Reconstructing a smooth surface from a point cloud is a fundamental step in creating digital twins of real-world objects and scenes. Algorithms for surface…
Reconstructing a smooth surface from a point cloud is a fundamental step in creating digital twins of real-world objects and scenes. Algorithms for surface reconstruction appear in various applications, such as industrial simulation, video game development, architectural design, medical imaging, and robotics.
Neural Kernel Surface Reconstruction (NKSR) is the new NVIDIA algorithm for reconstructing high-fidelity surfaces from large point clouds. NKSR can process millions of points in seconds and achieves state-of-the-art quality on a wide range of benchmarks. NKSR is an excellent substitute for traditional Poisson Surface Reconstruction, providing greater detail and faster runtimes.
NKSR leverages a novel 3D deep learning approach called Neural Kernel Fields to achieve high-quality reconstruction. First introduced in 2022 by the NVIDIA Toronto AI Lab, Neural Kernel Fields predict a data-dependent set of basis functions used to solve the closed-form surface reconstruction problem. This new approach enables unprecedented generalization (for training on objects and reconstructing scenes) and multimodal training on scenes and objects at different scales. For more technical details about the method, visit the NKSR project page.
Figure 1. Reconstructed geometry on Waymo Open Dataset
The kitchen sink model
Alongside the code release, we are excited to introduce the kitchen sink model, a comprehensive model trained on datasets of varying scales. By incorporating object-level and scene-level data, we have ensured the model’s versatility across different scenarios. To demonstrate its effectiveness, we have successfully applied the kitchen sink model to diverse datasets.
Figure 2 shows a room-level reconstruction result using a sparse input point cloud. Our method outperforms other baselines by generating smooth and accurate geometry.
Figure 2. Reconstruction performance of indoor rooms compared to the baselines
Figure 3 showcases the application of our method on a race track, and Figure 4 shows a neighborhood scene. These scenes were captured using an autonomous vehicle equipped with a lidar sensor. Both scenes span several kilometers in length, and we were able to efficiently process them on a GPU.
Figure 3. Reconstructed geometry of a long race track
Figure 4. Reconstructed geometry of a neighborhood
How to use NKSR
NKSR is easily accessible through pip, with PyTorch being a key dependency. This integration enables the direct installation of the package, ensuring a streamlined setup process.
The core computing operations of NKSR are accelerated using GPU, which results in high-speed processing and efficient performance. When deploying NKSR, it is necessary to define the positions and normals of your input point cloud. Alternatively, you can input the positions of the sensors capturing these points.
The code snippet below demonstrates how easy it is to use NKSR:
import nksr
import torch
device = torch.device("cuda:0")
reconstructor = nksr.Reconstructor(device)
# Note that input_xyz and input_normal are torch tensors of shape [N, 3] and [N, 3] respectively.
field = reconstructor.reconstruct(input_xyz, input_normal)
# input_color is also a tensor of shape [N, 3]
field.set_texture_field(nksr.fields.PCNNField(input_xyz, input_color))
# Increase the dual mesh's resolution.
mesh = field.extract_dual_mesh(mise_iter=2)
# Visualizing
from pycg import vis
vis.show_3d([vis.mesh(mesh.v, mesh.f, color=mesh.c)])
The culmination of this process is a triangulated mesh, which you can save directly or visualize based on your specific needs.
If the default configuration (kitchen sink model) does not adequately meet your requirements, the training code is provided. This additional resource offers the flexibility to train a custom model or to integrate NKSR into your existing pipeline. Our commitment to customization and usability ensures that NKSR can be adapted to various applications and scenarios.
Conclusion
NVIDIA Neural Kernel Surface Reconstruction presents a novel and cutting-edge approach to extract high-quality 3D surfaces from sparse point clouds. By employing a sparse Neural Kernel Field approach, the NKSR kitchen sink model can generalize to arbitrary inputs at any scale from a fixed training set of shapes. NKSR is fully open source and comes with training code and the pretrained kitchen sink model, which you can install directly with pip. You can further fine-tune NKSR to your specific datasets and problem domains, to enable even higher reconstruction quality in specialized applications.
Use NKSR for a chance to win a free GPU
We want to see what you can do with NKSR. Demonstrate your most impressive reconstruction results and captivating visualizations using NKSR. Then enter the NVIDIA NKSR Sweepstakes by September 8, 2023 for your chance to win a GeForce RTX 3090 Ti.
SANTA CLARA, Calif., June 08, 2023 (GLOBE NEWSWIRE) — NVIDIA today announced it will hold its 2023 Annual Meeting of Stockholders online on Thursday, June 22, at 11 a.m. PT. The meeting will …
SANTA CLARA, Calif., June 08, 2023 (GLOBE NEWSWIRE) — NVIDIA will present at the following event for the financial community: Nasdaq Investor Conference in Partnership with …
Universal Scene Description (OpenUSD) is an open and extensible framework for creating, editing, querying, rendering, collaborating, and simulating within 3D…
Universal Scene Description (OpenUSD) is an open and extensible framework for creating, editing, querying, rendering, collaborating, and simulating within 3D worlds. Invented by Pixar Animation Studios, USD is much more than a file format. It is an ecosystem and interchange paradigm that models, labels, classifies, and combines a wide range of data sources into a composed ground truth.
There’s increasing adoption of USD in various industries ranging from media and entertainment to scientific computing. The framework’s scalability and interoperability enable you to efficiently create high-fidelity and true-to-life simulations of the real world with collaborative and non-destructive authoring.
To help more developers get started leveraging USD to build tools for virtual worlds, NVIDIA is releasing an exclusive USD for Developers video series. The series delivers a foundational understanding of what many have called the HTML of the metaverse.
In the first episode of the series, we highlight four key features of USD that make it the ideal tool for data modeling and interchange:
Composition and layering: This enables sparse, non-destructive assembly of data from multiple different sources as individual layers. In other words, various users can make changes to the composed scene in different layers, but their edits are non-destructive and the data from all layers remains accessible.
Custom schemas:USD schemas do not end at geometry and shading. NVIDIA collaborated with Pixar and Apple to also create physics schemas for rigid bodies and continues to prototype new schemas to further expand the ecosystem and standards for virtually immersive environments.
Connecting any data source: USD data storage is not anchored to any filesystem or nonvolatile storage and can even be procedurally generated. This is made possible by the USD plug-in system for asset resolvers such as NVIDIA Omniverse Nucleus and file formats like Alembic and OBJ.
Dynamic data science pipelines: Hydra has evolved into a generalized pipeline for processing composed scene graphs and runtimes. The keyword for Hydra is flexibility as it’s not tightly coupled to any single runtime data layout. This enables Omniverse to compile the composed USD into a deeply vectorized data layout called Fabric. Hydra provides interfaces for implementing the business logic to process data as a customizable chain of runtime scene indexes.
Each video in the series will dive deeper into these four key features and more to help developers harness the data modeling and aggregation superpowers of USD. Watch the first episode now and be sure to subscribe and stay tuned for the rest of the series.
Video 1. This introductory series explores OpenUSD superpowers for developers to unlock new possibilities in 3D workflows
For more information about the latest advancements and to access more resources, see Universal Scene Description. For community discussion about USD, see the latest USD topics on the Omniverse forum.
Get into your favorite games faster by linking GeForce NOW to Steam, Epic Games Store and Ubisoft accounts. And get a peek at more games coming to GeForce NOW later this year by tuning in to Ubisoft Forward on Monday, June 12, when the game publisher will reveal its latest news and announcements. Plus, two Read article >
Today’s machine learning (ML) solutions are complex and rarely use just a single model. Training models effectively requires large, diverse datasets that may…
Today’s machine learning (ML) solutions are complex and rarely use just a single model. Training models effectively requires large, diverse datasets that may require multiple models to predict effectively. Also, deploying complex multi-model ML solutions in production can be a challenging task. A common example is when compatibility issues with different frameworks can lead to delayed insights.
A solution that easily serves various combinations of deep neural nets and tree-based models and that is framework-agnostic would help simplify deployment and scale ML solutions as they take on multiple layers.
In this post, I discuss how to leverage the versatility of NVIDIA software to handle different types of models and integrate them into your application. I demonstrate how NVIDIA RAPIDS supports data preparation and ML training for large datasets and how NVIDIA Triton Inference Server seamlessly serves both deep neural nets by PyTorch and tree-based models by XGBoost when predicting credit default.
Now, I describe how my team used this technique in our American Express Default Fault Prediction solution.
Essential tools for data preparation and deployment
When you’re preparing a complex ML model, there are many steps to prepare, train, and deploy an effective model. RAPIDS and Triton Inference Server both support key phases in the ML process.
RAPIDS is a suite of open-source software libraries and APIs designed to accelerate data science workflows on GPUs. It includes a variety of tools and libraries for data preprocessing, ML, and visualization. In this case, it supports data preprocessing and exploratory data analysis at the beginning of the workflow.
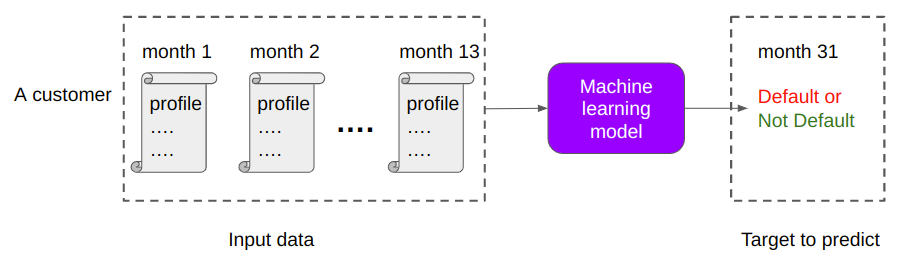
The aim is to predict if a customer will default on their credit card balance in the future, using their past monthly customer profile data. The binary target variable, default or no default, is determined by whether a customer pays back their outstanding credit card balance within 120 days of the statement date.
Figure 1 shows an overview of the problem and dataset, highlighting the key aspects of credit default prediction and the characteristics of the dataset. The test dataset is massive with 900K customers, 11M rows, and 191 columns, including both numerical and categorical features.
The goal was to create a model that can predict the categorical binary variable based on the other variables in the dataset and a mission-critical time value to manage. Before modeling, this large dataset requires significant feature engineering, making it an ideal candidate for data preparation with RAPIDS cuDF. The size of the dataset poses further challenges for real-time inferencing, which the high-performance NVIDIA Triton server addresses.
Figure 1. Problem overview: American Express Default Prediction competition
Approach
We broke the model development process into a series of steps:
Dataset preparation
Feature engineering
Dataset exploration
Autoregressive recursive neural network (RNN) model
Dataset performance
Dataset preparation
The given American Express data is a time series consisting of multiple profiles of a customer sorted by the customer ID and timestamp:
Each row in the dataset represents a customer’s profile for 1 month.
Each customer has 13 consecutive rows in the data, which represent their profiles in 13 consecutive months.
There are 214 columns in the data.
Columns are anonymized, except for customer_id and month, and fall into the following general categories: Delinquency, Spend, Payment, Balance, Risk
Table 1 summarizes the number of columns in each category. There is no information on what each column means other than its category. These anonymized columns are mostly floating-point numbers.
customer_id
month
Delinquency
Spend
Payment
Balance
Risk
# of columns
1
1
106
25
10
43
28
Table 1. Number of columns in each category
For training data, the ground truths, default or not, are stored in another tabular data where each customer corresponds to one row. There are two columns: customer_id and default.
Feature engineering with RAPIDS cuDF
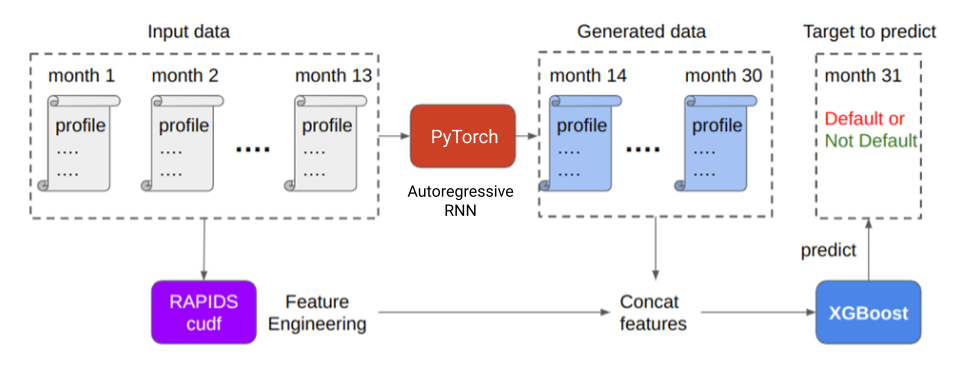
The project began with feature engineering to prepare the time-series dataset for the model. Time-series data notoriously requires massaging and becomes unwieldy for CPU-powered data science solutions. To run the data preparation efficiently for this phase, we harnessed the power of GPUs using RAPIDS cuDF.
We focused on slimming down the dataset to the most important data points by reducing the number of months for each customer profile to the last month in the set. The last month has the highest relevance in predicting future default events and reduces the number of rows to 900K. This is quickly done by drop_duplicates(keep=’last’) in cuDF.
RAPIDS cuDF can further help accelerate by creating differential and aggregate features for each customer_id value. While RAPIDS cuDF was used to engineer additional features in the preceding notebook, I disregarded those to maintain the simplicity of this single-GPU walkthrough.
Figure 2. Solution overview
Exploring the dataset
Each customer profile’s features were measured through month 13, while the date of default checking was month 31. Given the 17-month time gap in the dataset for defaulting customers, the team generated new customer profiles for the missing months (months 14 to months 30) to improve the model’s prediction rate. The team was inspired to implement the autoregressive RNN technique after exploring the data visually.
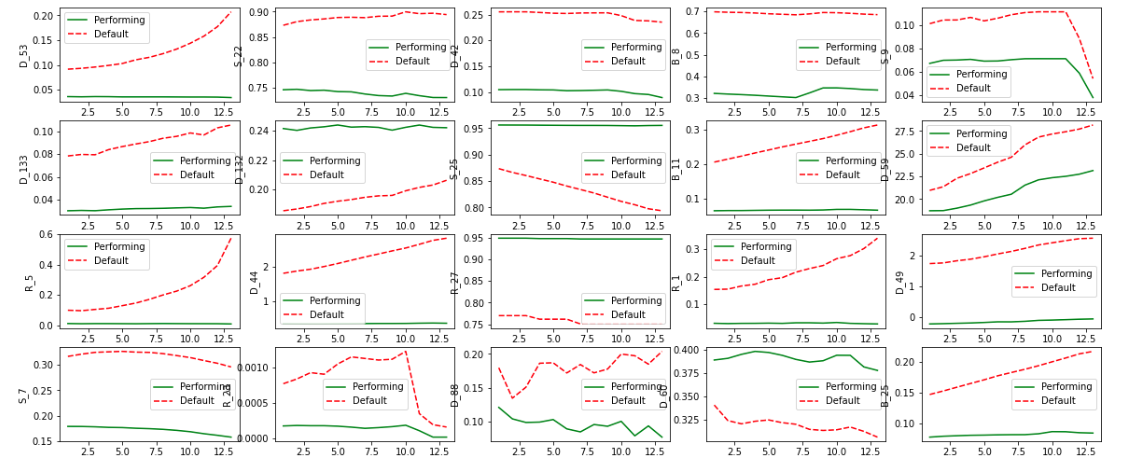
When exploring the dataset, the team visualized the data in a chart. Figure 3 plots the trends of a subset of columns over time. The x-axis is the month, and the y-axis shows the column name.
For example, the top-left subplot shows how column D_53, the 53rd column of the delinquency category, varies over months. The red dashed lines are the averaged values of column D_53 of positive samples, where Default=True and the green solid lines are averaged values of negative samples, respectively.
For most columns, there are obvious temporal patterns. A model can be trained to extrapolate and predict future values of columns. With this model, generating additional values for the dataset helps improve the model’s predictability.
When you’re planning for enhancing the dataset, another key is that the patterns can be different for each column. Linear trends, nonlinear trends, wiggles, and more variations are all observable. The data generation model must be versatile, flexible to learn, and generalize all these different patterns.
Generating new profiles with the autoregressive RNN model
Based on these data characteristics, our team proposed an autoregressive RNN model to learn all these patterns simultaneously. Autoregressive means that the output of the current time step is the input of the next time step. Figure 4 shows how autoregressive generation works.
Figure 4. Animation of autoregressive generation (source: WaveNet)
The input of the RNN model is the customer’s profile for the current month, including all 214 columns. The output of the RNN model is the predicted customer profile for the next month. The autoregressive RNN used in this approach is trained in a self-supervised manner, meaning it only employs customer profiles for training and does not require the “default or not” target column.
This self-supervised training to enhance datasets enables you to use a large amount of unlabeled data—a significant advantage in real-world applications as labeled data is often difficult and expensive to obtain.
Performance of the new dataset
The RNN can accurately predict future profiles. The root of the mean squared error is used between the ground truth profiles and predicted profiles. Compare the RNN against a simple baseline and assume that future profiles are the same as the last observed profile.
Autoregressive RNN
Last observed profile baseline
RMSE of all 214 columns
0.019
0.03
Table 2. Compare RMSE values for autoregressive RNN and the baseline (smaller is better)
In Table 2, the RNN reduced RMSE from 0.03 to 0.019 (a 33% improvement). This is a significant enhancement to the original dataset.
Figure 2 showed that the last step to producing the dataset for training is to combine the last profiles and generated profiles into one matrix. Do this using the joins function in RAPIDS cuDF and feed them to the downstream XGBoost classifier to predict defaults. The generated profiles greatly enhance the performance of the model.
Table 3 shows that, by combining the most recent profiles and generated future profiles, the XGBoost classifier can more accurately predict future default by 0.003. This is a significant improvement for default detection problems. Such improvement could move the solution rank up by hundreds of places in the American Express default prediction competition!
xgb trained on last profiles
xgb trained on last profiles and autoregressive RNN-generated profiles
Table 3. Evaluating default predictions by comparing XGBoost with and without autoregressive RNN-generated features (larger is better)
Deploy models to Triton Inference Server
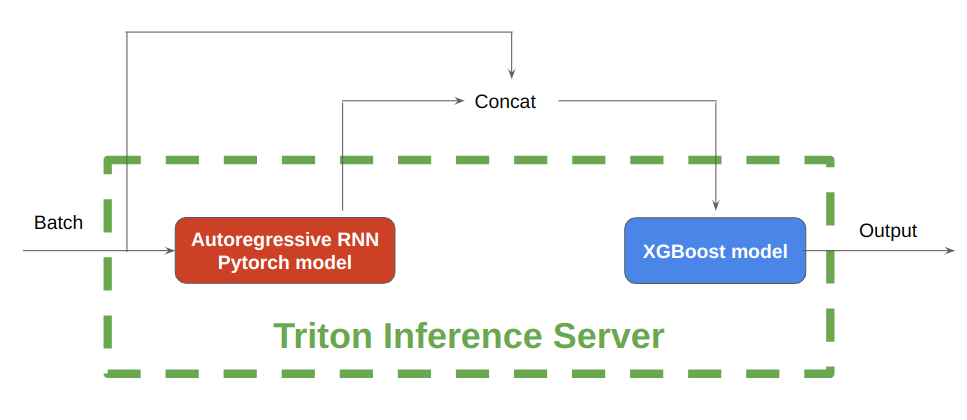
Figure 5 shows that, during inference, NVIDIA Triton Inference Server enables the hosting of both the autoregressive RNN model implemented in PyTorch and the tree-based models implemented in XGBoost, on either CPU or GPU.
First, save the pretrained PyTorch RNN models and XGBoost models in separate folders with correct folder hierarchies. Next, write configuration files for each model. The PyTorch model processes the batch of input data to generate the future profiles, after which the concatenated profiles are input into the XGBoost model for further inference.
In under 6 seconds, 115K customer profiles have been inferred with this rnn-xgb pipeline on a single GPU.
Figure 5. Autoregressive RNN and XGBoost models with NVIDIA Triton Inference Server
The inference time is blazing fast even with this complicated model pipeline including autoregressive RNN for 13 time-steps and XGBoost for classification. Running the NVIDIA Triton Inference Server pipeline on 11.3 million American Express customer profiles takes only 45 seconds on a single NVIDIA V100 GPU.
Summary
The proposed solution for credit default prediction shown in this post successfully leverages the power of both deep neural nets and tree models to improve the accuracy of predictions by supplementing data.
Data processing of the time-series data was easier and faster with RAPIDS cuDF. The deployment of the models was made seamless with Triton Inference Server, which can host both deep neural nets and tree models on either CPU or GPU. This makes it a powerful tool for real-time inference.
This demo also highlights the potential of applying the high-performance computing power of GPUs and Triton Inference Server in credit default prediction, opening avenues for further exploration and improvement in the financial services field.
Posted by Thibault Sellam, Research Scientist, Google
Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. Part of this commitment involves developing high-quality speech synthesis technologies, which build upon projects such as VDTTS and AudioLM, for users that speak many different languages.
After developing a new model, one must evaluate whether the speech it generates is accurate and natural: the content must be relevant to the task, the pronunciation correct, the tone appropriate, and there should be no acoustic artifacts such as cracks or signal-correlated noise. Such evaluation is a major bottleneck in the development of multilingual speech systems.
The most popular method to evaluate the quality of speech synthesis models is human evaluation: a text-to-speech (TTS) engineer produces a few thousand utterances from the latest model, sends them for human evaluation, and receives results a few days later. This evaluation phase typically involves listening tests, during which dozens of annotators listen to the utterances one after the other to determine how natural they sound. While humans are still unbeaten at detecting whether a piece of text sounds natural, this process can be impractical — especially in the early stages of research projects, when engineers need rapid feedback to test and restrategize their approach. Human evaluation is expensive, time consuming, and may be limited by the availability of raters for the languages of interest.
Another barrier to progress is that different projects and institutions typically use various ratings, platforms and protocols, which makes apples-to-apples comparisons impossible. In this regard, speech synthesis technologies lag behind text generation, where researchers have long complemented human evaluation with automatic metrics such as BLEU or, more recently, BLEURT.
In “SQuId: Measuring Speech Naturalness in Many Languages“, to be presented at ICASSP 2023, we introduce SQuId (Speech Quality Identification), a 600M parameter regression model that describes to what extent a piece of speech sounds natural. SQuId is based on mSLAM (a pre-trained speech-text model developed by Google), fine-tuned on over a million quality ratings across 42 languages and tested in 65. We demonstrate how SQuId can be used to complement human ratings for evaluation of many languages. This is the largest published effort of this type to date.
Evaluating TTS with SQuId
The main hypothesis behind SQuId is that training a regression model on previously collected ratings can provide us with a low-cost method for assessing the quality of a TTS model. The model can therefore be a valuable addition to a TTS researcher’s evaluation toolbox, providing a near-instant, albeit less accurate alternative to human evaluation.
SQuId takes an utterance as input and an optional locale tag (i.e., a localized variant of a language, such as “Brazilian Portuguese” or “British English”). It returns a score between 1 and 5 that indicates how natural the waveform sounds, with a higher value indicating a more natural waveform.
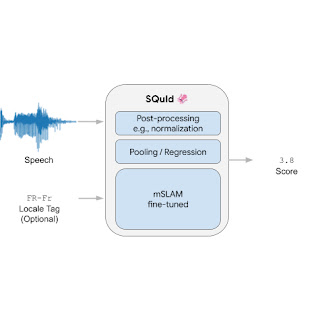
Internally, the model includes three components: (1) an encoder, (2) a pooling / regression layer, and (3) a fully connected layer. First, the encoder takes a spectrogram as input and embeds it into a smaller 2D matrix that contains 3,200 vectors of size 1,024, where each vector encodes a time step. The pooling / regression layer aggregates the vectors, appends the locale tag, and feeds the result into a fully connected layer that returns a score. Finally, we apply application-specific post-processing that rescales or normalizes the score so it is within the [1, 5] range, which is common for naturalness human ratings. We train the whole model end-to-end with a regression loss.
The encoder is by far the largest and most important piece of the model. We used mSLAM, a pre-existing 600M-parameter Conformer pre-trained on both speech (51 languages) and text (101 languages).
The SQuId model.
To train and evaluate the model, we created the SQuId corpus: a collection of 1.9 million rated utterances across 66 languages, collected for over 2,000 research and product TTS projects. The SQuId corpus covers a diverse array of systems, including concatenative and neural models, for a broad range of use cases, such as driving directions and virtual assistants. Manual inspection reveals that SQuId is exposed to a vast range of of TTS errors, such as acoustic artifacts (e.g., cracks and pops), incorrect prosody (e.g., questions without rising intonations in English), text normalization errors (e.g., verbalizing “7/7” as “seven divided by seven” rather than “July seventh”), or pronunciation mistakes (e.g., verbalizing “tough” as “toe”).
A common issue that arises when training multilingual systems is that the training data may not be uniformly available for all the languages of interest. SQuId was no exception. The following figure illustrates the size of the corpus for each locale. We see that the distribution is largely dominated by US English.
Locale distribution in the SQuId dataset.
How can we provide good performance for all languages when there are such variations? Inspired by previous work on machine translation, as well as past work from the speech literature, we decided to train one model for all languages, rather than using separate models for each language. The hypothesis is that if the model is large enough, then cross-locale transfer can occur: the model’s accuracy on each locale improves as a result of jointly training on the others. As our experiments show, cross-locale proves to be a powerful driver of performance.
Experimental results
To understand SQuId’s overall performance, we compare it to a custom Big-SSL-MOS model (described in the paper), a competitive baseline inspired by MOS-SSL, a state-of-the-art TTS evaluation system. Big-SSL-MOS is based on w2v-BERT and was trained on the VoiceMOS’22 Challenge dataset, the most popular dataset at the time of evaluation. We experimented with several variants of the model, and found that SQuId is up to 50.0% more accurate.
SQuId versus state-of-the-art baselines. We measure agreement with human ratings using the Kendall Tau, where a higher value represents better accuracy.
To understand the impact of cross-locale transfer, we run a series of ablation studies. We vary the amount of locales introduced in the training set and measure the effect on SQuId’s accuracy. In English, which is already over-represented in the dataset, the effect of adding locales is negligible.
SQuId’s performance on US English, using 1, 8, and 42 locales during fine-tuning.
However, cross-locale transfer is much more effective for most other locales:
SQuId’s performance on four selected locales (Korean, French, Thai, and Tamil), using 1, 8, and 42 locales during fine-tuning. For each locale, we also provide the training set size.
To push transfer to its limit, we held 24 locales out during training and used them for testing exclusively. Thus, we measure to what extent SQuId can deal with languages that it has never seen before. The plot below shows that although the effect is not uniform, cross-locale transfer works.
SQuId’s performance on four “zero-shot” locales; using 1, 8, and 42 locales during fine-tuning.
When does cross-locale operate, and how? We present many more ablations in the paper, and show that while language similarity plays a role (e.g., training on Brazilian Portuguese helps European Portuguese) it is surprisingly far from being the only factor that matters.
Conclusion and future work
We introduce SQuId, a 600M parameter regression model that leverages the SQuId dataset and cross-locale learning to evaluate speech quality and describe how natural it sounds. We demonstrate that SQuId can complement human raters in the evaluation of many languages. Future work includes accuracy improvements, expanding the range of languages covered, and tackling new error types.
Acknowledgements
The author of this post is now part of Google DeepMind. Many thanks to all authors of the paper: Ankur Bapna, Joshua Camp, Diana Mackinnon, Ankur P. Parikh, and Jason Riesa.
In the latest episode of NVIDIA’s AI Podcast, Anant Agarwal, founder of edX and Chief Platform Officer at 2U, shared his vision for the future of online education and how AI is revolutionizing the learning experience. Agarwal, a strong advocate for Massive Open Online Courses, or MOOCs, discussed the importance of accessibility and quality in Read article >
Thanks to “street views,” modern mapping tools can be used to scope out a restaurant before deciding to go there, better navigate directions by viewing landmarks in the area or simulate the experience of being on the road. The technique for creating these 3D views is called photogrammetry — the process of capturing images and Read article >
Getting discharged from the hospital is a major milestone for patients — but sometimes, it’s not the end of their road to recovery. Nearly 15% of hospital patients in the U.S. are readmitted within 30 days of their initial discharge, which is often associated with worse outcomes and higher costs for both patients and hospitals. Read article >

 Reconstructing a smooth surface from a point cloud is a fundamental step in creating digital twins of real-world objects and scenes. Algorithms for surface…
Reconstructing a smooth surface from a point cloud is a fundamental step in creating digital twins of real-world objects and scenes. Algorithms for surface…



 Universal Scene Description (OpenUSD) is an open and extensible framework for creating, editing, querying, rendering, collaborating, and simulating within 3D…
Universal Scene Description (OpenUSD) is an open and extensible framework for creating, editing, querying, rendering, collaborating, and simulating within 3D… Today’s machine learning (ML) solutions are complex and rarely use just a single model. Training models effectively requires large, diverse datasets that may…
Today’s machine learning (ML) solutions are complex and rarely use just a single model. Training models effectively requires large, diverse datasets that may…