Automatic parking assist must overcome some unique challenges when perceiving obstacles. An ego vehicle contains sensors that perceive the environment around…
Automatic parking assist must overcome some unique challenges when perceiving obstacles. An ego vehicle contains sensors that perceive the environment around the vehicle. During parking, the ego vehicle must be close to dynamic obstacles like pedestrians and other vehicles, as well as static obstacles such as pillars and poles. To fit into the parking spot, it also may be required to navigate low obstacles such as wheel barriers and curbs.
NVIDIA DRIVE Labs videos take an engineering-focused look at autonomous vehicle challenges and how the NVIDIA DRIVE team is addressing them. The following video introduces early grid fusion (EGF) as a new technique that enhances near-field obstacle avoidance in automatic parking assist.
Video 1. NVIDIA DRIVE Labs Episode 29: Enhanced Obstacle Avoidance for Autonomous Parking in Tight Spaces
Existing parking obstacle perception solutions depend on either ultrasonic sensors or fisheye cameras. Ultrasonic sensors are mounted on the front and rear bumpers and typically don’t cover the flank. As a result, the system is unable to perceive the ego vehicle’s sides—especially for dynamic obstacles.
Fisheye cameras, on the other hand, suffer from degraded performance in low visibility, low light, and bad weather conditions.
The NVIDIA DRIVE platform is equipped with a suite of cameras, radar, and ultrasonic sensors to minimize unseen areas and maximize sensing redundancy for all operating conditions. EGF uses a machine-learned early fusion of multiple sensor inputs to provide an accurate, efficient, and robust near-field 3D obstacle perception.
Figure 1. EGF detecting parked cars as obstacles while parking with NVIDIA automatic parking assist
Early grid fusion overview
To better understand the innovative technique behind EGF, look at its DNN architecture and output/input representation.
Output: Height map representation
EGF outputs a height map with a grid resolution of 4 cm. Each pixel in the height map has a float value representing the height relative to the local ground.
In Figure 2, the green highlighted panel is the output of the EGF DNN. Light blue represents the ground. Yellow represents low obstacles, for example, the curb in the back. Bright red represents the outline of high obstacles, for example, the rounded L shape contours for parked cars and the dot for a tree behind the ego vehicle. The dark red area behind the bright red outlines represents potential occluded areas behind high obstacles.
Figure 2. EGF input and output visualization
This representation enables EGF to capture rich information about the world around it. The high-resolution grid can represent the rounded corner of cars on the rear left and right of the ego vehicle. Capturing the rounded corners is essential for the parking planner to have sufficient free space to perform the parking maneuver between two parked cars in a tight spot.
With different height values per pixel, you can distinguish between the curb for which the car has sufficient clearance and the light pole on the curb that the car must stay clear of.
Input: Ultrasonic and camera
Most multi-sensor fusion perception solutions are late-fusion systems operating on the detection level. Traditional ultrasonic detections obtained by trilateration are fused with polygon detections from the camera in a late-fusion stage, usually with hand-crafted fusion rules.
In contrast, EGF uses an early-fusion approach. Low-level signals from the sensor are directly fed to the DNN, which learns the sensor fusion through a data-driven approach.
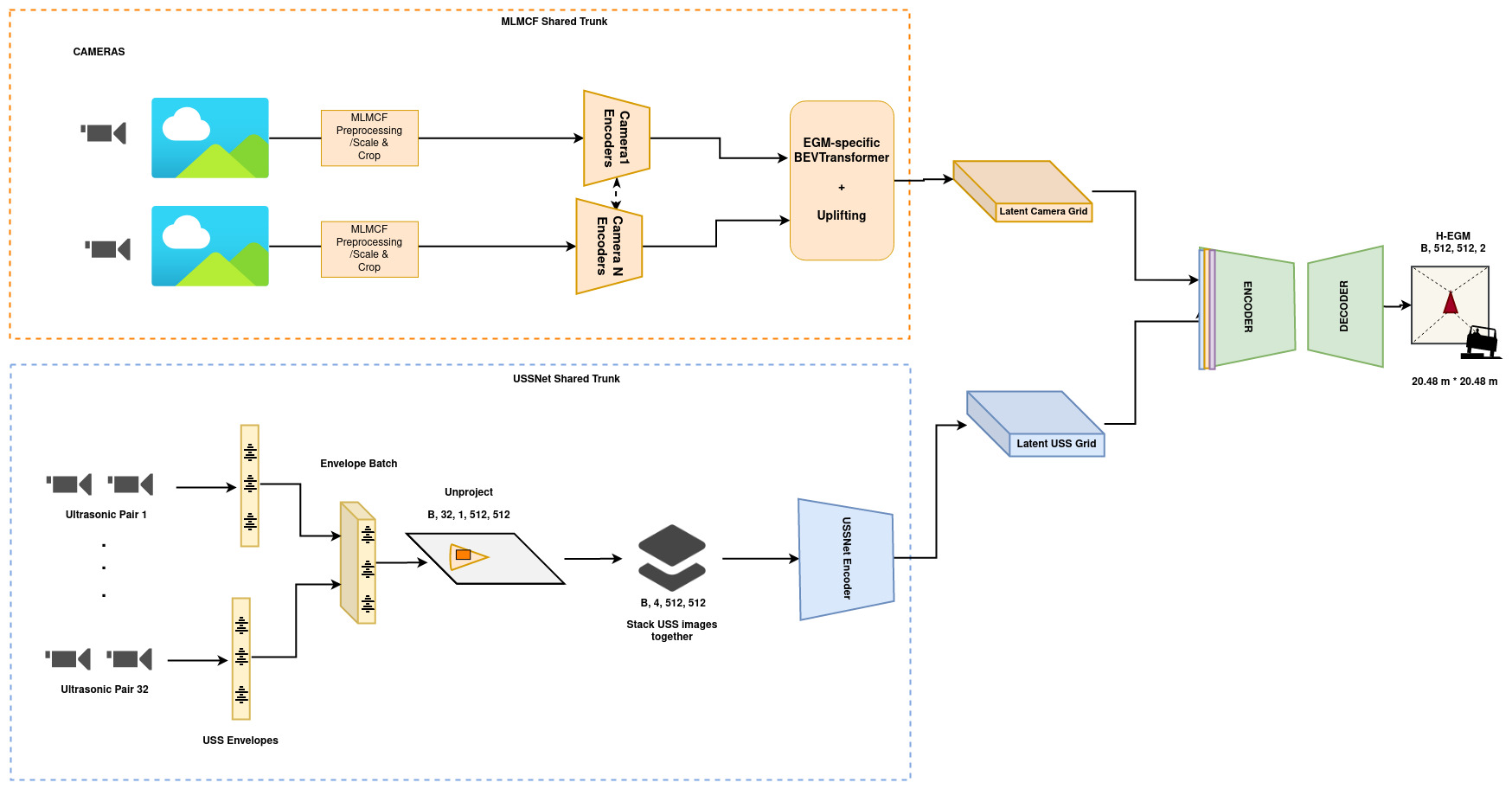
For ultrasonic sensors, EGF taps into the raw envelope interface that provides reflection intensity with sub-centimeter accuracy. These envelope signals are projected into a planar view map using the extrinsic position and intrinsic beam properties of the ultrasonic sensor (Figure 3 bottom left). These ultrasonic maps, as shown in the highlighted pink panel in Figure 2, capture much more information than trilateration detections. This enables height detection in EGF.
Figure 3. EGF DNN architecture
For camera sensors, EGF shares the image encoder backbone with MLMCF–NVIDIA multitask multi-camera perception backbone used for higher-speed driving. First, we process image features through CNN layers. Then, we perform uplifting of the features from an image space to a bird’s eye view space using a learned transform per camera (Figure 3 top-right box).
The ultrasonic and camera feature maps are then fused in an encoder network, and the height map is decoded from the combined features (Figure 3 right side).
Conclusion
EGF is an innovative, machine-learning–based, perception component to increase safety for autonomous parking. By using early fusion for multi-modality raw sensor signals, EGF builds a high level of trust for near-field obstacle avoidance.
So, you have a ton of data pipelines today and are considering investing in GPU acceleration through NVIDIA Base Command Platform. What steps should you take?…
So, you have a ton of data pipelines today and are considering investing in GPU acceleration through NVIDIA Base Command Platform. What steps should you take? Use workflow management to integrate NVIDIA Base Command into your existing pipeline.
A workflow manager enables you to easily manage your pipelines, and connect to Base Command to leverage NVIDIA compute power. This example uses Apache Airflow, which comes with a rich open-source community, is well established, and widely adopted.
What is workflow management and why is it important?
Workflow management enables you to connect and manage all tasks in a pipeline. It accomplishes this by creating, documenting, and monitoring all steps required to complete necessary tasks. It streamlines your workflow by making sure that everything is completed correctly and efficiently.
A business often has a BizOps team, MLOps team, and DevOps team working on various tasks to reach a given goal. For a simple workflow, many people complete various tasks, some are related or dependent upon each other, while others are completely independent. Workflow management can provide invaluable support for reaching the final outcome, particularly in complex situations.
To provide an analogy, imagine you are at your favorite sushi restaurant, and you place an order for your favorite roll. In the kitchen, there are several chefs working on various tasks to prepare your sushi. One is preparing the fish, the next is carefully slicing vegetables, the third is making the rice (cooking, washing, seasoning), and the fourth is toasting the nori over an open flame.
Only after each chef has completed their task can a master sushi chef assemble the roll. Here we see multiple roles with different expertise, required to accomplish various tasks in order to complete the end goal.
Figure 1. Example workflow to make a sushi roll
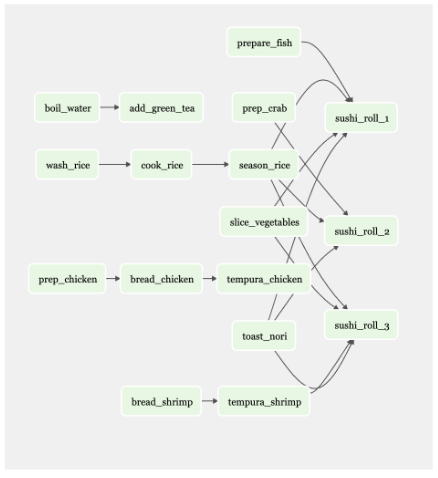
If the sushi restaurant offers 50 different menu items, there will be at least 50 different workflows. Figure 2 shows a workflow that includes just several menu items.
Figure 2. Example workflow for several menu items at a sushi restaurant
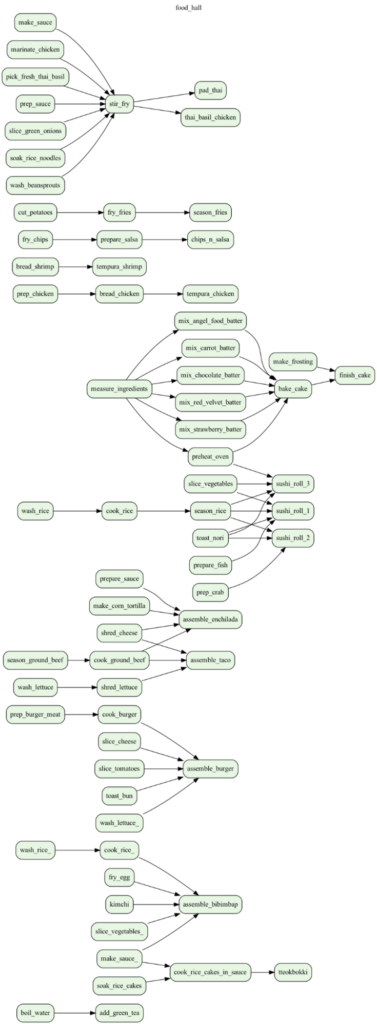
Now think of a food hall with 20 restaurants, each with their own menus and workflows.
Figure 3. Example workflow of several restaurants in a food hall
You can see how this situation becomes too much for a human to organize. Digital tools help organize and execute complex tasks—tools like Apache Airflow.
If you need to maintain current processes while also adding new steps, workflow management is key. Managing workflows is an established problem, and as AI adoption accelerates, it is clear that bringing AI tasks and outcomes into existing workflows becomes the next challenge.
Apache Airflow
What does it mean to include AI as part of a bigger workflow for deploying applications? In 2015, Airbnb had trouble managing their complex data pipelines, so they created Airflow. After doing market research, they found that most people were using cron schedulers or internal workflow tools. These tools were not very sophisticated, and did not anticipate future needs. They were “make it up as you go” kind of tools.
Airflow was made to be scalable and dynamic. It was open sourced in 2016 and became part of the Apache Foundation. This made Airflow increasingly popular and led to its rich open-source community.
NVIDIA Base Command Platform
NVIDIA Base Command Platform is an AI training platform that enables businesses and scientists to accelerate AI development. NVIDIA Base Command enables you to train AI with NVIDIA GPU acceleration. NVIDIA Base Command, in combination with NVIDIA-accelerated AI infrastructure, provides a cloud-hosted solution for AI development so you can avoid the overhead and pitfalls of deploying and running a do-it-yourself platform.
NVIDIA Base Command efficiently configures and manages AI workloads, delivers integrated dataset management, and executes them on right-sized resources ranging from a single GPU to large-scale, multi-node clusters.
Apache Airflow plus NVIDIA Base Command Platform
Having a tool like Apache Airflow schedule and run jobs, as well as monitor their progress, helps streamline the model training process. Additionally, once the model is trained and ready for production, you can use Airflow to get the results from Base Command Platform and use it in NVIDIA Fleet Command for production. Airflow reaches across platforms to make an end to end pipeline easier to operate. Adding AI with Base Command to a new or existing pipeline is made easier with a workflow management tool.
Key Airflow features for MLOPs
Airflow is a popular, well-established tool with a large user community. Many companies already use it, and abundant resources are available. It is open source and one of the first well-known workflow management tools. Cron schedulers have their place, but make it difficult to manage a pipeline when a job fails. Workflow tools (like Airflow) help resolve dependencies, when another job depends on the output of a failed task.
Workflow management tools have more features; for example, alerting team members if a task/job fails so that someone can fix it and rerun jobs. Applying workflow management tools can benefit many people in the workflow, including data engineers doing ETL jobs, data scientists doing model training jobs, analysts doing reporting jobs, and more.
Tasks and DAGs
Airflow uses Directed Acyclic Graphs (DAGs) to run a workflow. DAGs are built in Python. You set up your tasks and dependencies, and Airflow returns a graph depicting your workflow. Airflow triggers jobs to run once their dependencies have been fully met.
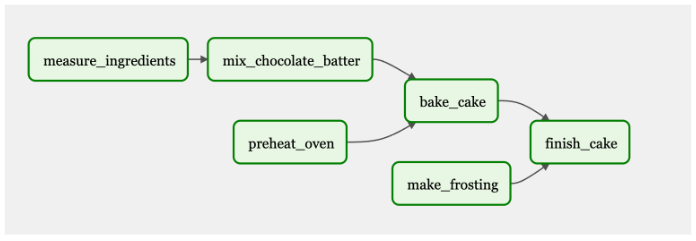
Figure 4 shows a DAG workflow to bake and frost a cake. Some of the tasks are dependent, such as measuring and mixing the ingredients, to bake the cake. Other tasks, such as ‘preheat oven,’ are necessary to complete the final goal: a frosted cake. Everything needs to be connected to complete the final product.
In this DAG, ‘measure ingredients,’ ‘preheat oven,’ and ‘make frosting’ would be triggered and executed first. When those tasks are completed, the next steps will be run in accordance to their dependencies.
Figure 4. DAG depicting workflow to bake a cake
Airflow UI
The Airflow UI is intuitive and easy to use. It can be used to trigger your DAGs, as well as monitor the progress of tasks and DAGs. You can also view logs, which can be used for troubleshooting.
Dynamic jobs
Dynamic jobs enable you to run the same job, while changing a few parameters. These jobs will run in parallel, and you are able to add variables instead of coding the same job with minor changes multiple times.
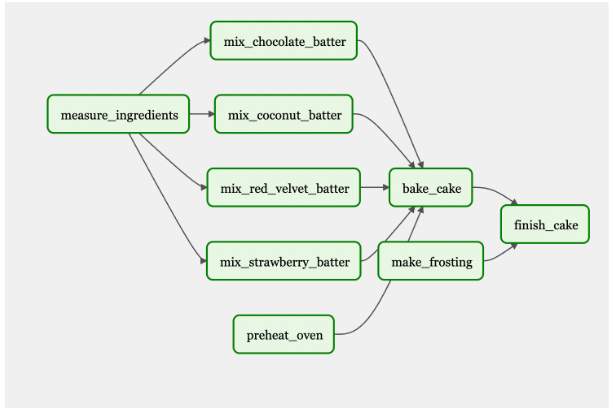
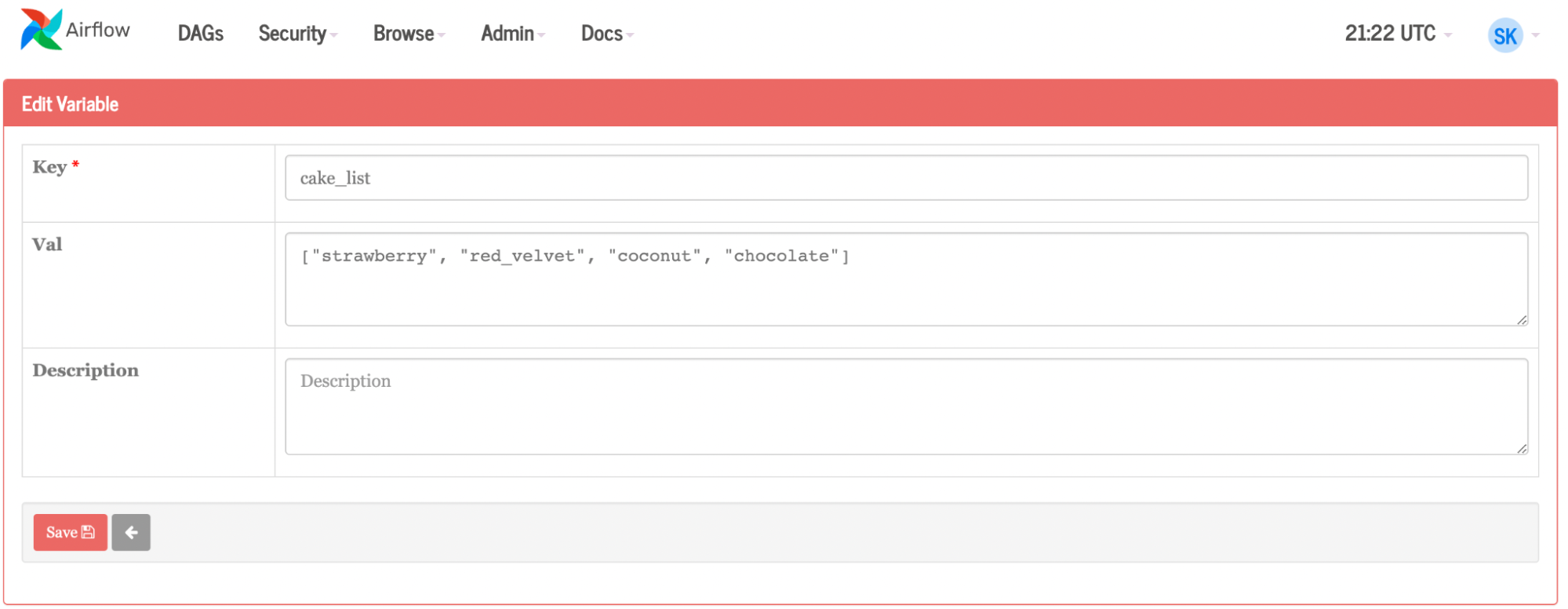
Continuing with the cake example, suppose you set out to make a single chocolate cake, but then decide to start a bakery. Instead of manually creating tasks for each separate cake, you can give Airflow a list of cakes: strawberry, coconut, and red velvet (Figure 5). You can do this through the UI or by uploading a JSON file. Airflow will dynamically create three more jobs to make three more cake flavors, instead of manually recreating the process for each new cake flavor. If someone is allergic to coconut, you can remove it from the list. Or you could have a flavor of the week and programmatically change the variables (cake flavors) weekly.
Figure 5. DAG depicting dynamic workflow to bake several different cakes
Figure 6. List of variables from Airflow UI used to dynamically create jobs
If you apply this approach to an ML pipeline, you can imagine all that can be accomplished. The updates can be programmatic and automated as part of a larger pipeline. Combined with a more complex Base Command job, such as running some framework and possibly only changing one simple variable or set of variables per container, then compare the results of all of the different job runs to make a decision.
Airflow could then be configured to kick off an additional multi-node training run based on the results, or the winning model could be uploaded to the private registry and further workloads or tasks could be integrated with Fleet Command to take it to production.
How to use Airflow
First, make sure you have a Kubernetes environment, with Helm installed. Helm is a package manager for Kubenetes used to find, share, and use software. If you are working from a Mac, Homebrew can help with installing Helm.
Generate Secret for UX
python3 -c 'import secrets; print(secrets.token_hex(16))'
helm show values apache-airflow/airflow > values.yaml
Open the file
When inside file, change: ‘webserverSecretKey: ’
helm upgrade --install airflow apache-airflow/airflow -n airflow -f values.yaml --debug
Airflow stores DAGs in a local file system. A more scalable and straightforward way to keep DAGs is in a GitHub repository. Airflow checks for new/updated DAGs in your file system, but using GitSync, Airflow looks at a GitHub repository which is easier to maintain and change.
Next, configure GitSync. When you add the key to your GitHub repository, be sure to enable write access.
ssh-keygen -t ed25519 -C “airflow-git-ssh”
When asked where to save, press enter
When asked for a passcode, press enter (do NOT put in a passcode, it will break)
Copy/Paste public key into private github repository
Repository > settings > deploy key > new key
kubectl create secret generic airflow-git-ssh
--from-file=gitSshKey=/Users/skropp/.ssh/id_ed25519
--from-file=known_hosts=/Users/skropp/.ssh/known_hosts
--from-file=id_ed25519.pub=/Users/skropp/.ssh/id_ed25519.pub
-n airflow
edit values.yaml (see below)
helm upgrade --install airflow apache-airflow/airflow -n airflow -f values.yaml —-debug
Original:
gitSync:
enabled: false
# git repo clone url
# ssh examples ssh://[email protected]/apache/airflow.git
# https example: https://github.com/apache/airflow.git
repo: https://github.com/apache/airflow.git
branch: v2-2-stable
rev: HEAD
depth: 1
# the number of consecutive failures allowed before aborting
maxFailures: 0
# subpath within the repo where dags are located
# should be "" if dags are at repo root
subPath: "tests/dags"
# if your repo needs a user name password
# you can load them to a k8s secret like the one below
# ___
# apiVersion: vI
# kind: Secret
# metadata:
# name: git-credentials
# data:
# GIT_SYNC_USERNAME:
# GIT_SYNC_PASSWORD:
# and specify the name of the secret below
# sshKeySecret: airflow-ssh-secret
With changes:
gitSync:
enabled: True
# git repo clone url
# ssh examples ssh://[email protected]/apache/airflow.git
# https example: https://github.com/apache/airflow.git
repo: ssh://[email protected]/sushi-sauce/airflow.git
branch: main
rev: HEAD
depth: 1
# the number of consecutive failures allowed before aborting
maxFailures: 0
# subpath within the repo where dags are located
# should be "" if dags are at repo root
subPath: ""
# if your repo needs a user name password
# you can load them to a k8s secret like the one below
# ___
# apiVersion: v1
# kind: Secret
# metadata:
# name: git-credentials
# data:
# GIT_SYNC_USERNAME:
# and specify the name of the secret below
credentialsSecret: git-credentials
# If you are using an ssh clone url, you can load
# the ssh private key to a k8s secret like the one below
# ___
# apiVersion: v1
# kind: Secret
# metadata:
# name: airflow-ssh-secret
# data:
# key needs to be gitSshKey
# gitSshKey:
# and specify the name of the secret below
sshKeySecret: airflow-git-ssh
Now you have Airflow running, and a place to store DAG files.
DAG examples
Below, find a simple example DAG, and one that is more complex.
Simple example DAG
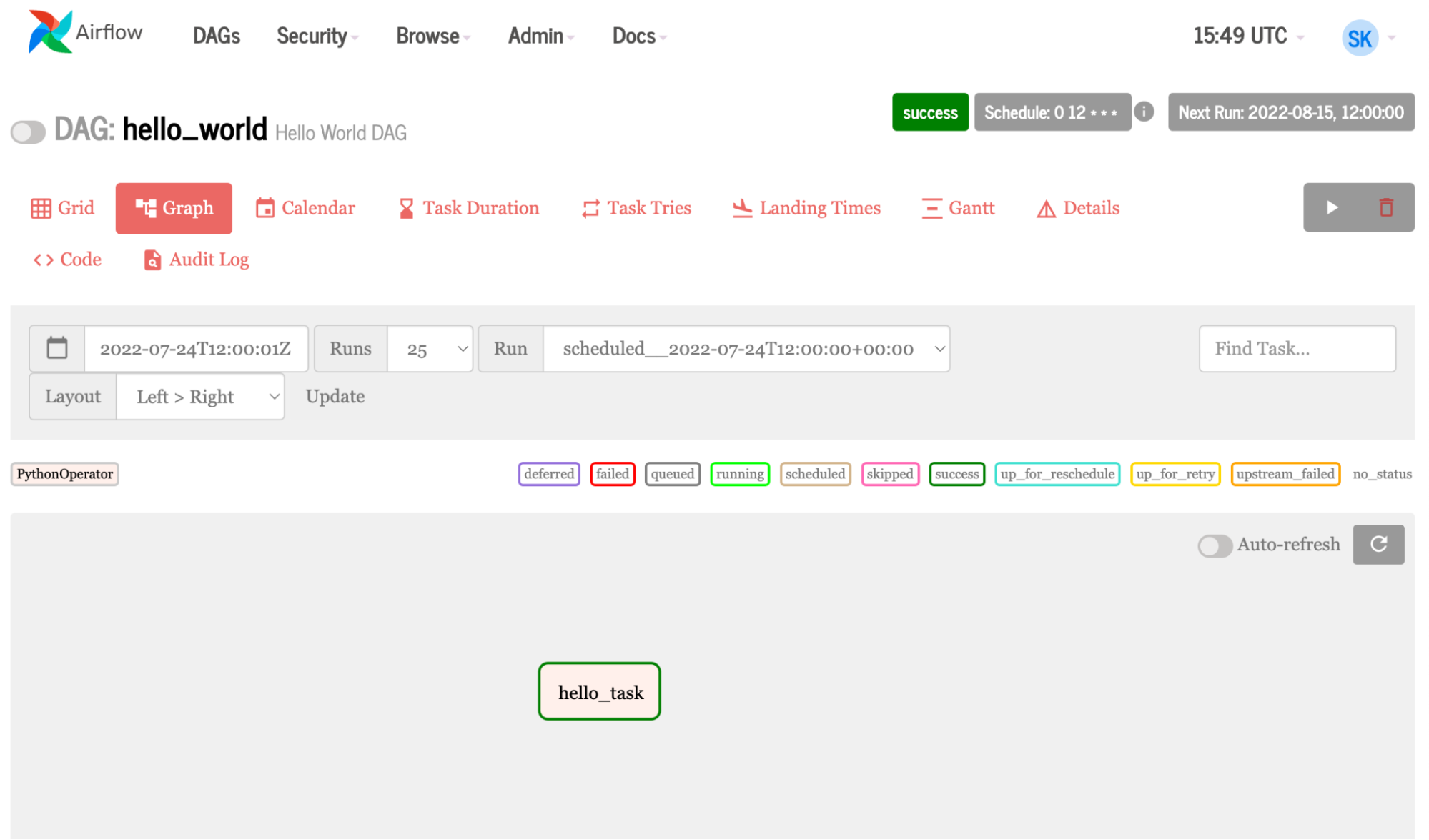
A very simple DAG is shown below:
Lines 1-3 import various tools and operators needed to run the tasks.
Lines 5-6 create a Python function that prints a message.
Lines 8-10 define the DAG, giving the display name hello_world and a description, as well as schedule interval and start date. Schedule interval and start date are required configurations.
Line 12 defines the task, task_id names the task, Python callable calls the function, dag=DAG brings in the configs set above.
1 from datetime import datetime
2 from airflow import DAG
3 from airflow.operators.python_operator import PythonOperator
4
5 def print_hello():
6 return 'Hello world from first Airflow DAG!'
7
8 dag = DAG('hello_world', description='Hello World DAG',
9 schedule interval='0 12 * * *',
10 start_date=datetime (2017, 3, 20), catchup=False)
11
12 hello_operator = PythonOperator (task_id-'hello_task', python_callable=print_hello, dag=dag)
13
14 hello_operator
Figure 7. Airflow graph generated from the simple example code
More complex example DAG
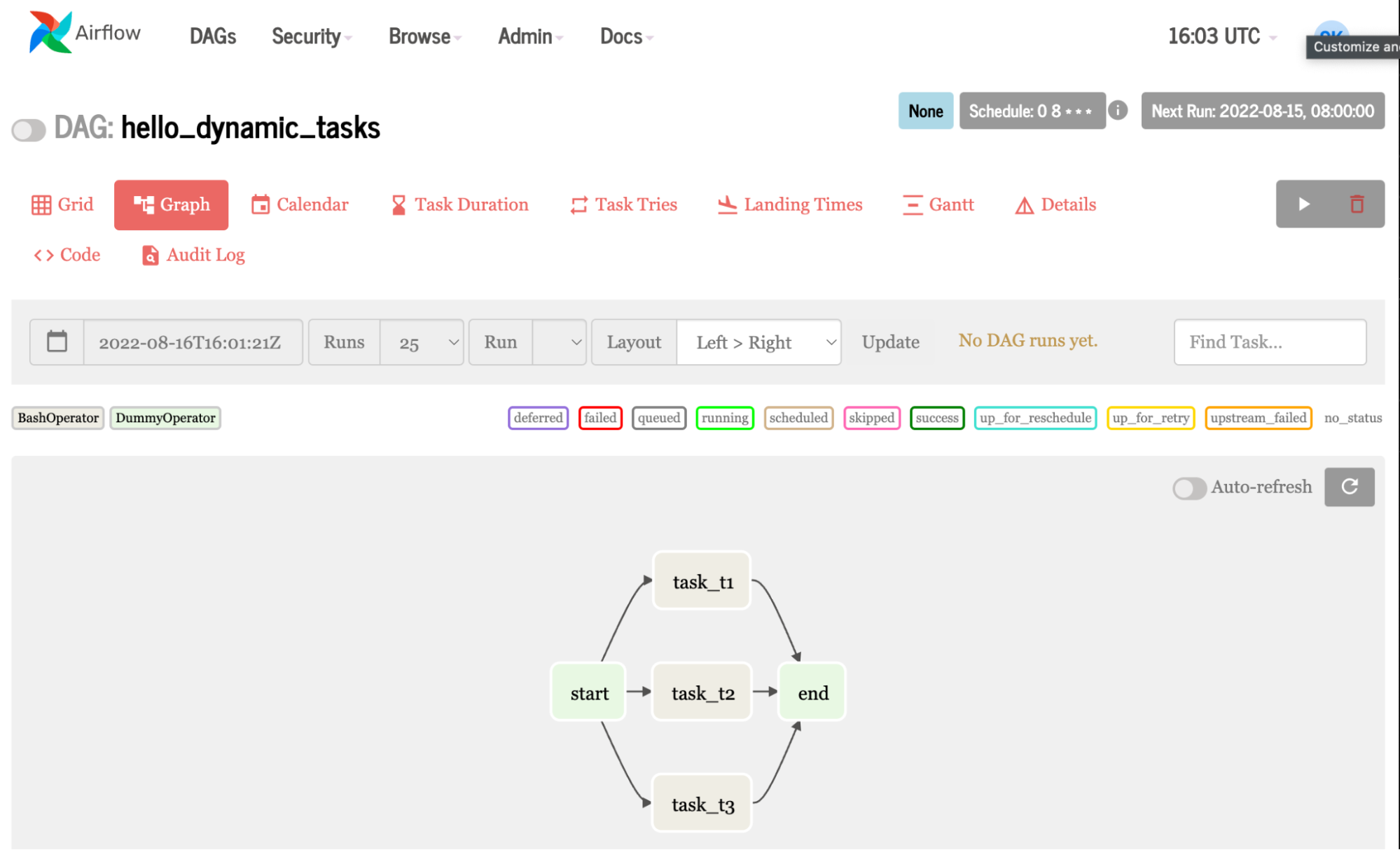
This example creates the same task three times, echoing hello from task 1, 2, and 3. It gets interesting when you use a list of variables instead of simply numbers in your loop. This means you can change pieces of your code to dynamically create different jobs.
1 from airflow import DAG
2 from airflow.operators.bash_operator import BashOperator
3 from airflow.operators. dummy_operator import DummyOperator
4 from datetime import datetime, timedelta
5
6 # Step 1 - Define the default arguments for DAG
7 default_args = {
8 'depends_on_past': False,
9 'start_date': datetime (2020, 12, 18),
10 'retry_delay': timedelta(minutes=5)
11 }
12
13 # Step 2 - Declare a DAG with default arguments
14 dag = DAG( 'hello_dynamic_tasks',
15 schedule_interval='0 8 * * *'
16 default_args=default_args,
17 catchup=False
18 )
19 # Step 3 - Declare dummy start and stop tasks
20 start_task = DummyOperator(task_id='start', dag=dag)
21 end_task = DummyOperator (task_id='end', dag=dag)
22
23 # Step 4 - Create dynamic tasks for a range of numbers
24 for 1 in range(1, 4):
25 # Step 4a - Declare the task
26 t1 = BashOperator (
27 task_id='task_t' + str(i),
28 bash _command='echo hello from task: '+str(i),
29 dag=dag
30 )
31 # Step 4b - Define the sequence of execution of tasks
32 start_task »> t1 >> end_task
While similar to the first example, this example uses the placeholder operator to create empty tasks, and a loop to create dynamic tasks.
Figure 8. Airflow graph generated from the more complex example code
Example DAG with NVIDIA Base Command
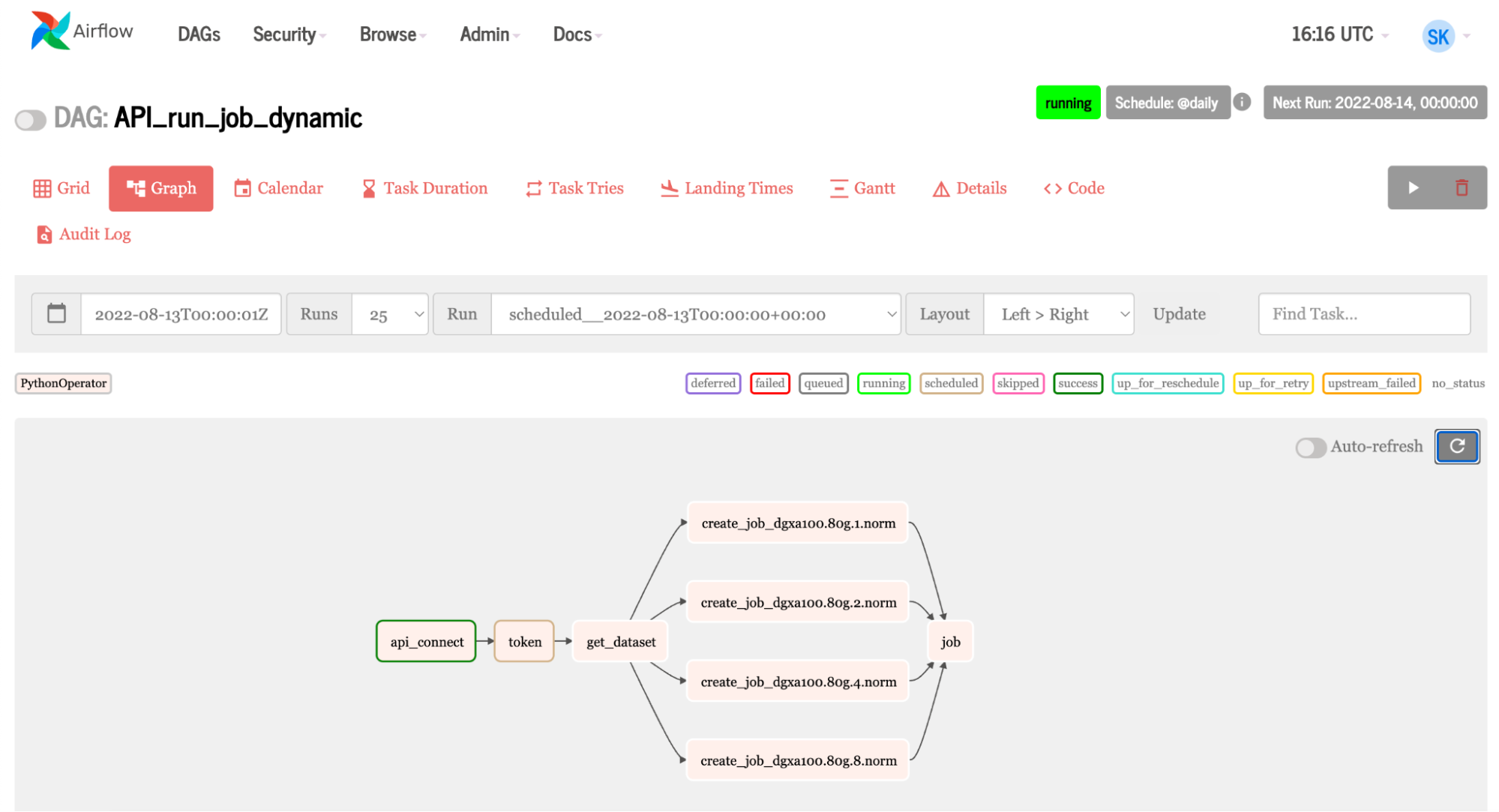
Airflow can leverage the Base Command API. Fleet Command uses the same API. This enables Airflow to use many NVIDIA AI platforms, making an accelerated AI pipeline easy to manage with Airflow. Let’s walk through some code from Airflow showing the tasks needed to connect to Base Command and run a job.
t1= PythonOperator(
task_id = 'api_connect'
python_callable= find_api_key,
dag = dag,
)
t2 = PythonOperator (
task_id = 'token',
python_callable = get_token,
op_kwargs=("org":org_, "team": team_),
dag = dag
)
t3 = PythonOperator (
task_id = 'get_dataset',
op kwargs=("org":org_),
python_callable = get_datasets,
dag = dag
)
t5 = PythonOperator(
task_id = 'job',
python_callable run_job,
dag = dag
)
for element in instance_v:
t4 = PythonOperator (
task_id = 'create_job_' + str(element),
op_kwargs={"org":org_. ,"team": team_, "ace": ace_, "name": name_, "command": command_ , "container": container_, "instance": str(element))},
python_callable=create_job,
dag = dag
)
t1 >> t2 >> t3 >> t4 >> t5
Key functions being used in the tasks include:
def find_api_key(ti):
expanded_conf_file_path = os.path.expanduser("~/.ngc/config")
if os.path.exists(expanded_conf_file_path):
print("Config file exists, pulling API key from it")
try:
config_file = open(expanded_conf_file_path, "r")
lines = config_file.readlines()
for line in lines:
if "apikey" in line:
elements = line.split()
return elements[-1]
except:
print("Failed to find the API key in config file")
return ''
elif os.environ.get('API_KEY'):
print("Using API_KEY environment variable")
return os.environ.get('API_KEY')
else:
print("Could not find a valid API key")
return ''
def get_token(ti, org,team ):
api = ti.xcom_pull(task_ids='api_connect')
'''Use the api key set environment variable to generate auth token'''
scope_list = []
scope = f'group/ngc:{org}'
scope_list.append(scope)
if team:
team_scope = f'group/ngc:{org}/{team}'
scope_list.append(team_scope)
querystring = {"service": "ngc", "scope": scope_list}
auth = '$oauthtoken:{0}'.format(api)
auth = base64.b64encode(auth.encode('utf-8')).decode('utf-8')
headers = {
'Authorization': f'Basic {auth}',
'Content-Type': 'application/json',
'Cache-Control': 'no-cache',
}
url = 'https://authn.nvidia.com/token'
response = requests.request("GET", url, headers=headers, params=querystring)
if response.status_code != 200:
raise Exception("HTTP Error %d: from %s" % (response.status_code, url))
return json.loads(response.text.encode('utf8'))["token"]
Task 1 finds your API key using a Python function defined in the DAG.
Task 2 gets a token; there are two very interesting things happening here:
To get a token, you need to give the API your key. Task 1 finds the key, but in Airflow, all the tasks are separate. (Note that I used the xcom feature in get_token to pull the results of Task 1 into Task 2. xcom pulls the API key found in the function find_api_key, into get_token to generate a token.)
The org and team arguments are Airflow variables. This means you can go into the Airflow UI and change the credentials depending on who is using it. This makes changing users clean and easy.
Task 3 gets the dataset needed for the job. Similarly, it uses the org variable defined in the Airflow UI.
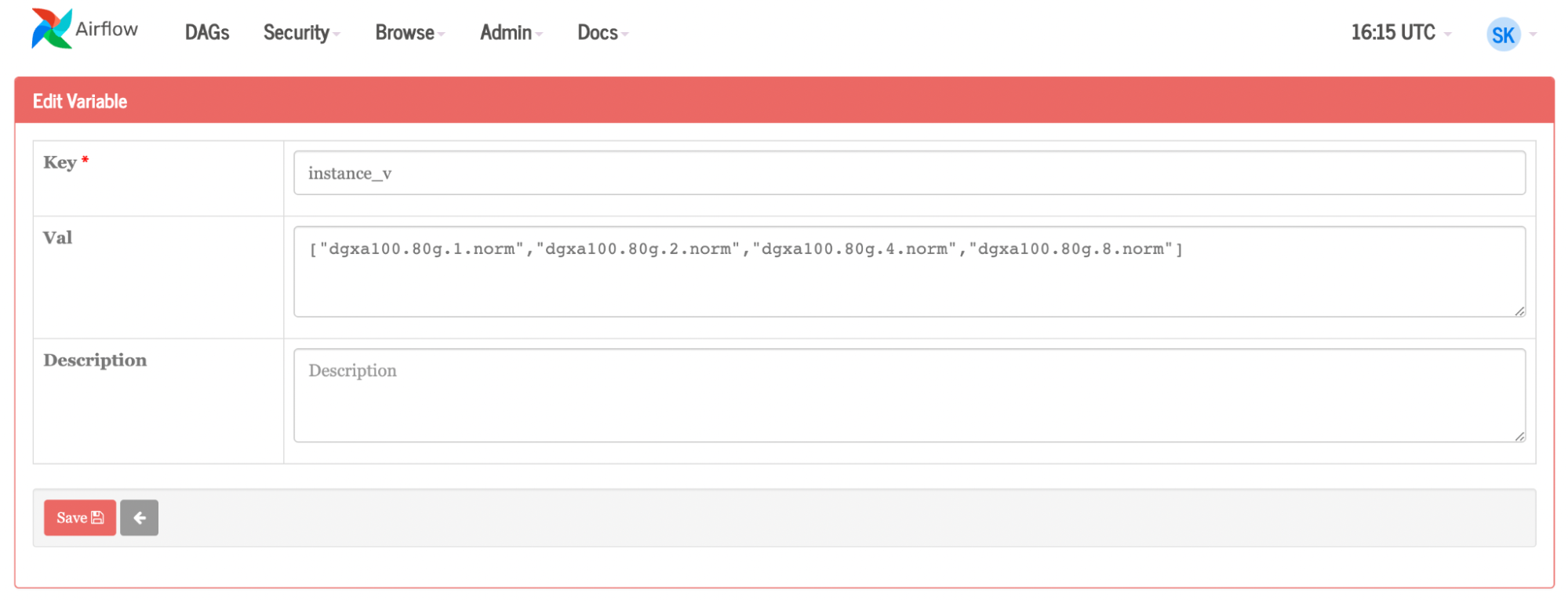
Task 4 is the main character. For each element in the list of instances, Airflow creates a job. Variables are also used for team, org, container, name, command, and instance. If you want to change any of these components, make the change on the variable page inside of Airflow.
Task 5 runs the job.
Figure 9. List of instances from Airflow UI, enabling you to run the job on one, two, four, and eight GPUs, respectivelyFigure 10. Graph showing dynamic job to Base Command Platform, where the same job is running on four different instances: one, two, four, and eight GPUs
Conclusion
Incorporating a workflow management tool such as Apache Airflow into your data pipelines is crucial for managing and executing complex tasks efficiently. With the rapid adoption of AI in various industries, the need to integrate AI tasks into existing workflows becomes increasingly important.
Integrating Airflow with an AI platform such as NVIDIA Base Command, which leverages GPU acceleration, streamlines the process of training and deploying AI models. The automation and flexibility of Airflow, combined with NVIDIA computing power through Base Command Platform, enable efficient experimentation, model comparison, and decision making within your ML pipeline.
A well-managed, faster workflow is the end product. Base Command Platform and Airflow together empower organizations to optimize data pipelines, enhance collaboration among different teams, and facilitate the integration of accelerated AI into existing workflows. This leads to quicker AI development and deployment that is more effective, scalable, and reliable.
A crack NVIDIA team of five machine learning experts spread across four continents won all three tasks in a hotly contested, prestigious competition to build state-of-the-art recommendation systems. The results reflect the group’s savvy applying the NVIDIA AI platform to real-world challenges for these engines of the digital economy. Recommenders serve up trillions of search Read article >
Startup MosaicML is on a mission to help the AI community improve prediction accuracy, decrease costs and save time by providing tools for easy training and deployment of large AI models. In this episode of NVIDIA’s AI Podcast, host Noah Kravitz speaks with MosaicML CEO and co-founder Naveen Rao about how the company aims to Read article >
This post is part of a series on accelerated data analytics. Visualization brings data to life, unveiling hidden patterns and insights through accessible…
Visualization brings data to life, unveiling hidden patterns and insights through accessible visuals, and empowering you and your organization to perceive the invisible, make informed decisions, and fully leverage your data.
Especially when working with large datasets, interaction can be difficult as render and compute times become prohibitive. Switching to RAPIDS libraries, such as cuDF, enables GPU acceleration that unlocks access to your data insights through a familiar pandas-like API. This post explains:
Why speed matters for visualization, especially for large datasets
How to use pandas-like features in RAPIDS for visualization
How to use hvPlot, datashader, cuxfilter, and Plotly Dash
Why speed matters for visualization
While data visuals are an effective tool for explaining data insights at the end of a project, they should ideally be used throughout the data exploration and enriching process. Visualization excels at enhancing data understanding by finding outliers, anomalies, and patterns not easily surfaced by purely analytical methods. This has been demonstrated by Anscombe’s quartet and the infamous Datasaurus Dozen.
An effective chart applies data visualization design principles that take advantage of pre-attentive visual processing. This style of visualization is essentially a hack for the brain to understand large amounts of information quickly. However, interactions such as filtering, selecting, or rerendering points that are slower than 7-10 seconds result in a disruption of a user’s short-term memory and train of thought. This disruption creates friction in the analysis process. To learn more, see Powers of 10: Time Scales in User Experience.
Combining sub-second speed with easy integration, the RAPIDS suite of open-source software libraries is ideal for supplementing exploratory data analysis (EDA) work with visualization–driving fluid, consistent insights that lead to better outcomes during analysis projects.
Large data analysis workflows require more compute power
Pandas has made data work simpler, helping to build a strong Python visualization ecosystem. For example, tools like Bokeh, Plotly, and Matplotlib have enabled more people to regularly use visuals for data analysis.
But when an EDA workflow is processing data larger than 2 GB, and requires compute intensive tasks, CPU-based solutions can start to constrain the iterative exploration process.
Accelerated data visualization with RAPIDS
Replacing CPU-based libraries with the pandas-like RAPIDS GPU-accelerated libraries (such as cuDF) means you can keep a swift pace for your EDA process as data sizes increase between 2 and 10 GB. Visualization compute and render times are brought down to interactive speeds, unblocking the discovery process. Moreover, as the RAPIDS libraries work seamlessly together, you can chart many types of data (time series, geospatial, graphs) with simple, familiar Python code to incorporate throughout your workflows.
RAPIDS Visualization Guide
The RAPIDS Visualization Guide on GitHub demonstrates the features and benefits of visualization libraries working together. Based on the publicly available Divvy bike share historical trip data, the notebook showcases how a visualization-focused approach to EDA can improve using the following GPU enabled libraries:
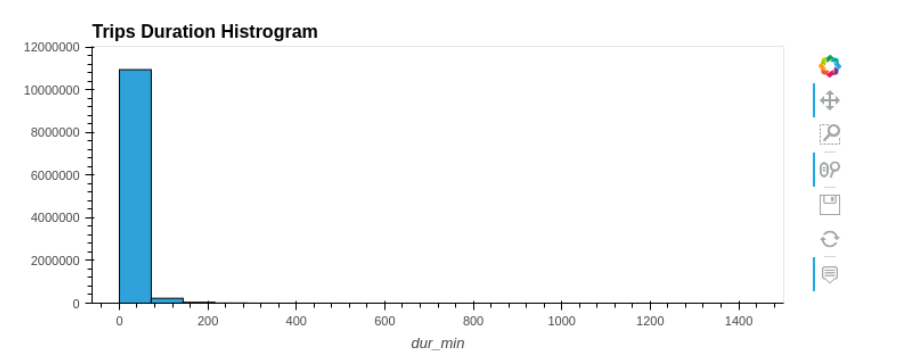
Figure 1. An hvPlot histogram of trip durations generated with the Divvy dataset
In this instance, the vast majority of bike trips appear under 20 minutes. Because of the ability to zoom in, you can also inspect the long tail of durations without creating another query. Augmenting the data using RAPIDS cuSpatial to quickly calculate distances also shows that most trips are relatively short.
Some hvPlot extras
Charts in hvPlot can be interactively displayed using Bokeh and Plotly extensions, or statically with the Matplotlib extension. Multiple charts can share axes by using the * operator, or in parallel for a basic layout with the + operator. More complicated dashboard layouts can be created with HoloViz Panel.
You can also automatically add simple widgets. For example, when using the built-in group by operation:
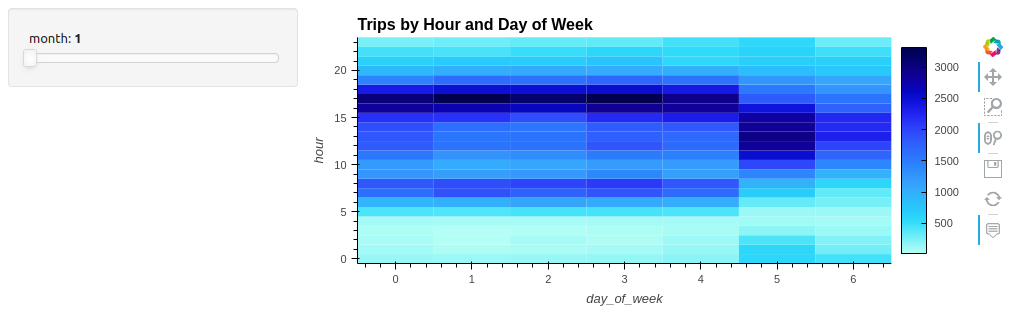
Figure 2. An hvPlot heat map showing trips by hour and day of week, per month
Adding a widget for interactivity enables scrubbing through the months to search for patterns over a full year (Figure 2). In visualization, “a slider is worth a thousand queries,” or in this case, 12.
Easy geospatial plotting
Geospatial charts with multiple options for the underlying tile maps can be shown by simply specifying geo=True:
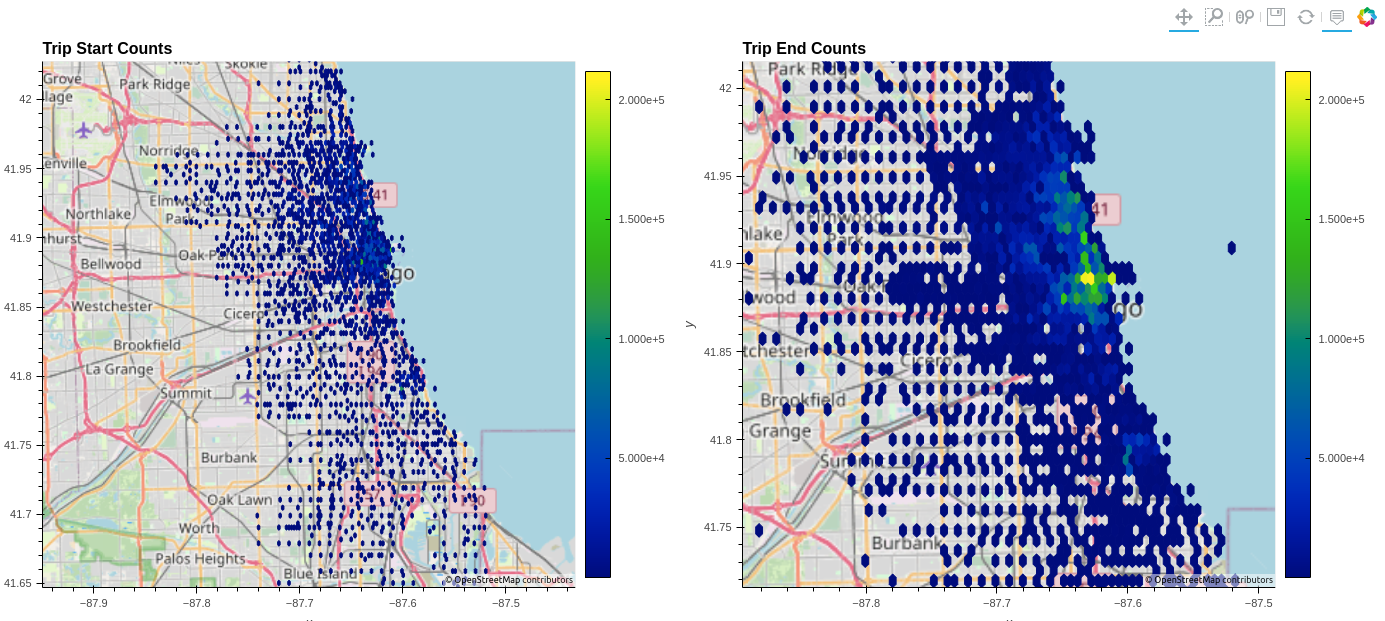
Figure 3. Two hexbinned geospatial plots for visualizing trip start and stop locations
Figure 3 shows the hexbin chart that aggregates trip start and ending locations to a manageable amount, verifying that the data is accurate to the bike share system map. Setting two charts side by side with the plus operator illustrates the radiating nature of the bike network.
Use Datashader for large data and high precision charts
The Datashader library directly supports cuDF and can rapidly render over millions of aggregated points. You can use it by itself to render a variety of precise and high-density chart types. It is also easy to use in conjunction with other libraries, like hvPlot, by specifying datashade=True:
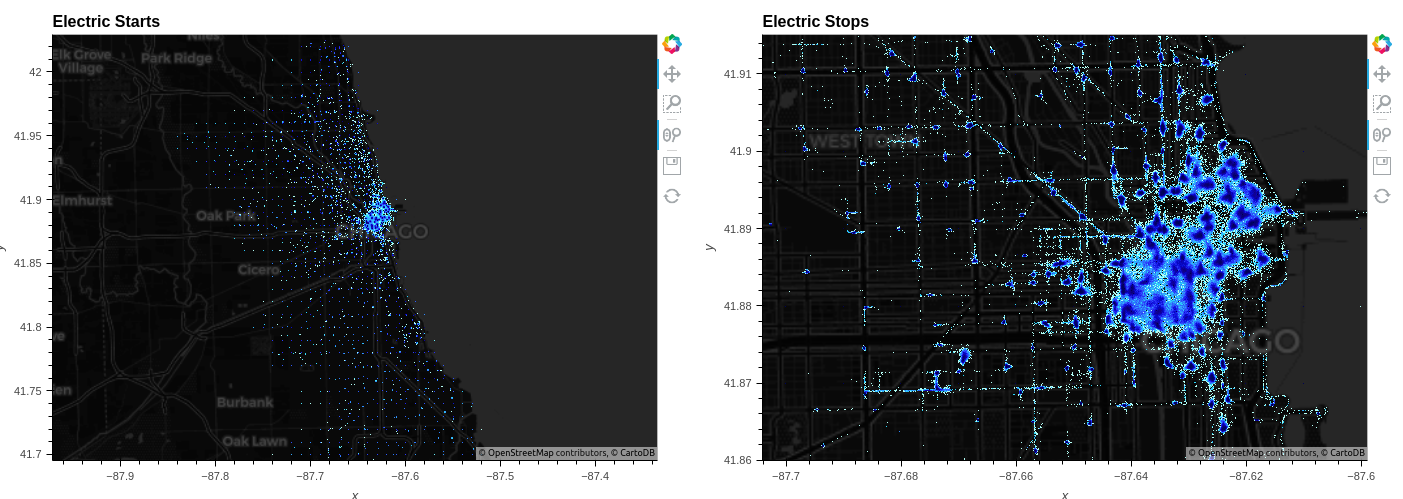
Figure 4. A Datashader visualization of 11 million individual electric bike start and stop locations
Datapoint rendering displaying high-resolution patterns is precisely what Datashader is designed for. In Figure 4, it clearly shows that while bikes tend to cluster, there is no guarantee that a bike will start or end a trip at a designated station.
Use cuxfilter for accelerated cross-filtered dashboards
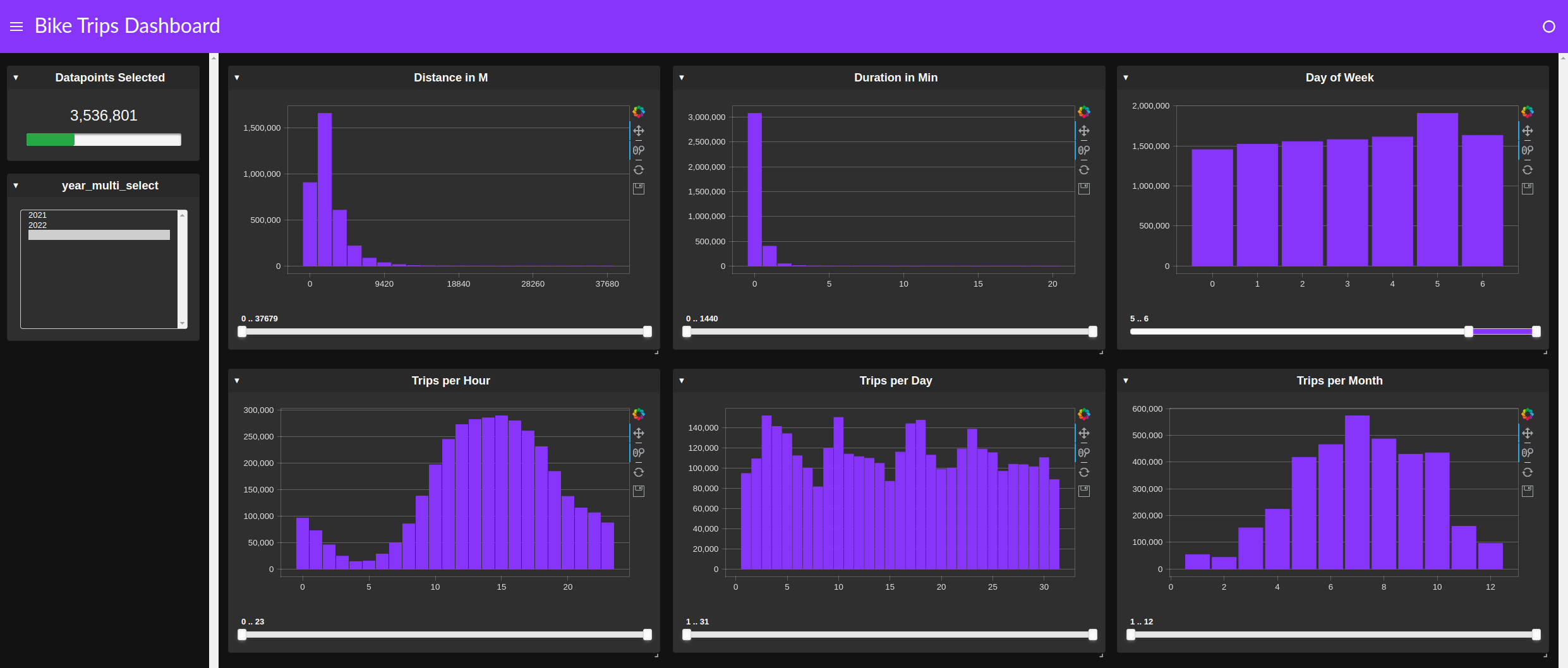
Instead of creating several individual group by and query operations, a cuxfilter dashboard can simply cross-link numerous charts to quickly find patterns or anomalies (Figure 5).
A few lines of code is all it takes to get a dashboard up and running:
cux_df = cuxfilter.DataFrame.from_dataframe(df)
# Specify charts
charts = [
cuxfilter.charts.bar('dist_m', data_points=20 , title='Distance in M'),
cuxfilter.charts.bar('dur_min', data_points=20 , title='Duration in Min'),
cuxfilter.charts.bar('day_of_week', title='Day of Week'),
cuxfilter.charts.bar('hour', title='Trips per Hour'),
cuxfilter.charts.bar('day', title='Trips per Day'),
cuxfilter.charts.bar('month', title='Trips per Month')
]
# Specify side panel widgets
widgets = [
cuxfilter.charts.multi_select('year')
]
# Generate the dashboard and select a layout
d = cux_df.dashboard(charts, sidebar=widgets, layout=cuxfilter.layouts.two_by_three, theme=cuxfilter.themes.rapids, title='Bike Trips Dashboard')
# Update the yaxis ticker to an easily readable format
for i in charts:
if hasattr(i.chart, 'yaxis'):
i.chart.yaxis.formatter = NumeralTickFormatter(format="0,0")
# Show generates a full dashboard in another browser tab
d.show()
Figure 5. cuxfilter Cross Filter Dashboard for identifying patterns and anomalies
Using cuxfilter for quick, cross-filter-based exploration is another technique that can save time. This approach replaces dataframe queries with a GUI tool. As shown in Figure 5, a clear pattern emerges between weekday and weekend trips, as well as between daytime and evening.
Build powerful analytics applications with Plotly Dash
After data is properly formatted and augmented by an EDA process, making it more widely accessible and digestible for your organization can be a challenge. Plotly Dash enables data scientists to recast complex data and machine learning workflows as more accessible web applications.
For that reason, the findings from this notebook are encapsulated into a simple-to-use, accessible, and deployable app with Plotly Dash. The app uses the powerful analysis capabilities available with RAPIDS, but is controlled through an uncomplicated GUI.
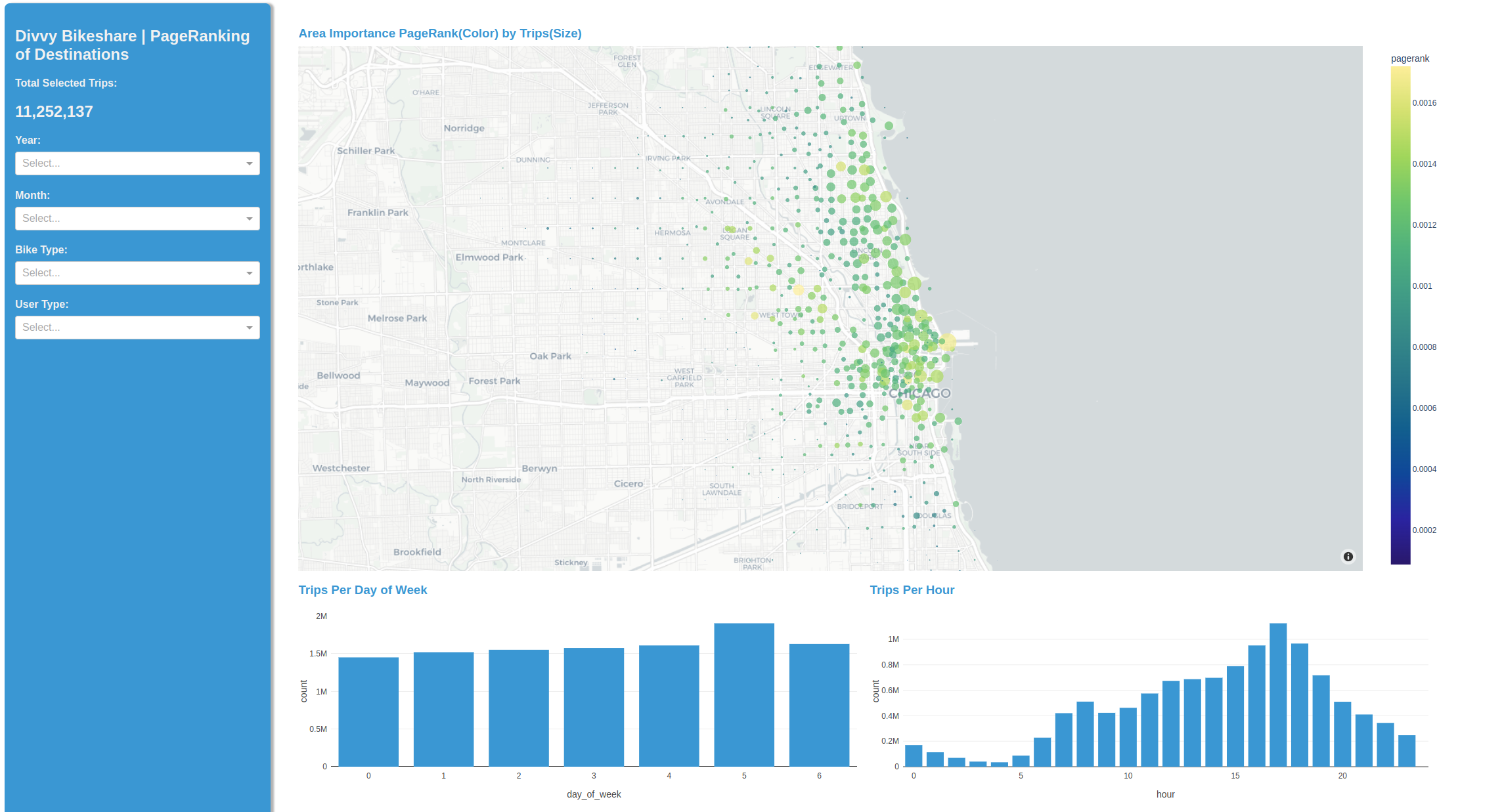
Figure 6. Plotly Dash visualizing bikeshare destinations with PageRank
This instance uses cuML K-means to cluster the bike start and stop points into nodes and show each node’s relative importance with cuGraph’s PageRank. The latter is computed in real time for each of the weekend-weekday, and day-night patterns discovered earlier. We have started with raw usage patterns and now provide interactive insights into specific user-types and their preferred areas of town.
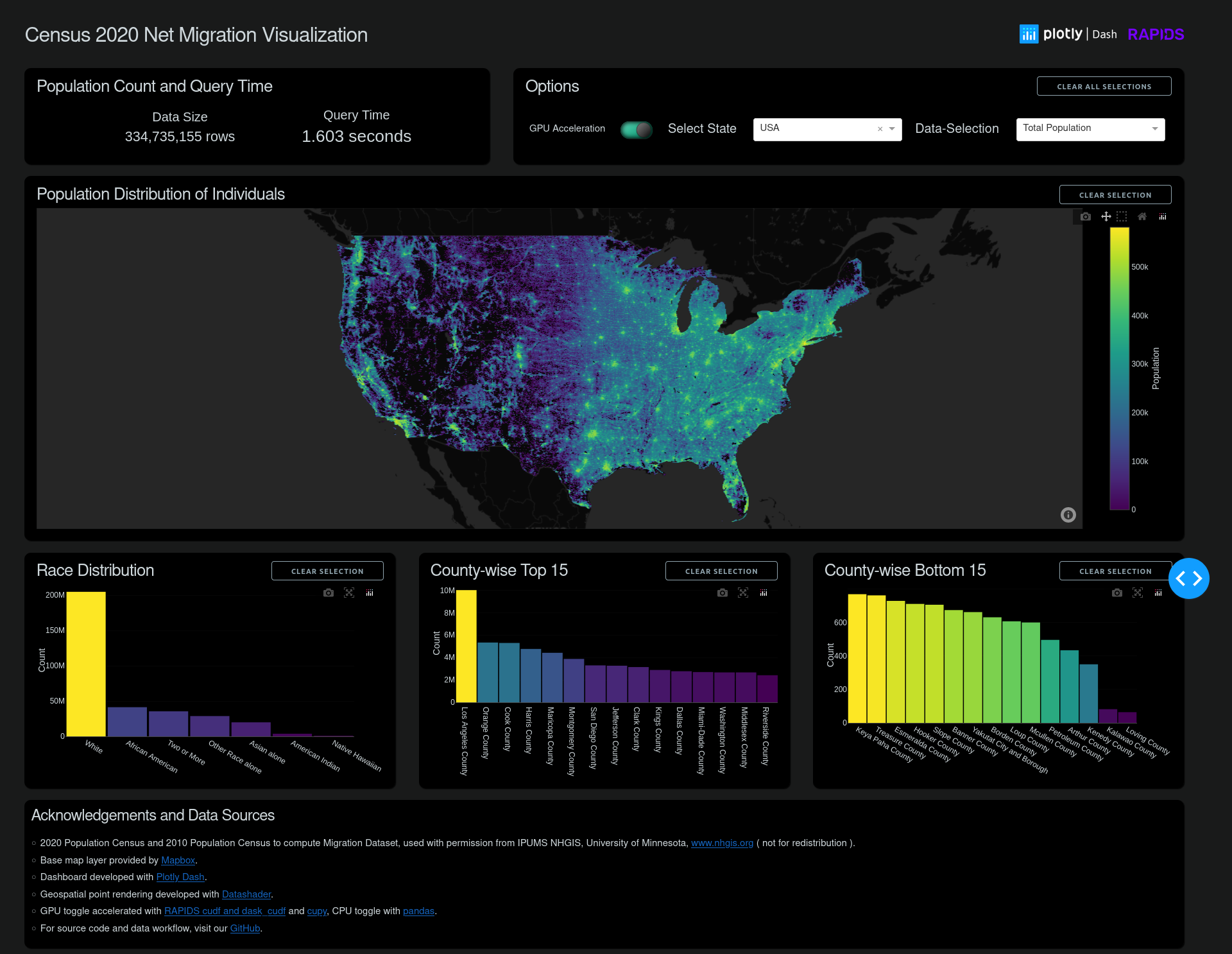
Subsecond interaction of 300M+ Census data points with Plotly Dash
The 2020 and 2010 Census data were sourced with permission from IPUMS NHGIS, University of Minnesota. To more accurately represent the entire US population visually, the block-level data were expanded into per-individual points randomly placed within their block region, and calculated to match a block-level distribution. Several views are tabulated for that data, including total population and net migration values. For more details about formatting the data, see Plotly-Dash + RAPIDS Census 2020 Visualization GitHub page..
Using a powerful visualization, you can forget about the tool and become immersed in exploring the data. Some intriguing patterns emerge in this case:
The Census block boundaries were changed, resulting in large roadways with their own separate blocks. This might be a result of a new push to better reflect unhoused populations.
The eastern states show much less overall migration than the midwest and western states, except for a few hot spots.
New developments, especially large ones, are particularly easy to spot and can serve as a quick visual comparison between regional policies affecting growth, land use, and population densities.
Data visualization at the speed of thought
By replacing pandas with RAPIDS frameworks such as cuDF, and taking advantage of the simplicity to integrate accelerated visualization frameworks, data analytics workflows can become faster, more insightful, more productive, and (just maybe) more enjoyable.
To learn more about speeding up your data science workflows, check out these resources:
This post is part of a series on accelerated data analytics. If you are looking to take your machine learning (ML) projects to new levels of speed and…
If you are looking to take your machine learning (ML) projects to new levels of speed and scalability, GPU-accelerated data analytics can help you deliver insights quickly with breakthrough performance. From faster computation to efficient model training, GPUs bring many benefits to everyday ML tasks.
This post provides technical best practices for:
Accelerating basic ML techniques, such as classification, clustering, and regression
Preprocessing time series data and training ML models efficiently with RAPIDS, a suite of open-source libraries for executing data science and analytics pipelines entirely on GPUs
Understanding algorithm performance and which evaluation metrics to use for each ML task
Accelerating data science pipelines with GPUs
GPU-accelerated data analytics is made possible with RAPIDS cuDF, a GPU DataFrame library, and RAPIDS cuML, a GPU-accelerated ML library.
cuDF is a Python GPU DataFrame library built on the Apache Arrow columnar memory format for loading, joining, aggregating, filtering, and manipulating data. It has an API similar to pandas, an open-source software library built on top of Python specifically for data manipulation and analysis. This makes it a useful tool for data analytics workflows, including data preprocessing and exploratory tasks to prepare dataframes for ML. For more information on how you can accelerate your data analytics pipeline with cuDF, refer to the series on accelerated data analytics.
Once your data is preprocessed, cuDF seamlessly integrates with cuML, which leverages GPU acceleration to provide a large set of ML algorithms that can help execute complex ML tasks at scale, much faster than CPU-based frameworks like scikit-learn.
cuML provides a straightforward API closely mirroring the scikit-learn API, making it easy to integrate into existing ML projects. With cuDF and cuML, data scientists and data analysts working on ML projects get the easy interactivity of the most popular open-source data science tools with the power of GPU acceleration across the data pipeline. This minimizes adoption time to pushing ML workflows forward.
Note: This resource serves as an introduction to ML with cuML and cuDF, demonstrating common algorithms for learning purposes. It’s not intended as a definitive guide for feature engineering or model building. Each ML scenario is unique and might require custom techniques. Always consider your problem specifics when building ML models.
Understanding the Meteonet dataset
Before diving into the analysis, it is important to understand the structure and content of the Meteonet dataset, which is well-suited for time series analysis. This dataset is a comprehensive collection of weather data that is immensely beneficial for researchers and data scientists in meteorology.
An overview of the Meteonet dataset and the meaning of each column is provided below:
number_sta: A unique identifier for each weather station.
lat and lon: Latitude and longitude of the weather station, representing its geographical location.
height_sta: Height of the weather station above sea level in meters.
date: Date and time of data recording, essential for time series analysis.
dd: Wind direction in degrees, indicating the direction from which the wind is coming.
ff: Wind speed, measured in meters per second.
precip: Amount of precipitation measured in millimeters.
hu: Humidity, represented as a percentage indicating the concentration of water vapor in the air.
td: Dew point temperature in degrees Celsius, indicating when the air becomes saturated with moisture.
t: Air temperature in degrees Celsius.
psl: Atmospheric pressure at sea level in hPa (hectopascals).
Machine learning with RAPIDS
This tutorial covers the acceleration of three fundamental ML algorithms with cuDF and cuML: regression, classification, and clustering.
Installation
Before analyzing the Meteonet dataset, install and set up RAPIDS cuDF and cuML. Refer to the RAPIDS Installation Guide for instructions based on your system requirements.
Classification
Classification is a type of ML algorithm used to predict a categorical value based on a set of features. In this case, the goal is to predict weather conditions (such as sunny, cloudy, or rainy) and wind direction using temperature, humidity, and other factors.
Random forest is a powerful and versatile ML method capable of performing both regression and classification tasks. This section uses the cuML Random Forest Classifier to classify the weather conditions and wind direction at a certain time and location. The accuracy of the model can be used to evaluate its performance.
For this tutorial, 3 years of northwest station data has been consolidated into a single dataframe named NW_data.csv. To see the complete steps for combining the data, visit the Introduction to Machine Learning Using cuML notebook on GitHub.
import cudf, cuml
from cuml.ensemble import RandomForestClassifier as cuRF
# Load data
df = cudf.read_csv('./NW_data.csv').dropna()
To prepare the data for classification, perform preprocessing tasks such as converting the date column to datetime format and extracting the hour.
# Convert date column to datetime and extract hour
df['date'] = cudf.to_datetime(df['date'])
df['hour'] = df['date'].dt.hour
# Drop the original 'date' column
df = df.drop(['date'], axis=1)
Create two new categorical columns: wind_direction and weather_condition.
For wind_direction, discretize the dd column (assumed to be wind direction in degrees) into four categories: north (0-90 degrees), east (90-180 degrees), south (180-270 degrees), and west (270-360 degrees).
For weather_condition, discretize the precip column (which is the amount of precipitation) into three categories: sunny (no rain), cloudy (little rain), and rainy (more rain).
# Discretize weather condition based on precipitation amount
df['weather_condition'] = cudf.cut(df['precip'], bins=[-0.1, 0.1, 1, float('inf')], labels=['sunny', 'cloudy', 'rainy'])
Then convert these categorical columns into numerical labels that the RandomForestClassifier can work with using .cat.codes.
# Convert 'wind_direction' and 'weather_condition' columns to category
df['wind_direction'] = df['wind_direction'].astype('category').cat.codes
df['weather_condition'] = df['weather_condition'].astype('category').cat.codes
Model training
Now that preprocessing is done, the next step is to define a function to predict wind direction and weather conditions:
def train_and_evaluate(target):
# Split into features and target
X = df.drop(target, axis=1)
y = df[target]
# Split the dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define the model
model = cuRF()
# Train the model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy for predicting {target} is {accuracy}")
return model
Now that the function is ready, the next step is to train the model with the following call, mentioning the target variable:
This tutorial uses the cuML Random Forest Classifier to classify weather conditions and wind direction in the northwest dataset. Preprocessing steps include converting the date column, discretizing wind direction and weather conditions, and converting categorical columns to numerical labels. The models were trained and evaluated using accuracy as the evaluation metric.
Regression
Regression is an ML algorithm used to predict a continuous value based on a set of features. For example, you could use regression to predict the price of a house based on its features, such as the number of bedrooms, the square footage, and the location.
Linear regression is a popular algorithm for predicting a quantitative response. For this tutorial, use the cuML implementation of linear regression to predict temperature, humidity, and precipitation at different times and locations. The R^2 score can be used to evaluate the performance of your regression models.
Start by importing the required libraries for this section:
from cuml import make_regression, train_test_split
from cuml.linear_model import LinearRegression as cuLinearRegression
from cuml.metrics.regression import r2_score
from cuml.preprocessing.LabelEncoder import LabelEncoder
Next, load the NW dataset by reading the NW_data.csv file into a dataframe and dropping any rows with missing values:
# Load data
df = cudf.read_csv('/NW_data.csv').dropna()
For many ML algorithms, categorical input data must be converted to numeric forms. For this example, number_sta, which signifies ‘station number,’ is converted using LabelEncoder, which assigns unique numeric values to each category.
Next, numeric features must be normalized to prevent the model from being biased by the variable scales.
Then transform the ‘date’ column into an ‘hour’ feature, as weather patterns often correlate with the time of day. Finally, drop the ‘date’ column, as the models used cannot process this directly.
# Convert categorical variables to numeric variables
le = LabelEncoder()
df['number_sta'] = le.fit_transform(df['number_sta'])
# Normalize numeric features
numeric_columns = ['lat', 'lon', 'height_sta', 'dd', 'ff', 'hu', 'td', 't', 'psl']
for col in numeric_columns:
if df[col].dtype != 'object':
df[col] = (df[col] - df[col].mean()) / df[col].std()
else:
print(f"Skipping normalization for non-numeric column: {col}")
# Convert date column to datetime and extract hour
df['date'] = cudf.to_datetime(df['date'])
df['hour'] = df['date'].dt.hour
# Drop the original 'date' column
df = df.drop(['date'], axis=1)
Model training and performance
With preprocessing done, the next step is to define a function that trains two models to predict temperature and humidity from weather stations.
To evaluate the performance of the regression model, use R^2, the coefficient of determination. A higher R^2 indicates a model that better predicts the data.
def train_and_evaluate(target):
# Split into features and target
X = df.drop(target, axis=1)
y = df[target]
# Split the dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define the model
model = cuLinearRegression()
# Train the model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
r2 = r2_score(y_test, predictions)
print(f"R^2 score for predicting {target} is {r2}")
return model
Now that the function is written, the next step is to train the model with the following call, specifying the target variable:
This examples demonstrates how to use the cuML linear regression to predict temperature, humidity, and precipitation using the northwest dataset. To evaluate the performance of the regression models, we used the R^2 score. It’s important to note that model performance can be further improved by exploring techniques such as feature selection, regularization, and advanced models.
Clustering
Clustering is an unsupervised machine learning (ML) technique used to group similar instances based on their characteristics. It helps identify patterns and structure within the data. This section explores the use of K-Means, a popular centroid-based clustering algorithm, to cluster weather conditions based on temperature and precipitation.
To begin, preprocess the dataset. Focus on two specific features: temperature (t) and precipitation (pp). Any rows with missing values will be removed for simplicity.
import cudf
from cuml import KMeans
# Load data
df = cudf.read_csv("/NW_data.csv").dropna()
# Select the features for clustering
features = ['t', 'pp']
df_kmeans = df[features]
Next, apply K-Means clustering to the data. The goal is to partition the data into a specified number of clusters, with each cluster represented by the mean of the data points within it.
# Initialize the KMeans model
kmeans = KMeans(n_clusters=5, random_state=42)
# Fit the model
kmeans.fit(df_kmeans)
After fitting the model, retrieve the cluster labels, indicating the cluster to which each data point belongs.
# Get the cluster labels
kmeans_labels = kmeans.labels_
# Add the cluster labels as new columns to the dataframe
df['KMeans_Labels_Temperature'] = cudf.Series(kmeans_labels)
df['KMeans_Labels_Precipitation'] = cudf.Series(kmeans_labels)
Model training and performance
To evaluate the quality of the clustering model, examine the inertia, which represents the sum of squared distances between each data point and its closest centroid. Lower inertia values indicate tighter and more distinct clusters.
Determining the optimal number of clusters in K-Means is important. The Elbow Method helps to find the ideal number by plotting inertia values against different cluster numbers. The “elbow” point indicates the optimal balance between minimizing inertia and avoiding excessive clusters. For a detailed exploration of the Elbow Method, see the Introduction to Machine Learning Using cuML notebook on GitHub.
UMAP, available in cuML, is a powerful dimensionality reduction algorithm used for visualizing high-dimensional data and uncovering underlying patterns. While UMAP itself is not a dedicated clustering algorithm, its ability to project data into a lower-dimensional space often reveals clustering structures. It is widely used for cluster exploration and analysis, providing valuable insights into the data. Its efficient implementation in cuML enables advanced data analysis and pattern identification for clustering tasks.
Deploying cuML models
Once you have trained your cuML model, you can deploy it to NVIDIA Triton. Triton is an open-source, scalable, and production-ready inference server that can be used to deploy cuML models to various platforms, including cloud, on-premises, and edge devices.
Deploying your trained cuML model effectively in a production environment is crucial to extract its full potential. For models trained with cuML, there are three primary methods:
FIL backend for Triton
Triton Python backend
ONNX format
FIL backend for NVIDIA Triton
The FIL backend for Triton enables Triton users to take advantage of cuML’s Forest Inference Library (FIL) for accelerated inference of tree models, including decision forests and gradient-boosted forests. This Triton backend offers a highly-optimized method to deploy forest models, regardless of what framework was used to train them.
It offers native support for XGBoost and LightGBM models, as well as support for cuML and Scikit-Learn tree models using Treelite’s serialization format. While the FIL GPU mode offers state-of-the-art GPU-accelerated performance, it also provides an optimized CPU mode for prototype deployments or deployments where extreme small-batch latency is more important than overall throughput.
Another flexible approach for deploying models uses the Triton Python backend. This backend enables you to directly invoke RAPIDS Python libraries. It is highly flexible, so you can write custom Python scripts for handling preprocessing and postprocessing.
To deploy a cuML model using Triton Python backend, you need to:
Write a Python script that the Triton Server can call for inference. This script should handle any necessary preprocessing and postprocessing.
Configure the Triton Inference Server to use this Python script for serving your model.
In all cases, the Triton Inference Server provides a unified interface to all models, Triton Inference Server provides a unified interface to all models, regardless of their framework, making it easier to integrate into your existing services and infrastructure. It also enables dynamic batching of incoming requests, reducing compute resources and thereby lowering deployment costs.
Benchmarking RAPIDS
This post is a simplified walkthrough of the complete workflow from the Introduction to Machine Learning Using cuML notebook on GitHub. This workflow resulted in a speedup of up to 44x for combined workflow of data loading, preprocessing, and ML training. These results were performed on an NVIDIA RTX 8000 GPU with RAPIDS 23.04 and Intel Core i7-7800X CPU.
Figure 1. Benchmark results for training regression, classification, and clustering models on RAPIDS cuML with CPU as baseline
Conclusion
GPU-accelerated machine learning with cuDF and cuML can drastically speed up your data science pipelines. With faster data preprocessing using cuDF and the cuML scikit-learn-compatible API, it is easy to start leveraging the power of GPUs for machine learning.
Posted by Amir Yazdanbakhsh, Research Scientist, and Vijay Janapa Reddi, Visiting Researcher, Google Research
Computer Architecture research has a long history of developing simulators and tools to evaluate and shape the design of computer systems. For example, the SimpleScalar simulator was introduced in the late 1990s and allowed researchers to explore various microarchitectural ideas. Computer architecture simulators and tools, such as gem5, DRAMSys, and many more have played a significant role in advancing computer architecture research. Since then, these shared resources and infrastructure have benefited industry and academia and have enabled researchers to systematically build on each other’s work, leading to significant advances in the field.
Nonetheless, computer architecture research is evolving, with industry and academia turning towards machine learning (ML) optimization to meet stringent domain-specific requirements, such as ML for computer architecture, ML for TinyML acceleration, DNNacceleratordatapath, memory controllers, power consumption, security, and privacy. Although prior work has demonstrated the benefits of ML in design optimization, the lack of strong, reproducible baselines hinders fair and objective comparison across different methods and poses several challenges to their deployment. To ensure steady progress, it is imperative to understand and tackle these challenges collectively.
To alleviate these challenges, in “ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design”, accepted at ISCA 2023, we introduced ArchGym, which includes a variety of computer architecture simulators and ML algorithms. Enabled by ArchGym, our results indicate that with a sufficiently large number of samples, any of a diverse collection of ML algorithms are capable of finding the optimal set of architecture design parameters for each target problem; no one solution is necessarily better than another. These results further indicate that selecting the optimal hyperparameters for a given ML algorithm is essential for finding the optimal architecture design, but choosing them is non-trivial. We release the code and dataset across multiple computer architecture simulations and ML algorithms.
Challenges in ML-assisted architecture research
ML-assisted architecture research poses several challenges, including:
For a specific ML-assisted computer architecture problem (e.g., finding an optimal solution for a DRAM controller) there is no systematic way to identify optimal ML algorithms or hyperparameters (e.g., learning rate, warm-up steps, etc.). There is a wider range of ML and heuristic methods, from random walk to reinforcement learning (RL), that can be employed for design space exploration (DSE). While these methods have shown noticeable performance improvement over their choice of baselines, it is not evident whether the improvements are because of the choice of optimization algorithms or hyperparameters.
Thus, to ensure reproducibility and facilitate widespread adoption of ML-aided architecture DSE, it is necessary to outline a systematic benchmarking methodology.
While computer architecture simulators have been the backbone of architectural innovations, there is an emerging need to address the trade-offs between accuracy, speed, and cost in architecture exploration. The accuracy and speed of performance estimation widely varies from one simulator to another, depending on the underlying modeling details (e.g., cycle–accurate vs. ML–basedproxymodels). While analytical or ML-based proxy models are nimble by virtue of discarding low-level details, they generally suffer from high prediction error. Also, due to commercial licensing, there can be strict limits on the number of runs collected from a simulator. Overall, these constraints exhibit distinct performance vs. sample efficiency trade-offs, affecting the choice of optimization algorithm for architecture exploration.
It is challenging to delineate how to systematically compare the effectiveness of various ML algorithms under these constraints.
Finally, the landscape of ML algorithms is rapidly evolving and some ML algorithms need data to be useful. Additionally, rendering the outcome of DSE into meaningful artifacts such as datasets is critical for drawing insights about the design space.
In this rapidly evolving ecosystem, it is consequential to ensure how to amortize the overhead of search algorithms for architecture exploration. It is not apparent, nor systematically studied how to leverage exploration data while being agnostic to the underlying search algorithm.
ArchGym design
ArchGym addresses these challenges by providing a unified framework for evaluating different ML-based search algorithms fairly. It comprises two main components: 1) the ArchGym environment and 2) the ArchGym agent. The environment is an encapsulation of the architecture cost model — which includes latency, throughput, area, energy, etc., to determine the computational cost of running the workload, given a set of architectural parameters — paired with the target workload(s). The ArchGym agent is an encapsulation of the ML algorithm used for the search and consists of hyperparameters and a guiding policy. The hyperparameters are intrinsic to the algorithm for which the model is to be optimized and can significantly influence performance. The policy, on the other hand, determines how the agent selects a parameter iteratively to optimize the target objective.
Notably, ArchGym also includes a standardized interface that connects these two components, while also saving the exploration data as the ArchGym Dataset. At its core, the interface entails three main signals: hardware state, hardware parameters, and metrics. These signals are the bare minimum to establish a meaningful communication channel between the environment and the agent. Using these signals, the agent observes the state of the hardware and suggests a set of hardware parameters to iteratively optimize a (user-defined) reward. The reward is a function of hardware performance metrics, such as performance, energy consumption, etc.
ArchGym comprises two main components: the ArchGym environment and the ArchGym agent. The ArchGym environment encapsulates the cost model and the agent is an abstraction of a policy and hyperparameters. With a standardized interface that connects these two components, ArchGym provides a unified framework for evaluating different ML-based search algorithms fairly while also saving the exploration data as the ArchGym Dataset.
ML algorithms could be equally favorable to meet user-defined target specifications
Using ArchGym, we empirically demonstrate that across different optimization objectives and DSE problems, at least one set of hyperparameters exists that results in the same hardware performance as other ML algorithms. A poorly selected (random selection) hyperparameter for the ML algorithm or its baseline can lead to a misleading conclusion that a particular family of ML algorithms is better than another. We show that with sufficient hyperparameter tuning, different search algorithms, even random walk (RW), are able to identify the best possible normalized reward. However, note that finding the right set of hyperparameters may require exhaustive search or even luck to make it competitive.
With a sufficient number of samples, there exists at least one set of hyperparameters that results in the same performance across a range of search algorithms. Here the dashed line represents the maximum normalized reward. Cloud-1, cloud-2, stream, and random indicate four different memory traces for DRAMSys (DRAM subsystem design space exploration framework).
Dataset construction and high-fidelity proxy model training
Creating a unified interface using ArchGym also enables the creation of datasets that can be used to design better data-driven ML-based proxy architecture cost models to improve the speed of architecture simulation. To evaluate the benefits of datasets in building an ML model to approximate architecture cost, we leverage ArchGym’s ability to log the data from each run from DRAMSys to create four dataset variants, each with a different number of data points. For each variant, we create two categories: (a) Diverse Dataset (DD), which represents the data collected from different agents (ACO, GA, RW, and BO), and (b) ACO only, which shows the data collected exclusively from the ACO agent, both of which are released along with ArchGym. We train a proxy model on each dataset using random forest regression with the objective to predict the latency of designs for a DRAM simulator. Our results show that:
As we increase the dataset size, the average normalized root mean squared error (RMSE) slightly decreases.
However, as we introduce diversity in the dataset (e.g., collecting data from different agents), we observe 9× to 42× lower RMSE across different dataset sizes.
Diverse dataset collection across different agents using ArchGym interface.
The impact of a diverse dataset and dataset size on the normalized RMSE.
The need for a community-driven ecosystem for ML-assisted architecture research
While, ArchGym is an initial effort towards creating an open-source ecosystem that (1) connects a broad range of search algorithms to computer architecture simulators in an unified and easy-to-extend manner, (2) facilitates research in ML-assisted computer architecture, and (3) forms the scaffold to develop reproducible baselines, there are a lot of open challenges that need community-wide support. Below we outline some of the open challenges in ML-assisted architecture design. Addressing these challenges requires a well coordinated effort and a community driven ecosystem.
Key challenges in ML-assisted architecture design.
We call this ecosystem Architecture 2.0. We outline the key challenges and a vision for building an inclusive ecosystem of interdisciplinary researchers to tackle the long-standing open problems in applying ML for computer architecture research. If you are interested in helping shape this ecosystem, please fill out the interest survey.
Conclusion
ArchGym is an open source gymnasium for ML architecture DSE and enables an standardized interface that can be readily extended to suit different use cases. Additionally, ArchGym enables fair and reproducible comparison between different ML algorithms and helps to establish stronger baselines for computer architecture research problems.
We invite the computer architecture community as well as the ML community to actively participate in the development of ArchGym. We believe that the creation of a gymnasium-type environment for computer architecture research would be a significant step forward in the field and provide a platform for researchers to use ML to accelerate research and lead to new and innovative designs.
Acknowledgements
This blogpost is based on joint work with several co-authors at Google and Harvard University. We would like to acknowledge and highlight Srivatsan Krishnan (Harvard) who contributed several ideas to this project in collaboration with Shvetank Prakash (Harvard), Jason Jabbour (Harvard), Ikechukwu Uchendu (Harvard), Susobhan Ghosh (Harvard), Behzad Boroujerdian (Harvard), Daniel Richins (Harvard), Devashree Tripathy (Harvard), and Thierry Thambe (Harvard). In addition, we would also like to thank James Laudon, Douglas Eck, Cliff Young, and Aleksandra Faust for their support, feedback, and motivation for this work. We would also like to thank John Guilyard for the animated figure used in this post. Amir Yazdanbakhsh is now a Research Scientist at Google DeepMind and Vijay Janapa Reddi is an Associate Professor at Harvard.
Jacob Norris is a 3D artist and the president, co-founder and creative director of Sierra Division Studios — an outsource studio specializing in digital 3D content creation.

 Automatic parking assist must overcome some unique challenges when perceiving obstacles. An ego vehicle contains sensors that perceive the environment around…
Automatic parking assist must overcome some unique challenges when perceiving obstacles. An ego vehicle contains sensors that perceive the environment around…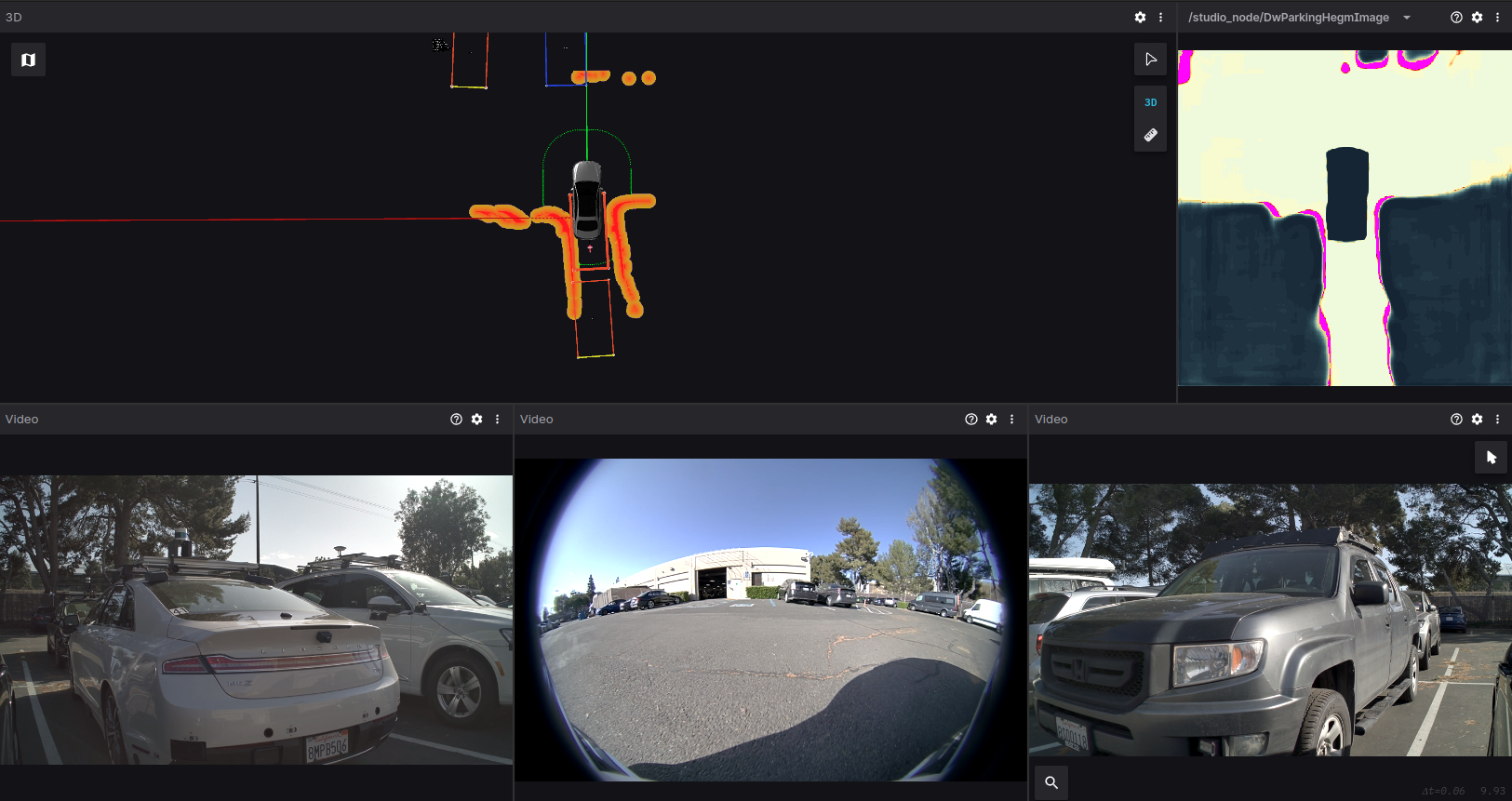

 So, you have a ton of data pipelines today and are considering investing in GPU acceleration through NVIDIA Base Command Platform. What steps should you take?…
So, you have a ton of data pipelines today and are considering investing in GPU acceleration through NVIDIA Base Command Platform. What steps should you take?…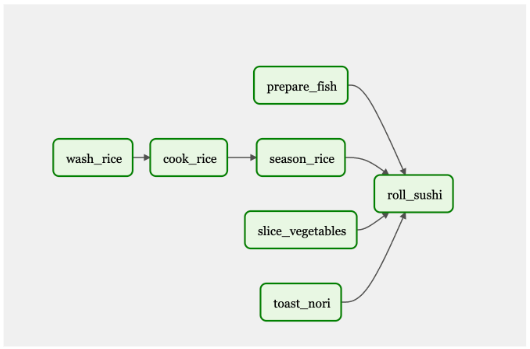
 This post is part of a series on accelerated data analytics. Visualization brings data to life, unveiling hidden patterns and insights through accessible…
This post is part of a series on accelerated data analytics. Visualization brings data to life, unveiling hidden patterns and insights through accessible…
 This post is part of a series on accelerated data analytics. If you are looking to take your machine learning (ML) projects to new levels of speed and…
This post is part of a series on accelerated data analytics. If you are looking to take your machine learning (ML) projects to new levels of speed and…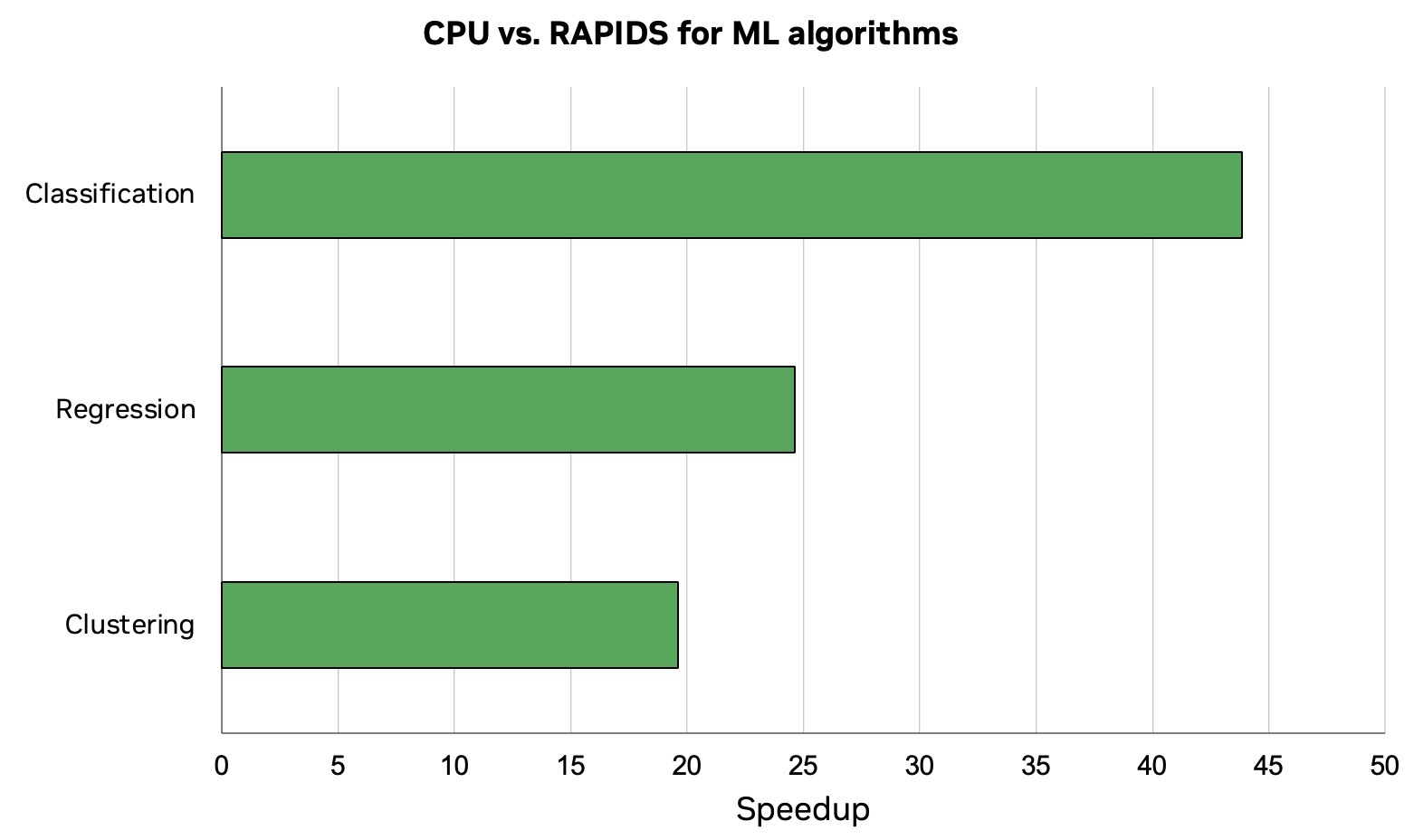





 On July 26, walkthrough DLSS 3 features within Unreal Engine 5.2 and learn how to best use the latest updates.
On July 26, walkthrough DLSS 3 features within Unreal Engine 5.2 and learn how to best use the latest updates.