Siloed data has long been a challenge in architecture, engineering, and construction (AEC), hindering productivity and collaboration. However, new innovative…
Siloed data has long been a challenge in architecture, engineering, and construction (AEC), hindering productivity and collaboration. However, new innovative…
Siloed data has long been a challenge in architecture, engineering, and construction (AEC), hindering productivity and collaboration. However, new innovative solutions are transforming the way that architects, engineers, and construction managers work together on BIM (building information management) workflows, offering new possibilities for real-time collaboration.
The new NVIDIA Omniverse Connector from Vectorworks exemplifies this potential, opening up exciting new workflow options. Vectorworks creates design software that serves the architecture, landscape, and entertainment industries. They specialize in hybrid 2D and 3D workflow solutions with an emphasis on visualization and non-proprietary collaboration.
Universal Scene Description (OpenUSD) helps Vectorworks provide their customers with even more flexibility in the design process and the ability to collaborate freely with anyone involved in a project. The connector helps optimize BIM workflows and provides real-time collaboration at every design phase. USD is an open and extensible framework and ecosystem for describing, composing, simulating, and collaborating within 3D worlds. It is the foundation of NVIDIA Omniverse.
What is building information modeling?
At its core, Vectorworks is building information modeling (BIM) software. BIM workflows nowadays are the defining force in the AEC industry, and they’re growing in popularity in landscape architecture, too.
BIM is a collaborative digital process that integrates design, construction, and operation information into a single model, enabling stakeholders to visualize, analyze, and coordinate all aspects of a building project. To get a short history of BIM and learn about its various use cases in AEC, see What is BIM | Building Information Modeling in the AEC Industry.
Although collaboration is essential to data-driven BIM workflows, there is currently a lack of software options for design collaboration and coordination.
Real-time BIM collaboration at every design phase
There are four standard phases involved in the design of a building.
First, architects must pull together all the necessary information to start their project for conceptual design, site planning, and analysis. With the Omniverse Connector, teams can pull this data from a wide variety of file formats and sources with Universal Scene Description (OpenUSD).
Next, teams explore schematic designs to refine initial design concepts and ideas. Intuitive drawing tools and a flexible modeling engine are easy to use with the connector, enabling you to explore different design options and evaluate their feasibility. You can easily transition from massing models to a BIM model, visualize concepts with integrated 3D rendering, and share the results in real-time with their entire team.
When moving into more detailed design phases, BIM tools can often become less creative in nature. The Vectorworks Omniverse Connector is a bit different. It enables you to freely sketch, model, and document your design ideas with precision-drafting capabilities so that you’re not limited by presets and strict parameters.
In the last phase of construction documentation, teams must coordinate with consultants and continue to verify and refine models to make sure that the models are ready for the real world. Omniverse makes this process seamless, enabling different users to collaborate in real time on models and have the models automatically updated in the construction documentation.
Almost any stakeholder in the design process can now collaborate in real time on design efforts with the new connector. This could be a building architect working with a landscape architect or a lighting designer collaborating with a set designer on a live event.
Combining models into Omniverse enables you to collaborate in a real-time, virtual environment in all project phases, enabling you to ensure that you’re developing cohesive design solutions.
Developing the connector in Omniverse
Implementing the Omniverse Connector was a straightforward and streamlined process. The Vectorworks developers followed the comprehensive NVIDIA documentation and referred to existing connectors for user interface and user experience design. They also asked questions in the Omniverse forums where answers provided directly from NVIDIA engineers and managers helped deliver the connector on schedule with the Vectorworks 2023 Service Pack 4 release.
Key to the development process was the Omniverse Connect HelloWorld sample, documentation that demonstrates how to build your own NVIDIA Omniverse Connector, along with a range of functionalities that enable you to interact with USD and the Omniverse Nucleus server.
The sample documentation made it easy to quickly start reaping the benefits of OpenUSD. It shows how to save projects to USD format so you can take advantage of creating and editing live layers. Then, you can create a USD stage, which serves as a container for organizing and manipulating the Vectorworks 3D scene data. This stage acts as a foundation for the subsequent operations.
Seamless workflow management is critical to the experience Vectorworks creates for users. The sample demonstrates how to create Omniverse Nucleus checkpoints, which serve as saved states of the stage. These checkpoints provide the ability to revert to a previous stage configuration, facilitating experimentation and version control.
The sample also demonstrates how to enhance communication and collaboration for users by implementing the capability to send and receive messages over a channel on the Nucleus server. This feature fosters interaction and coordination among users within a shared environment.
“Ultimately, the ease with which we were able to implement the Omniverse Connector speaks to how attainable the entry point is and enabled us to easily leverage Omniverse APIs that enhance workflows for our users,” said Dave Donley, senior director of rendering and research at Vectorworks.
“The collaborative, multi-disciplinary nature of Omniverse is a great fit, especially with OpenUSD at its foundation and we can’t wait to see the great designs our customers will produce with it.”
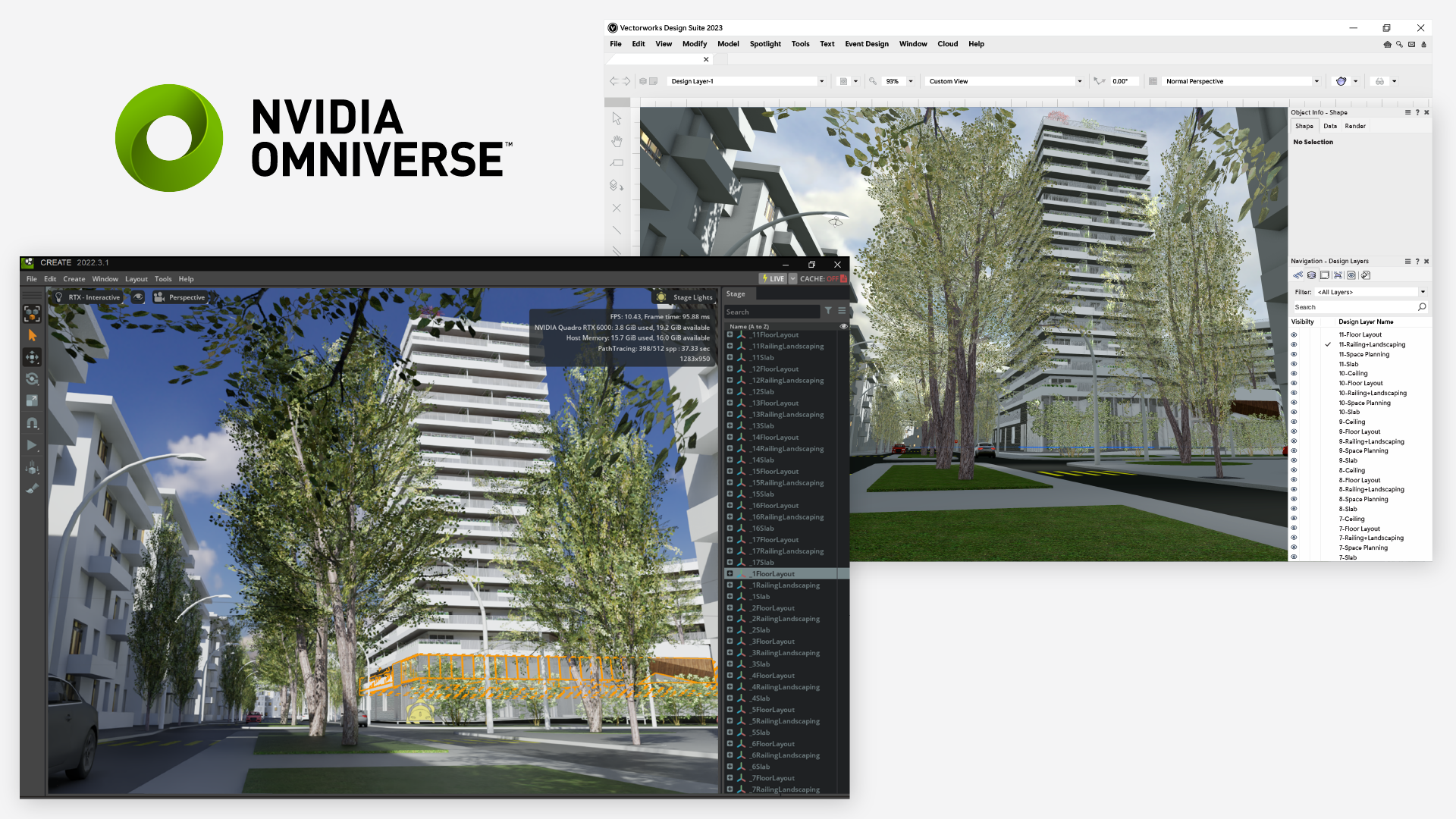
Maintaining a competitive advantage with next-gen tech
Staying up-to-date with technology trends is crucial for maintaining a competitive advantage and identifying new opportunities for innovation and growth in your field.
By providing customers with powerful solutions that have the potential to revolutionize workflows like the NVIDIA Omniverse Connector, Vectorworks is making good on the promise of their public development roadmap: to constantly evolve their technology in line with the needs of customers during this time of accelerated digital transformation.
“At Vectorworks, we continue to evolve our digital solutions to empower customers to create and share great designs. With the latest update, which delivers a direct connection to NVIDIA Omniverse, comes yet another reminder of our passion and commitment to serve customers as a design partner—embracing the power and possibilities afforded by next-generation technology,” said Steve Johnson, chief technology officer at Vectorworks.
Not only does the NVIDIA Omniverse Connecter provide Vectorworks users with access to a powerful real-time visualization tool, but it also paves the way for exciting developments in the future.
As the design industries continue to mature, use cases for OpenUSD will continue to present themselves. Vectorworks’ compatibility with USD puts them in an advantageous position to be able to implement future technology. By embracing Omniverse’s immense potential, Vectorworks and its users are poised to lead the charge toward a more collaborative and innovative future in AEC.
To start taking advantage of this powerful connection, see the NVIDIA Omniverse Connector page at Vectorworks.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you’re a developer, get started building your first extension or developing a Connector with Omniverse resources. Stay up-to-date on the platform by subscribing to the newsletter, and following NVIDIA Omniverse on Instagram, Medium, and Twitter. For resources, check out our forums, Discord server, Twitch, and YouTube channels.
 NVIDIA DLSS Frame Generation is the new performance multiplier in DLSS 3 that uses AI to create entirely new frames. This breakthrough has made real-time path…
NVIDIA DLSS Frame Generation is the new performance multiplier in DLSS 3 that uses AI to create entirely new frames. This breakthrough has made real-time path… NVIDIA DLSS 3 is a neural graphics technology that multiplies performance using AI image reconstruction and frame generation. It’s a combination of three core…
NVIDIA DLSS 3 is a neural graphics technology that multiplies performance using AI image reconstruction and frame generation. It’s a combination of three core…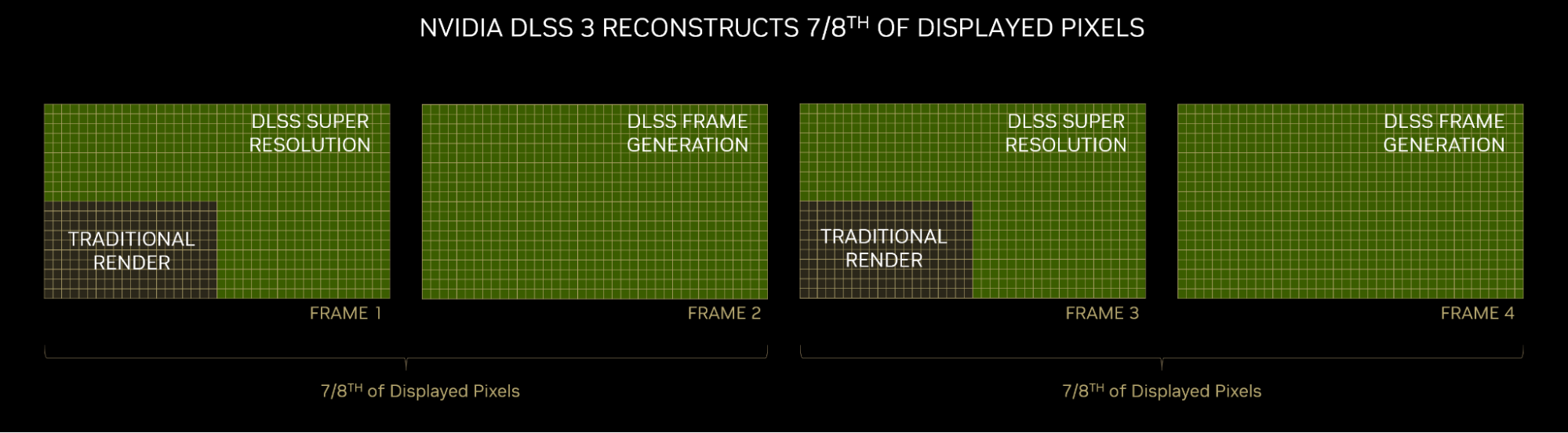
 Learn how financial firms can build automated, real-time fraud and threat detection solutions with NVIDIA Morpheus.
Learn how financial firms can build automated, real-time fraud and threat detection solutions with NVIDIA Morpheus. The analysis of 3D medical images is crucial for advancing clinical responses, disease tracking, and overall patient survival. Deep learning models form the…
The analysis of 3D medical images is crucial for advancing clinical responses, disease tracking, and overall patient survival. Deep learning models form the…