 Join these upcoming workshops to learn how to train large neural networks, or build a conversational AI pipeline.
Join these upcoming workshops to learn how to train large neural networks, or build a conversational AI pipeline.
Join these upcoming workshops to learn how to train large neural networks, or build a conversational AI pipeline.
 DataBloom
DataBloomJoin these upcoming workshops to learn how to train large neural networks, or build a conversational AI pipeline.
Join these upcoming workshops to learn how to train large neural networks, or build a conversational AI pipeline.
The recent progress in generative AI unlocked the possibility of creating new content in several different domains, including text, vision and audio. These models often rely on the fact that raw data is first converted to a compressed format as a sequence of tokens. In the case of audio, neural audio codecs (e.g., SoundStream or EnCodec) can efficiently compress waveforms to a compact representation, which can be inverted to reconstruct an approximation of the original audio signal. Such a representation consists of a sequence of discrete audio tokens, capturing the local properties of sounds (e.g., phonemes) and their temporal structure (e.g., prosody). By representing audio as a sequence of discrete tokens, audio generation can be performed with Transformer-based sequence-to-sequence models — this has unlocked rapid progress in speech continuation (e.g., with AudioLM), text-to-speech (e.g., with SPEAR-TTS), and general audio and music generation (e.g., AudioGen and MusicLM). Many generative audio models, including AudioLM, rely on auto-regressive decoding, which produces tokens one by one. While this method achieves high acoustic quality, inference (i.e., calculating an output) can be slow, especially when decoding long sequences.
To address this issue, in “SoundStorm: Efficient Parallel Audio Generation”, we propose a new method for efficient and high-quality audio generation. SoundStorm addresses the problem of generating long audio token sequences by relying on two novel elements: 1) an architecture adapted to the specific nature of audio tokens as produced by the SoundStream neural codec, and 2) a decoding scheme inspired by MaskGIT, a recently proposed method for image generation, which is tailored to operate on audio tokens. Compared to the autoregressive decoding approach of AudioLM, SoundStorm is able to generate tokens in parallel, thus decreasing the inference time by 100x for long sequences, and produces audio of the same quality and with higher consistency in voice and acoustic conditions. Moreover, we show that SoundStorm, coupled with the text-to-semantic modeling stage of SPEAR-TTS, can synthesize high-quality, natural dialogues, allowing one to control the spoken content (via transcripts), speaker voices (via short voice prompts) and speaker turns (via transcript annotations), as demonstrated by the examples below:
| Input: Text (transcript used to drive the audio generation in bold) | Something really funny happened to me this morning. | Oh wow, what? | Well, uh I woke up as usual. | Uhhuh | Went downstairs to have uh breakfast. | Yeah | Started eating. Then uh 10 minutes later I realized it was the middle of the night. | Oh no way, that’s so funny! | I didn’t sleep well last night. | Oh, no. What happened? | I don’t know. I I just couldn’t seem to uh to fall asleep somehow, I kept tossing and turning all night. | That’s too bad. Maybe you should uh try going to bed earlier tonight or uh maybe you could try reading a book. | Yeah, thanks for the suggestions, I hope you’re right. | No problem. I I hope you get a good night’s sleep | ||
| Input: Audio prompt |
|
|
||
| Output: Audio prompt + generated audio |
|
|
In our previous work on AudioLM, we showed that audio generation can be decomposed into two steps: 1) semantic modeling, which generates semantic tokens from either previous semantic tokens or a conditioning signal (e.g., a transcript as in SPEAR-TTS, or a text prompt as in MusicLM), and 2) acoustic modeling, which generates acoustic tokens from semantic tokens. With SoundStorm we specifically address this second, acoustic modeling step, replacing slower autoregressive decoding with faster parallel decoding.
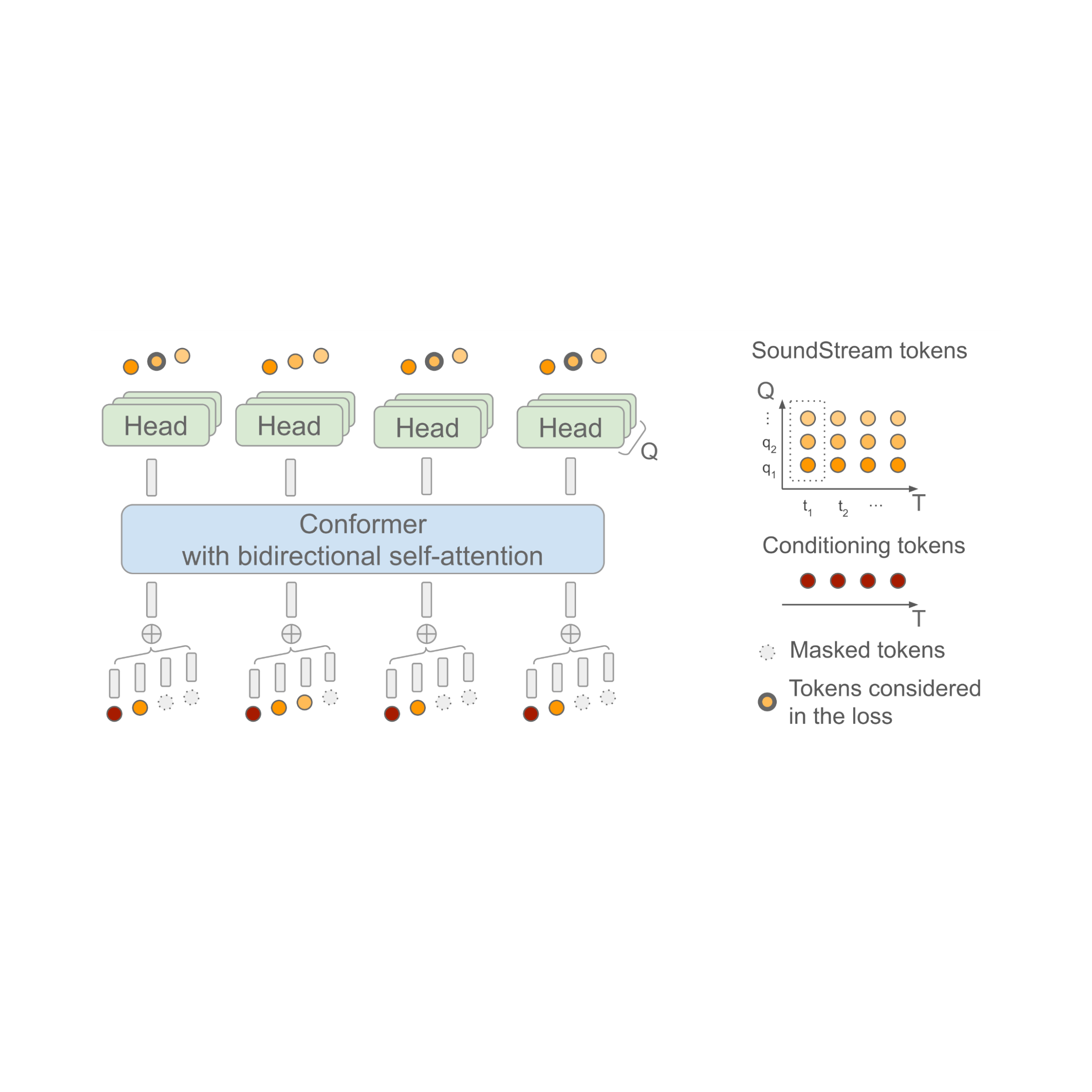
SoundStorm relies on a bidirectional attention-based Conformer, a model architecture that combines a Transformer with convolutions to capture both local and global structure of a sequence of tokens. Specifically, the model is trained to predict audio tokens produced by SoundStream given a sequence of semantic tokens generated by AudioLM as input. When doing this, it is important to take into account the fact that, at each time step t, SoundStream uses up to Q tokens to represent the audio using a method known as residual vector quantization (RVQ), as illustrated below on the right. The key intuition is that the quality of the reconstructed audio progressively increases as the number of generated tokens at each step goes from 1 to Q.
At inference time, given the semantic tokens as input conditioning signal, SoundStorm starts with all audio tokens masked out, and fills in the masked tokens over multiple iterations, starting from the coarse tokens at RVQ level q = 1 and proceeding level-by-level with finer tokens until reaching level q = Q.
There are two crucial aspects of SoundStorm that enable fast generation: 1) tokens are predicted in parallel during a single iteration within a RVQ level and, 2) the model architecture is designed in such a way that the complexity is only mildly affected by the number of levels Q. To support this inference scheme, during training a carefully designed masking scheme is used to mimic the iterative process used at inference.
 |
| SoundStorm model architecture. T denotes the number of time steps and Q the number of RVQ levels used by SoundStream. The semantic tokens used as conditioning are time-aligned with the SoundStream frames. |
We demonstrate that SoundStorm matches the quality of AudioLM’s acoustic generator, replacing both AudioLM’s stage two (coarse acoustic model) and stage three (fine acoustic model). Furthermore, SoundStorm produces audio 100x faster than AudioLM’s hierarchical autoregressive acoustic generator (top half below) with matching quality and improved consistency in terms of speaker identity and acoustic conditions (bottom half below).
 |
| Runtimes of SoundStream decoding, SoundStorm and different stages of AudioLM on a TPU-v4. |
 |
| Acoustic consistency between the prompt and the generated audio. The shaded area represents the inter-quartile range. |
We acknowledge that the audio samples produced by the model may be influenced by the unfair biases present in the training data, for instance in terms of represented accents and voice characteristics. In our generated samples, we demonstrate that we can reliably and responsibly control speaker characteristics via prompting, with the goal of avoiding unfair biases. A thorough analysis of any training data and its limitations is an area of future work in line with our responsible AI Principles.
In turn, the ability to mimic a voice can have numerous malicious applications, including bypassing biometric identification and using the model for the purpose of impersonation. Thus, it is crucial to put in place safeguards against potential misuse: to this end, we have verified that the audio generated by SoundStorm remains detectable by a dedicated classifier using the same classifier as described in our original AudioLM paper. Hence, as a component of a larger system, we believe that SoundStorm would be unlikely to introduce additional risks to those discussed in our earlier papers on AudioLM and SPEAR-TTS. At the same time, relaxing the memory and computational requirements of AudioLM would make research in the domain of audio generation more accessible to a wider community. In the future, we plan to explore other approaches for detecting synthesized speech, e.g., with the help of audio watermarking, so that any potential product usage of this technology strictly follows our responsible AI Principles.
We have introduced SoundStorm, a model that can efficiently synthesize high-quality audio from discrete conditioning tokens. When compared to the acoustic generator of AudioLM, SoundStorm is two orders of magnitude faster and achieves higher temporal consistency when generating long audio samples. By combining a text-to-semantic token model similar to SPEAR-TTS with SoundStorm, we can scale text-to-speech synthesis to longer contexts and generate natural dialogues with multiple speaker turns, controlling both the voices of the speakers and the generated content. SoundStorm is not limited to generating speech. For example, MusicLM uses SoundStorm to synthesize longer outputs efficiently (as seen at I/O).
The work described here was authored by Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour and Marco Tagliasacchi. We are grateful for all discussions and feedback on this work that we received from our colleagues at Google.
 The Speech AI Summit is an annual conference that brings together experts in the field of AI and speech technology to discuss the latest industry trends and…
The Speech AI Summit is an annual conference that brings together experts in the field of AI and speech technology to discuss the latest industry trends and…
The Speech AI Summit is an annual conference that brings together experts in the field of AI and speech technology to discuss the latest industry trends and advancements. This post summarizes the top questions asked during Overview of Zero-Shot Multi-Speaker TTS System, a recorded talk from the 2022 summit featuring Coqui.ai.
Text-to-speech (TTS) systems have significantly advanced in recent years with deep learning approaches. These advances have motivated research that aims to synthesize speech into the voice of a target speaker using just a few seconds of speech. This approach is called zero-shot multi-speaker TTS. The Coqui.ai session explored the timeline and state-of-the-art technology behind this approach.
Here are some key takeaways from the session:
Can you create entirely brand new voices? Are there benefits to zero-shot to consider over one-minute fine-tuning? What are the hardware requirements to train a TTS model? Edresson Casanova dives into the top questions for developing zero-shot multi-speaker TTS systems.
How is text-to-speech quality measured?
Generally, the quality and naturalness of a TTS system are evaluated using the mean opinion score (MOS). With this metric, human evaluators listen to the audio and give a score on a scale between one and five, with one indicating bad quality and five indicating excellent quality.
In zero-shot multi-speaker TTS systems, you must also evaluate the similarity for new speakers by using a similarity MOS. In addition, a speaker encoder is used to measure speaker similarity. Compute the speaker encoder cosine similarity (SECS) where the speakers’ embeddings for two audio samples are extracted, and the cosine similarity between these embeddings is computed.
Researchers have recently published papers that explore the use of artificial neural networks to predict the MOS. At present, the generalization of these systems is not good enough, especially for new recording conditions, such as a different microphone or noise environment.
Can speech-to-text systems be used to measure text-to-speech system quality?
Speech-to-text (STT) systems can be used to check if the TTS model’s pronunciation is right, but it is not so much used in literature. Evaluation with an STT model covers only pronunciation and not the quality aspects of the speech itself.
What is the benefit of zero-shot compared to one-minute fine-tuning?
Zero-shot can work well, but not always. In some recordings, conditions and voices are too different from those seen in training. The zero-shot can fail and produce a voice not as similar to the target speaker’s voice. In this case, one-minute fine-tuning can be used. The YourTTS paper shows that the model can learn voices well, even for voices where the model has had a bad zero-shot.
How important is the architecture of the speaker encoder? Do you suggest training the speaker encoder separately or along with the spectrogram generator?
The speaker encoder is one of the most important components for the final quality of zero-shot multi-speaker TTS models. Without good speaker embeddings, the model can’t clone new voices. The speaker encoder used on the YourTTS model was pretrained separately on thousands of speakers, and it was kept frozen during the training.
Some papers—such as Attentron: Few-Shot Text-to-Speech Utilizing Attention-Based Variable-Length Embedding—show that training a speaker encoder-like module along with the TTS model could produce good results. In my experience, it depends on how many speakers you have in the training set. Without adequate speaker diversity, the model easily overfits and does not work well with speakers or recording conditions not seen in training.
Is it possible to interpolate speaker encoder representation to create an unseen voice as a mix of known voices?
It is possible. It is also able to generate new artificial voices through a random speaker embedding. Although the YourTTS colab demos do not cover it, the SC-GlowTTS colab demo shows an example of how to generate a completely new artificial voice.
Are models phoneme-based or character-based for training?
YourTTS is character-based. However, for example, Sc-GlowTTS is phoneme-based. On YourTTS, we decided to train it using characters instead of phonemes because the objective of this model is to be used in low-resource languages that normally do not have good phonemizers.
How much data center compute is required to train your leading text-to-speech model?
YourTTS used one NVIDIA V100 32-GB GPU with a batch size of 64. However, it is possible to train it with a smaller batch size using GPUs with less VRAM. I have never tried a GPU with less VRAM, but I know that some Coqui TTS contributors have already fine-tuned the YourTTS model using GPUs with 11 GB of VRAM.
When computing the speaker embeddings, does it help to exclude certain segments from embedding extraction like silence or unvoiced or plosive phonemes?
Although the speaker encoder should learn how to ignore the silences and focus just on speech, during the dataset preprocessing step, we removed beginning and end long silences to avoid problems during the model training. Then, we removed long silences. However, we do not remove unvoiced or plosive phonemes segments.
Can zero-shot text-to-speech be achieved for expressive speech?
It can be achieved. At Coqui.ai, we have already developed a model that can do zero-shot multi-speaker TTS and generates expressive speech in five different emotions. This model is available through Coqui Studio.
From fine-tuning a model to generating a custom voice, speech AI technology helps organizations tackle complex conversations globally. Check out the following resources to learn how your organization can integrate speech AI into core operations.
 In the era of big data and distributed computing, traditional approaches to machine learning (ML) face a significant challenge: how to train models…
In the era of big data and distributed computing, traditional approaches to machine learning (ML) face a significant challenge: how to train models…
In the era of big data and distributed computing, traditional approaches to machine learning (ML) face a significant challenge: how to train models collaboratively when data is decentralized across multiple devices or silos. This is where federated learning comes into play, offering a promising solution that decouples model training from direct access to raw training data.
One of the key advantages of federated learning, which was initially designed to enable collaborative deep learning on decentralized data, is its communication efficiency. This same paradigm can be applied to traditional ML methods such as linear regression, SVM, k-means clustering, and tree-based methods like random forest and boosting.
Developing a federated-learning variant of traditional ML methods requires careful considerations that must be made at several levels:
It’s worth noting that the line between federated and distributed machine learning can be less distinct for traditional methods compared to deep learning. For some algorithms and implementations, these terms can be equivalent.
In Figure 1, each client builds a unique boosted tree that is aggregated by the server as a collection of trees and then redistributed to clients for further training.
To get started with a specific example that shows this approach, consider the k-means clustering example. Here we followed the scheme defined in Mini-Batch K-Means clustering and formulated each round of federated learning as follows:
For center initialization, at the first round, each client generates its initial centers with the k-means++ method. Then, the server collects all initial centers and performs one round of k-means to generate the initial global center.
Applying a federated paradigm to traditional machine learning methods is easier said than done. The new NVIDIA whitepaper, Federated Traditional Machine Learning Algorithms, provides numerous detailed examples to show how to formulate and implement these algorithms.
Employing popular libraries like scikit-learn and XGBoost, we showcase how federated linear models, k-means clustering, non-linear SVM, random forest, and XGBoost can be adapted for collaborative learning.
In conclusion, federated machine learning offers a compelling approach to training models collaboratively on decentralized data. While communication costs may no longer be the principal constraint for traditional machine learning algorithms, careful formulation and implementation are still necessary to fully leverage the benefits of federated learning.
To get started with your own federated machine learning workflows, see the Federated Traditional Machine Learning Algorithms whitepaper and the NVIDIA FLARE GitHub repo.
Detecting delirium isn’t easy, but it can have a big payoff: speeding essential care to patients, leading to quicker and surer recovery. Improved detection also reduces the need for long-term skilled care, enhancing the quality of life for patients while decreasing a major financial burden. In the U.S., caring for those suffering from delirium costs Read article >
Conquer the lands in Microsoft’s award-winning Age of Empires III: Definitive Edition. It leads 10 new games supported today on GeForce NOW. At Your Command Age of Empires III: Definitive Edition is a remaster of one of the most beloved real-time strategy franchises featuring improved visuals, enhanced gameplay, cross-platform multiplayer and more. Command mighty civilizations Read article >
Google’s AI for Social Good team consists of researchers, engineers, volunteers, and others with a shared focus on positive social impact. Our mission is to demonstrate AI’s societal benefit by enabling real-world value, with projects spanning work in public health, accessibility, crisis response, climate and energy, and nature and society. We believe that the best way to drive positive change in underserved communities is by partnering with change-makers and the organizations they serve.
In this blog post we discuss work done by Project Euphonia, a team within AI for Social Good, that aims to improve automatic speech recognition (ASR) for people with disordered speech. For people with typical speech, an ASR model’s word error rate (WER) can be less than 10%. But for people with disordered speech patterns, such as stuttering, dysarthria and apraxia, the WER could reach 50% or even 90% depending on the etiology and severity. To help address this problem, we worked with more than 1,000 participants to collect over 1,000 hours of disordered speech samples and used the data to show that ASR personalization is a viable avenue for bridging the performance gap for users with disordered speech. We’ve shown that personalization can be successful with as little as 3-4 minutes of training speech using layer freezing techniques.
This work led to the development of Project Relate for anyone with atypical speech who could benefit from a personalized speech model. Built in partnership with Google’s Speech team, Project Relate enables people who find it hard to be understood by other people and technology to train their own models. People can use these personalized models to communicate more effectively and gain more independence. To make ASR more accessible and usable, we describe how we fine-tuned Google’s Universal Speech Model (USM) to better understand disordered speech out of the box, without personalization, for use with digital assistant technologies, dictation apps, and in conversations.
Working closely with Project Relate users, it became clear that personalized models can be very useful, but for many users, recording dozens or hundreds of examples can be challenging. In addition, the personalized models did not always perform well in freeform conversation.
To address these challenges, Euphonia’s research efforts have been focusing on speaker independent ASR (SI-ASR) to make models work better out of the box for people with disordered speech so that no additional training is necessary.
The first step in building a robust SI-ASR model was to create representative dataset splits. We created the Prompted Speech dataset by splitting the Euphonia corpus into train, validation and test portions, while ensuring that each split spanned a range of speech impairment severity and underlying etiology and that no speakers or phrases appeared in multiple splits. The training portion consists of over 950k speech utterances from over 1,000 speakers with disordered speech. The test set contains around 5,700 utterances from over 350 speakers. Speech-language pathologists manually reviewed all of the utterances in the test set for transcription accuracy and audio quality.
Unprompted or conversational speech differs from prompted speech in several ways. In conversation, people speak faster and enunciate less. They repeat words, repair misspoken words, and use a more expansive vocabulary that is specific and personal to themselves and their community. To improve a model for this use case, we created the Real Conversation test set to benchmark performance.
The Real Conversation test set was created with the help of trusted testers who recorded themselves speaking during conversations. The audio was reviewed, any personally identifiable information (PII) was removed, and then that data was transcribed by speech-language pathologists. The Real Conversation test set contains over 1,500 utterances from 29 speakers.
We then tuned USM on the training split of the Euphonia Prompted Speech set to improve its performance on disordered speech. Instead of fine-tuning the full model, our tuning was based on residual adapters, a parameter-efficient tuning approach that adds tunable bottleneck layers as residuals between the transformer layers. Only these layers are tuned, while the rest of the model weights are untouched. We have previously shown that this approach works very well to adapt ASR models to disordered speech. Residual adapters were only added to the encoder layers, and the bottleneck dimension was set to 64.
To evaluate the adapted USM, we compared it to older ASR models using the two test sets described above. For each test, we compare adapted USM to the pre-USM model best suited to that task: (1) For short prompted speech, we compare to Google’s production ASR model optimized for short form ASR; (2) for longer Real Conversation speech, we compare to a model trained for long form ASR. USM improvements over pre-USM models can be explained by USM’s relative size increase, 120M to 2B parameters, and other improvements discussed in the USM blog post.
 |
| Model word error rates (WER) for each test set (lower is better). |
We see that the USM adapted with disordered speech significantly outperforms the other models. The adapted USM’s WER on Real Conversation is 37% better than the pre-USM model, and on the Prompted Speech test set, the adapted USM performs 53% better.
These findings suggest that the adapted USM is significantly more usable for an end user with disordered speech. We can demonstrate this improvement by looking at transcripts of Real Conversation test set recordings from a trusted tester of Euphonia and Project Relate (see below).
| Audio1 | Ground Truth | Pre-USM ASR | Adapted USM | |||
| I now have an Xbox adaptive controller on my lap. | i now have a lot and that consultant on my mouth | i now had an xbox adapter controller on my lamp. | ||||
| I’ve been talking for quite a while now. Let’s see. | quite a while now | i’ve been talking for quite a while now. |
| Example audio and transcriptions of a trusted tester’s speech from the Real Conversation test set. |
A comparison of the Pre-USM and adapted USM transcripts revealed some key advantages:
We believe that this work is an important step towards making speech recognition more accessible to people with disordered speech. We are continuing to work on improving the performance of our models. With the rapid advancements in ASR, we aim to ensure people with disordered speech benefit as well.
Key contributors to this project include Fadi Biadsy, Michael Brenner, Julie Cattiau, Richard Cave, Amy Chung-Yu Chou, Dotan Emanuel, Jordan Green, Rus Heywood, Pan-Pan Jiang, Anton Kast, Marilyn Ladewig, Bob MacDonald, Philip Nelson, Katie Seaver, Joel Shor, Jimmy Tobin, Katrin Tomanek, and Subhashini Venugopalan. We gratefully acknowledge the support Project Euphonia received from members of the USM research team including Yu Zhang, Wei Han, Nanxin Chen, and many others. Most importantly, we wanted to say a huge thank you to the 2,200+ participants who recorded speech samples and the many advocacy groups who helped us connect with these participants.
1Audio volume has been adjusted for ease of listening, but the original files would be more consistent with those used in training and would have pauses, silences, variable volume, etc. ↩
 Learn how Vision Transformers are revolutionizing AI applications with image understanding and analysis.
Learn how Vision Transformers are revolutionizing AI applications with image understanding and analysis.
Learn how Vision Transformers are revolutionizing AI applications with image understanding and analysis.
 For HPC clusters purposely built for AI training, such as the NVIDIA DGX BasePOD and NVIDIA DGX SuperPOD, fine-tuning the cluster is critical to increasing and…
For HPC clusters purposely built for AI training, such as the NVIDIA DGX BasePOD and NVIDIA DGX SuperPOD, fine-tuning the cluster is critical to increasing and…
For HPC clusters purposely built for AI training, such as the NVIDIA DGX BasePOD and NVIDIA DGX SuperPOD, fine-tuning the cluster is critical to increasing and optimizing the overall performance of the cluster. This includes fine-tuning the overall performance of the Ethernet fabric, storage fabric, and the compute fabric.
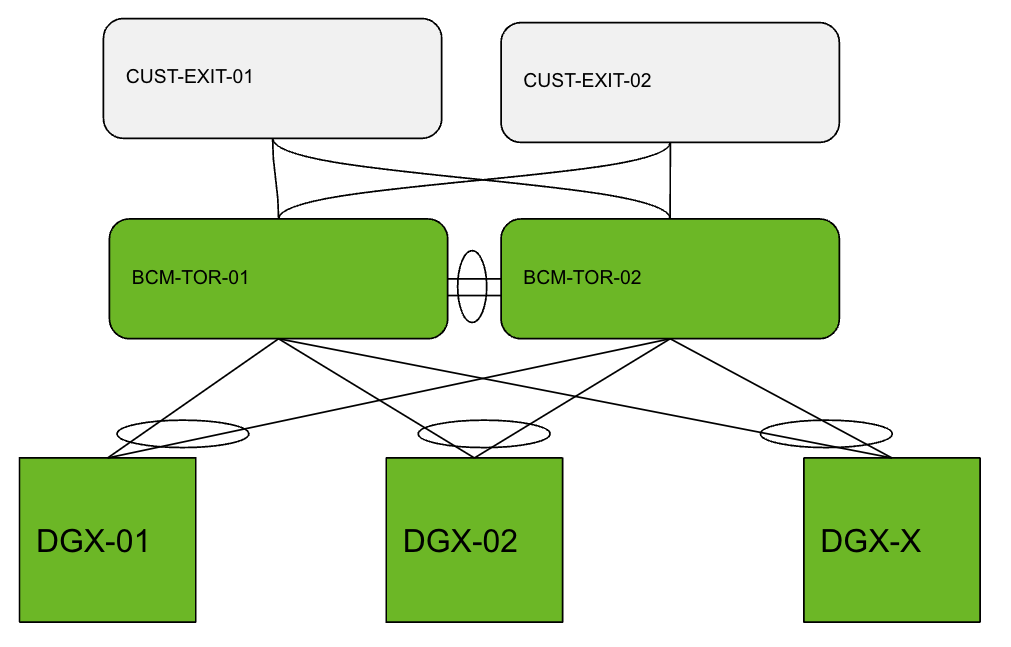
This post discusses how to maximize the overall throughput of the Ethernet fabric with Multi-Chassis Link Aggregation (MLAG), available on NVIDIA Cumulus Linux. MLAG enables two separate switches to advertise the same LACP system ID to downstream hosts. As a result, the downstream hosts see the uplinks as if they are connected to a single LACP partner.
One benefit of using MLAG is physical switch-level redundancy. If either of the two uplink switches experiences a failure, downstream host traffic will not be impacted. A second benefit is that the uplinks of the aggregated bond are all used at the same time. Finally, MLAG technology provides gateway-level redundancy, using technologies such as VRR/VRRP.
To maximize the overall Ethernet performance of each of the DGX/compute nodes in a cluster, it is recommended to have bonded uplinks configured in LACP (802.1ad) mode. LACP (802.1ad) bonding mode enables both uplinks to be used at same time. Using other bond modes (such as active/standby, where only one of the two uplinks is being used at a given time) results in 50% of the uplink available bandwidth not being used at any given time.
LACP requires MLAG to be configured between the TOR switches. When configuring MLAG, gateway-level redundancy is also required using technologies such as VRR/VRRP.
For HPC cluster deployments, PXE booting is often used to provision the nodes in the cluster. For this reason, it is important to set up LACP-by-pass mode on the uplinks. Otherwise, the nodes would not be able to PXE boot without support for LACP during the provisioning process.
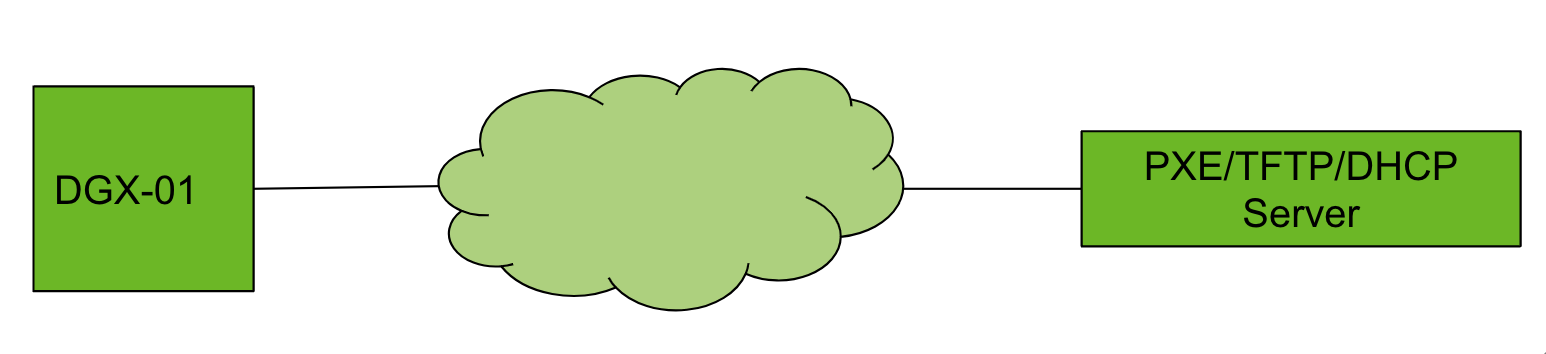
During the provisioning process, the host is configured to boot using one of its network interfaces. It obtains the IP address assignment and TFTP server information from the DHCP server. Once the TFTP server information is received from the DHCP server, the host contacts the TFTP server to retrieve the PXE booting/kickstart instructions for provisioning (Figure 2).
You can use the Cumulus Linux CLI interface (NVUE) to configure MLAG between BCM-TOR-01 and BCM-TOR-02 switches. This requires setting up the MLAG peer link member interfaces, MLAG mac-address, MLAG peer-ip, and MLAG priority on each member switch.
A switch with lower MLAG priority value becomes the primary switch for managing MLAG connectivity. A switch with higher MLAG priority value becomes the secondary switch. If no MLAG priority is set, then a default priority value of 32,768 is set.
To add MLAG configurations to BCM-TOR-01, use the following configurations:
cumulus@BCM-TOR-01:~$ nv set interface peerlink bond member swp61-62
cumulus@BCM-TOR-01:~$ nv set mlag mac-address 44:38:39:BE:EF:AA
cumulus@BCM-TOR-01:~$ nv set mlag backup 192.168.200.3 vrf mgmt
cumulus@BCM-TOR-01:~$ nv set mlag peer-ip linklocal
cumulus@BCM-TOR-01:~$ nv set mlag priority 2084
cumulus@BCM-TOR-01:~$ nv config apply
cumulus@BCM-TOR-01:~$ nv config save
To add MLAG configurations to BCM-TOR-02, use the following configurations:
cumulus@BCM-TOR-02:~$ nv set interface peerlink bond member swp61-62
cumulus@BCM-TOR-02:~$ nv set mlag mac-address 44:38:39:BE:EF:AA
cumulus@BCM-TOR-02:~$ nv set mlag backup 192.168.200.2
cumulus@BCM-TOR-02:~$ nv set mlag peer-ip linklocal
cumulus@BCM-TOR-02:~$ nv config apply
cumulus@BCM-TOR-02:~$ nv config save
To verify MLAG state on BCM-TOR-01, use the following command:
cumulus@BCM-TOR-01:mgmt:~$ net show clag
The peer is alive
Our Priority, ID, and Role: 2084 48:b0:2d:ad:49:8c primary
Peer Priority, ID, and Role: 32768 48:b0:2d:5f:4d:d0 secondary
Peer Interface and IP: peerlink.4094 fe80::4ab0:2dff:fe5f:4dd0 (linklocal)
Backup IP: 192.168.200.3 vrf mgmt (active)
System MAC: 44:38:39:be:ef:aa
cumulus@BCM-TOR-01:mgmt:~$To verify MLAG state on BCM-TOR-02, use the following command:
cumulus@BCM-TOR-02:mgmt:~$ net show clag
The peer is alive
Our Priority, ID, and Role: 32768 48:b0:2d:5f:4d:d0 secondary
Peer Priority, ID, and Role: 2084 48:b0:2d:ad:49:8c primary
Peer Interface and IP: peerlink.4094 fe80::4ab0:2dff:fead:498c (linklocal)
Backup IP: 192.168.200.2 vrf mgmt (active)
System MAC: 44:38:39:be:ef:aa
cumulus@BCM-TOR-02:mgmt:~$
You can use the Cumulus Linux CLI interface (NVUE) to configure bonded uplinks to interfaces going to DGX-01 and DGX-02 nodes. For each MLAG bond interface, you must define the bond name, the bond member interface, unique MLAG ID per bond, and bond description. You must also enable LACP-bypass mode for PXE booting purposes, configure the bond to be a L2 bond by forcing it to become a member of the bridge, and configure the native/untagged VLAN that would be used for PXE booting purposes.
To add interface bonding configurations to BCM-TOR-01, use the following configurations:
cumulus@BCM-TOR-01:~$ nv set interface bond1 bond member swp1
cumulus@BCM-TOR-01:~$ nv set interface bond1 bond mlag id 1
cumulus@BCM-TOR-01:~$ nv set interface bond1 bond lacp-bypass on
cumulus@BCM-TOR-01:~$ nv set interface bond1 description dgx01
cumulus@BCM-TOR-01:~$ nv set interface bond2 bond member swp2
cumulus@BCM-TOR-01:~$ nv set interface bond2 bond mlag id 2
cumulus@BCM-TOR-01:~$ nv set interface bond2 description dgx02
cumulus@BCM-TOR-01:~$ nv set interface bond2 bond lacp-bypass on
cumulus@BCM-TOR-01:~$ nv set interface bond1 bridge domain br_default
cumulus@BCM-TOR-01:~$ nv set interface bond2 bridge domain br_default
cumulus@BCM-TOR-01:~$ nv set interface bond1 bridge domain br_default untagged 222
cumulus@BCM-TOR-01:~$ nv set interface bond2 bridge domain br_default untagged 222
cumulus@BCM-TOR-01:~$ nv set bridge domain br_default vlan 221-223
cumulus@BCM-TOR-01:~$ nv config apply
cumulus@BCM-TOR-01:~$ nv config save
To add interface bonding configurations to BCM-TOR-02, use the following configurations:
cumulus@BCM-TOR-02:~$ nv set interface bond1 bond member swp1
cumulus@BCM-TOR-02:~$ nv set interface bond1 bond mlag id 1
cumulus@BCM-TOR-02:~$ nv set interface bond1 bond lacp-bypass on
cumulus@BCM-TOR-02:~$ nv set interface bond1 description dgx01
cumulus@BCM-TOR-02:~$ nv set interface bond2 bond member swp2
cumulus@BCM-TOR-02:~$ nv set interface bond2 bond mlag id 2
cumulus@BCM-TOR-02:~$ nv set interface bond2 bond lacp-bypass on
cumulus@BCM-TOR-02:~$ nv set interface bond2 description dgx02
cumulus@BCM-TOR-02:~$ nv set interface bond1 bridge domain br_default
cumulus@BCM-TOR-02:~$ nv set interface bond2 bridge domain br_default
cumulus@BCM-TOR-02:~$ nv set interface bond1 bridge domain br_default untagged 222
cumulus@BCM-TOR-02:~$ nv set interface bond2 bridge domain br_default untagged 222
cumulus@BCM-TOR-02:~$ nv set bridge domain br_default vlan 221-223
cumulus@BCM-TOR-02:~$ nv config apply
cumulus@BCM-TOR-02:~$ nv config save
network-admin@BCM-TOR-01:mgmt:~$ net show int bond1
Name MAC Speed MTU Mode
-- ------ ----------------- ----- ---- -------
UP bond1 1c:34:da:29:17:04 100G 9216 802.3ad
Bond Details
------------------ --------
Bond Mode: 802.3ad
Load Balancing: layer3+4
Minimum Links: 1
LACP Sys Priority:
LACP Rate: 1
LACP Bypass: Active
All VLANs on L2 Port
--------------------
221-223
Untagged
--------
222
cl-netstat counters
-------------------
RX_OK RX_ERR RX_DRP RX_OVR TX_OK TX_ERR TX_DRP TX_OVR
--------- ------ ------ ------ -------- ------ ------ ------
249728882 0 18 0 32865480 0 1 0
MLAG is a well-tested feature, used by many NVIDIA customers. It can help provide physical switch-level redundancy, avoid single-point failure, and maximize overall utilization of the total available bandwidth in your Ethernet fabric. On the Ethernet networking side, NVIDIA Cumulus Linux is an industry-leading open network OS used by many Fortune 100 organizations. For more information about how NVIDIA deploys large-scale clusters, check out NVIDIA DGX SuperPOD and NVIDIA DGX BasePOD.

Imagine you’re shown two identical objects and then asked to close your eyes. When you open your eyes, you see the same two objects in the same position. How can you determine if they have been swapped back and forth? Intuition and the laws of quantum mechanics agree: If the objects are truly identical, there is no way to tell.
While this sounds like common sense, it only applies to our familiar three-dimensional world. Researchers have predicted that for a special type of particle, called an anyon, that is restricted to move only in a two-dimensional (2D) plane, quantum mechanics allows for something quite different. Anyons are indistinguishable from one another and some, non-Abelian anyons, have a special property that causes observable differences in the shared quantum state under exchange, making it possible to tell when they have been exchanged, despite being fully indistinguishable from one another. While researchers have managed to detect their relatives, Abelian anyons, whose change under exchange is more subtle and impossible to directly detect, realizing “non-Abelian exchange behavior” has proven more difficult due to challenges with both control and detection.
In “Non-Abelian braiding of graph vertices in a superconducting processor”, published in Nature, we report the observation of this non-Abelian exchange behavior for the first time. Non-Abelian anyons could open a new avenue for quantum computation, in which quantum operations are achieved by swapping particles around one another like strings are swapped around one another to create braids. Realizing this new exchange behavior on our superconducting quantum processor could be an alternate route to so-called topological quantum computation, which benefits from being robust against environmental noise.
In order to understand how this strange non-Abelian behavior can occur, it’s helpful to consider an analogy with the braiding of two strings. Take two identical strings and lay them parallel next to one another. Swap their ends to form a double-helix shape. The strings are identical, but because they wrap around one another when the ends are exchanged, it is very clear when the two ends are swapped.
The exchange of non-Abelian anyons can be visualized in a similar way, where the strings are made from extending the particles’ positions into the time dimension to form “world-lines.” Imagine plotting two particles’ locations vs. time. If the particles stay put, the plot would simply be two parallel lines, representing their constant locations. But if we exchange the locations of the particles, the world lines wrap around one another. Exchange them a second time, and you’ve made a knot.
While a bit difficult to visualize, knots in four dimensions (three spatial plus one time dimension) can always easily be undone. They are trivial — like a shoelace, simply pull one end and it unravels. But when the particles are restricted to two spatial dimensions, the knots are in three total dimensions and — as we know from our everyday 3D lives — cannot always be easily untied. The braiding of the non-Abelian anyons’ world lines can be used as quantum computing operations to transform the state of the particles.
A key aspect of non-Abelian anyons is “degeneracy”: the full state of several separated anyons is not completely specified by local information, allowing the same anyon configuration to represent superpositions of several quantum states. Winding non-Abelian anyons about each other can change the encoded state.
So how do we realize non-Abelian braiding with one of Google’s quantum processors? We start with the familiar surface code, which we recently used to achieve a milestone in quantum error correction, where qubits are arranged on the vertices of a checkerboard pattern. Each color square of the checkerboard represents one of two possible joint measurements that can be made of the qubits on the four corners of the square. These so-called “stabilizer measurements” can return a value of either + or – 1. The latter is referred to as a plaquette violation, and can be created and moved diagonally — just like bishops in chess — by applying single-qubit X- and Z-gates. Recently, we showed that these bishop-like plaquette violations are Abelian anyons. In contrast to non-Abelian anyons, the state of Abelian anyons changes only subtly when they are swapped — so subtly that it is impossible to directly detect. While Abelian anyons are interesting, they do not hold the same promise for topological quantum computing that non-Abelian anyons do.
To produce non-Abelian anyons, we need to control the degeneracy (i.e., the number of wavefunctions that causes all stabilizer measurements to be +1). Since a stabilizer measurement returns two possible values, each stabilizer cuts the degeneracy of the system in half, and with sufficiently many stabilizers, only one wave function satisfies the criterion. Hence, a simple way to increase the degeneracy is to merge two stabilizers together. In the process of doing so, we remove one edge in the stabilizer grid, giving rise to two points where only three edges intersect. These points, referred to as “degree-3 vertices” (D3Vs), are predicted to be non-Abelian anyons.
In order to braid the D3Vs, we have to move them, meaning that we have to stretch and squash the stabilizers into new shapes. We accomplish this by implementing two-qubit gates between the anyons and their neighbors (middle and right panels shown below).
 |
| Non-Abelian anyons in stabilizer codes. a: Example of a knot made by braiding two anyons’ world lines. b: Single-qubit gates can be used to create and move stabilizers with a value of –1 (red squares). Like bishops in chess, these can only move diagonally and are therefore constrained to one sublattice in the regular surface code. This constraint is broken when D3Vs (yellow triangles) are introduced. c: Process to form and move D3Vs (predicted to be non-Abelian anyons). We start with the surface code, where each square corresponds to a joint measurement of the four qubits on its corners (left panel). We remove an edge separating two neighboring squares, such that there is now a single joint measurement of all six qubits (middle panel). This creates two D3Vs, which are non-Abelian anyons. We move the D3Vs by applying two-qubit gates between neighboring sites (right panel). |
Now that we have a way to create and move the non-Abelian anyons, we need to verify their anyonic behavior. For this we examine three characteristics that would be expected of non-Abelian anyons:
We investigate fusion rules by studying how a pair of D3Vs interact with the bishop-like plaquette violations introduced above. In particular, we create a pair of these and bring one of them around a D3V by applying single-qubit gates.
While the rules of bishops in chess dictate that the plaquette violations can never meet, the dislocation in the checkerboard lattice allows them to break this rule, meet its partner and annihilate with it. The plaquette violations have now disappeared! But bring the non-Abelian anyons back in contact with one another, and the anyons suddenly morph into the missing plaquette violations. As weird as this behavior seems, it is a manifestation of exactly the fusion rules that we expect these entities to obey. This establishes confidence that the D3Vs are, indeed, non-Abelian anyons.
 |
| Demonstration of anyonic fusion rules (starting with panel I, in the lower left). We form and separate two D3Vs (yellow triangles), then form two adjacent plaquette violations (red squares) and pass one between the D3Vs. The D3Vs deformation of the “chessboard” changes the bishop rules of the plaquette violations. While they used to lie on adjacent squares, they are now able to move along the same diagonals and collide (as shown by the red lines). When they do collide, they annihilate one another. The D3Vs are brought back together and surprisingly morph into the missing adjacent red plaquette violations. |
After establishing the fusion rules, we want to see the real smoking gun of non-Abelian anyons: non-Abelian exchange statistics. We create two pairs of non-Abelian anyons, then braid them by wrapping one from each pair around each other (shown below). When we fuse the two pairs back together, two pairs of plaquette violations appear. The simple act of braiding the anyons around one another changed the observables of our system. In other words, if you closed your eyes while the non-Abelian anyons were being exchanged, you would still be able to tell that they had been exchanged once you opened your eyes. This is the hallmark of non-Abelian statistics.
 |
| Braiding non-Abelian anyons. We make two pairs of D3Vs (panel II), then bring one from each pair around each other (III-XI). When fusing the two pairs together again in panel XII, two pairs of plaquette violations appear! Braiding the non-Abelian anyons changed the observables of the system from panel I to panel XII; a direct manifestation of non-Abelian exchange statistics. |
Finally, after establishing their fusion rules and exchange statistics, we demonstrate how we can use these particles in quantum computations. The non-Abelian anyons can be used to encode information, represented by logical qubits, which should be distinguished from the actual physical qubits used in the experiment. The number of logical qubits encoded in N D3Vs can be shown to be N/2–1, so we use N=8 D3Vs to encode three logical qubits, and perform braiding to entangle them. By studying the resulting state, we find that the braiding has indeed led to the formation of the desired, well-known quantum entangled state called the Greenberger-Horne-Zeilinger (GHZ) state.
 |
| Using non-Abelian anyons as logical qubits. a, We braid the non-Abelian anyons to entangle three qubits encoded in eight D3Vs. b, Quantum state tomography allows for reconstructing the density matrix, which can be represented in a 3D bar plot and is found to be consistent with the desired highly entangled GHZ-state. |
Our experiments show the first observation of non-Abelian exchange statistics, and that braiding of the D3Vs can be used to perform quantum computations. With future additions, including error correction during the braiding procedure, this could be a major step towards topological quantum computation, a long-sought method to endow qubits with intrinsic resilience against fluctuations and noise that would otherwise cause errors in computations.
We would like to thank Katie McCormick, our Quantum Science Communicator, for helping to write this blog post.