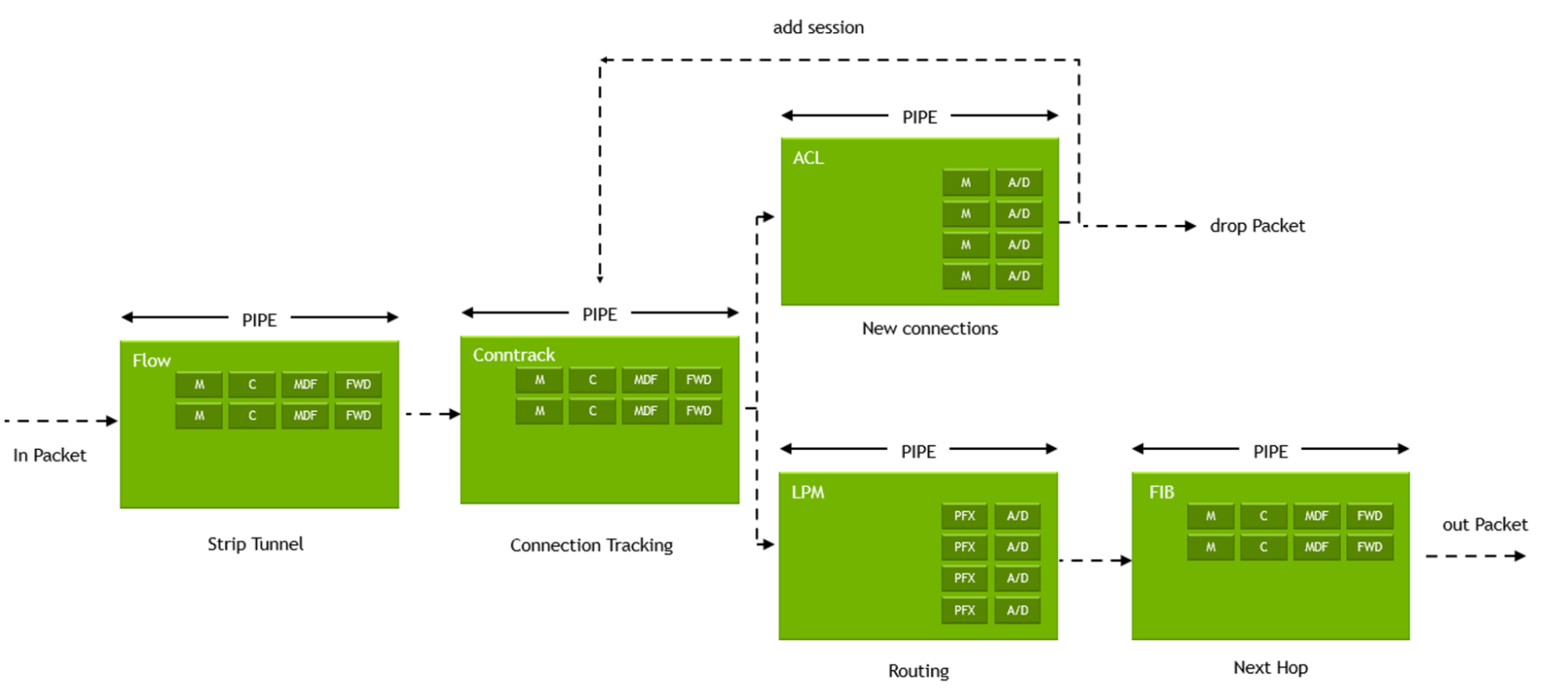
Steering trees
A steering tree can be used to create hardware-based network applications on a DPU or NIC by implementing common network function logic. This enables packets to be effectively categorized so the appropriate action can be applied to each one. Using the steering tree concept provides multiple benefits, including:
- Customized processing logic for each data flow
- Versatility in directing packets to specific actions or destinations
- Adaptable structure that’s easily resized for changing conditions
- Flexible framework that allows adding new pipe types to meet evolving requirements
- Optimized resource use, minimizing redundancy and enabling shared matches and actions
NVIDIA DOCA Flow use cases
When developing network pipelines for BlueField DPUs and ConnectX SmartNICs, DOCA Flow serves as a fundamental element in simplifying application development efforts. Use cases are applicable across enterprise data centers, telco, and cloud environments, particularly those that are focused on network infrastructure and security that require efficient packet processing.
Additionally, it is designed to handle scenarios involving establishing and removing pipelines at an extremely high rate, and can manage millions of packet exchanges per second. This accommodates software-defined networking applications, data analytics, virtual switching, AI inferencing, cybersecurity, and other packet processing applications. It enables operations like ingesting, examining headers and payloads, tracking connections, and inspecting, rerouting, copying, or dropping packets based on predetermined policies or other criteria.
Open vSwitch virtual switching
Open vSwitch (OVS) enables massive network automation through programmatic extension, and is designed to enable efficient network switching in virtualized environments such as virtual machines (VMs) and containers. Through DOCA Flow, a DPU-accelerated virtual switch (vSwitch) can be implemented in the user space data plane, allowing any server with a DPU to act as a network switch, router, or stateful load balancer.
This provides the flexibility of having a vSwitch available to multiple VNFs, while also significantly increasing small packet throughput and reducing latencies, thus expediting and accelerating communication through enhanced networking performance from the DPU and facilitating both north-south traffic for connecting to users, and east-west traffic for AI and distributed applications.
Next-generation firewall
Modern firewalls are required to inspect data at higher rates in order to combat new threats. However, with increased network speeds, more load is placed on the CPU. This can lead to increased latency, dropped packets, and reduced network throughput. To support higher speeds and more stringent security requirements without sacrificing latency is complex and deploying enough traditional firewalls capable of handling the increased traffic is cost-prohibitive.
DOCA Flow enables the development of an intelligent network filter for each server hosting a DPU. With this filter, the parsing and steering of traffic flows is based on predefined policies, with no CPU overhead. It can be used to create a distributed next-generation firewall (NGFW) that can achieve close to 100 Gbps throughput per server by using dedicated accelerators and Arm cores on the DPU to filter and forward packets based on their appropriate flow, as well as managing the data plane offloads and control plane of the NGFW.
Using DOCA Flow can provide a cost-effective solution to offload packet processing from the CPU to the DPU to increase performance and reduce costs beyond traditional hardware solutions. It offers advanced security features, like intrusion prevention, without sacrificing server performance. It also enables faster network flow inspection within the NIC/DPU.
Virtual network functions
DOCA Flow can accelerate virtualized network functions (VNFs), such as routers, load balancers, firewalls, content delivery network (CDN) services, and more. Telco vendors can replace proprietary hardware and execute virtualized workloads on commodity servers by developing VNFs that run on BlueField DPUs.
By using DPUs for VNF acceleration, a more efficient and flexible solution is achieved, leading to reduced equipment, space, heat, and power requirements compared with commodity servers. All this helps resolve limitations based on cooling and space constraints, enabling new opportunities with 5G, AI, IoT, and edge computing.
Edge applications
DOCA Flow is an ideal solution for edge workloads that require high network speeds and I/O processing capabilities, such as content delivery networks and video analytics systems. Host applications for the edge can be designed using DOCA Flow to run on DPUs installed within general-purpose servers, eliminating the need for expensive proprietary hardware appliances. By utilizing the DPUs acceleration and Arm cores, fewer server CPU cores are needed, allowing for smaller servers that consume less energy, require less cooling, and occupy less rack space. This approach offers cost savings in terms of both CapEx and OpEx.
Summary
The DOCA Flow library can be instrumental for developers by simplifying the development of modern applications that offer accelerated network throughput and latency improvements in packet processing. This is especially true for applications replacing proprietary bare-metal hardware solutions with virtualized applications hosted on commercial-off-the-shelf (COTS) server platforms.
The library consists of several building blocks for efficient networking offloads, including implementing basic packet processing pipelines, Longest Prefix Matching (LPM), and Internet Protocol Security (IPsec) encryption or decryption. Enhancements will be added soon to Connection Tracking (CT) and Access Control List (ACL) to create or modify access control entries. For a sampling of DOCA Flow reference applications, see the DOCA Reference Applications documentation.
By harnessing the capabilities of DOCA Flow, organizations can minimize cost, accelerate service deployment, and optimize hardware utilization within use cases that demand high throughput and low latency.
To learn more, explore the following resources:
 Delve into how TMA Solutions is accelerating original ML and AI workflows with RAPIDS.
Delve into how TMA Solutions is accelerating original ML and AI workflows with RAPIDS. The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…


 Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming…
Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming…