Large Language Models (LLMs) and AI applications such as ChatGPT and DALL-E have recently seen rapid growth. Thanks to GPUs, CPUs, DPUs, high-speed storage, and…
Large Language Models (LLMs) and AI applications such as ChatGPT and DALL-E have recently seen rapid growth. Thanks to GPUs, CPUs, DPUs, high-speed storage, and…
Large Language Models (LLMs) and AI applications such as ChatGPT and DALL-E have recently seen rapid growth. Thanks to GPUs, CPUs, DPUs, high-speed storage, and AI-optimized software innovations, AI is now widely accessible. You can even deploy AI in the cloud or on-premises.
Yet AI applications can be very taxing on the network, and this growth is burdening CPU and GPU servers, as well as the existing underlying network infrastructure that connects these systems together.
Traditional Ethernet, while sufficient for handling mainstream and enterprise applications such as web and video or audio streaming, is not optimized to support the new generation of AI workloads. Traditional Ethernet is ideal for loosely coupled applications, low-bandwidth flows, and high jitter. It might be sufficient for heterogeneous traffic (such as web, video, or audio streaming; file transfers; and gaming) but is not ideal when oversubscription occurs.
Designed from the ground up to meet the performance demands for AI applications, NVIDIA Spectrum-X networking platform is an end-to-end solution that is optimized for high-speed network performance, low latency, and scale.
NVIDIA Spectrum-X
NVIDIA Spectrum-X networking platform was developed to address traditional Ethernet network limitations. It is a network fabric designed to answer the needs of demanding AI applications, intended for tightly coupled processes.
This NVIDIA-certified and tested end-to-end solution combines the best-in-class, AI-optimized networking hardware and software to provide a predictable, consistent, and uncompromising level of performance required by AI workloads.

NVIDIA Spectrum-X is a highly versatile technology that can be used with various AI applications. Specifically, it can significantly enhance the performance and efficiency of AI clusters in the following use cases:
- GPT and BERT LLMs
- Distributed training and parallel processing
- Natural language processing (NLP)
- Computer vision
- High-performance simulation (NVIDIA Omniverse and NVIDIA OVX)
- High-performance data analytics (Spark)
- Inference applications
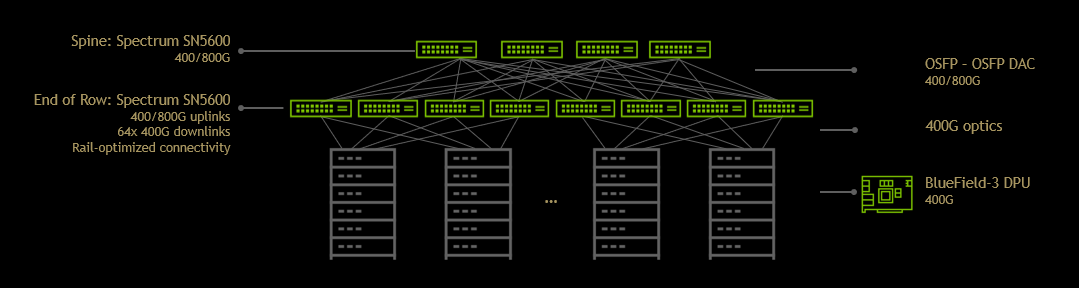
The two key elements of the NVIDIA Spectrum-X platform are the NVIDIA Spectrum-4 Ethernet switch and the NVIDIA BlueField-3 DPU.
NVIDIA Spectrum-4 Ethernet switch
NVIDIA Spectrum-4 Ethernet switch provides unprecedented application performance for AI clusters built on standards-based Ethernet. Realizing the full potential of NVIDIA Spectrum-4 requires an end-to-end, purpose-built network architecture. Only the NVIDIA Spectrum-X platform provides the hardware accelerators and offloads needed to power hyperscale AI.
NVIDIA Spectrum-4 Ethernet switches are built on the 51.2 Tbps Spectrum-4 ASIC, with 4x the bandwidth of the previous generation. It is the world’s first Ethernet AI switching platform. It was designed for AI workloads, combining specialized high-performance architecture with standard Ethernet connectivity.
NVIDIA Spectrum-4 offers:
- RoCE extensions: RoCE with unique enhancements
- RoCE Adaptive Routing
- RoCE Performance Isolation
- Simplified, Automated Adaptive Routing and RoCE Configurations
- Synchronized Collectives
- Other RoCE for HPC enhancements
- Highest effective bandwidth on Ethernet at scale
- Low latency with low jitter and short tail
- Deterministic performance and performance isolation
- Full stack and end-to-end optimization
- NVIDIA Cumulus Linux or SONiC

Key benefits of NVIDIA Spectrum-X with NVIDIA Spectrum-4 include the following:
- Using RoCE extension for AI and adaptive routing (AR) to achieve maximum NVIDIA Collective Communication Library (NCCL) performance.
- Leveraging performance isolation to ensure that in a multi-tenant and multi-job environment, one job does not impact the other.
- Ensuring that if there is a network component failure, the fabric continues to deliver the highest performance
- Synchronizing with BlueField-3 DPU to achieve optimal NCCL and AI performance
- Maintaining consistent and steady performance under various AI workloads, vital for achieving SLAs.
End-to-end optimal network performance
To build an effective AI compute fabric requires optimizing every part of the AI network, from DPUs to switches to networking software. Achieving the highest effective bandwidth at load and at scale demands using techniques such as RoCE adaptive routing and advanced congestion control mechanisms. Incorporating capabilities that work synchronously on NVIDIA BlueField-3 DPUs and Spectrum-4 switches is crucial to achieve the highest performance and reliability from the AI fabric.
RoCE adaptive routing
AI workloads and applications are characterized by a small number of elephant flows responsible for the large data movement between GPUs, where the tail latency highly impacts the overall application performance. Catering to such traffic patterns with traditional network routing mechanisms can lead to inconsistent and underutilized GPU performance for AI workloads.
RoCE adaptive routing is a fine-grained load balancing technology. It dynamically reroutes RDMA data to avoid congestion and provide optimal load balancing to achieve the highest effective data bandwidth.
It is an end-to-end capability that includes Spectrum-4 switches and BlueField-3 DPUs. The Spectrum-4 switches are responsible for selecting the least-congested port for data transmission on a per-packet basis. As different packets of the same flow travel through different paths of the network, they may arrive out of order to their destination. The BlueField-3 transforms any out-of-order data at the RoCE transport layer, transparently delivering in-order data to the application.
Spectrum-4 evaluates congestion based on egress queue loads, ensuring all ports are well-balanced. For every network packet, the switch selects the port with the minimal load over its egress queue. Spectrum-4 also receives status notifications from neighboring switches, which influence the routing decision. The queues evaluated are matched with the quality-of-service level.
As a result, NVIDIA Spectrum-X enables up to 95% effective bandwidth across the hyperscale system at load, and at scale.
RoCE congestion control
Applications running concurrently on hyperscale cloud systems may suffer from degraded performance and reproducible run-times due to network level congestion. This can be caused by the network traffic of the application itself, or background network traffic from other applications. The primary reason for this congestion is known as many-to-one congestion, where there are multiple data senders and a single data receiver.
Such congestion cannot be solved using adaptive routing and actually requires data-flow metering per endpoint. Congestion control is an end-to-end technology, where Spectrum-4 switches provide network telemetry information representing real time congestion data. This telemetry information is processed by the BlueField DPUs, which manage and control the data sender’s data injection rate, resulting in maximum efficiency of network sharing.
Without congestion control, many-to-one scenarios will cause network back-pressure and congestion spreading or even packet-drop, which dramatically degrade network and application performance.
In the congestion control process, BlueField-3 DPUs execute the congestion control algorithm. They handle millions of congestion control events per second in microsecond reaction latency and apply fine-grained rate decisions.
The Spectrum-4 switch in-band telemetry holds both queuing information for accurate congestion estimation, as well as port utilization indication for fast recovery. NVIDIA RoCE congestion control significantly improves congestion discovery and reaction time by enabling the telemetry data to bypass the congested flow queueing delay while still providing accurate and concurrent telemetry.
RoCE performance isolation
AI hyperscale and cloud infrastructures need to support a growing number of users (tenants) and parallel applications or workflows. These users and applications inadvertently compete on the infrastructure’s shared resources, such as the network, and therefore may impact performance.
The NVIDIA Spectrum-X platform includes mechanisms that, when combined, deliver performance isolation. It ensures that one workload cannot impact the performance of another. These mechanisms ensure that any workload cannot create network congestion that will impact data movement of another workload. The performance isolation mechanisms include quality of service isolation, RoCE adaptive routing for data path spreading, and RoCE congestion control.
The NVIDIA Spectrum-X platform features tight integration of software and hardware, enabling deeper understanding of AI workloads and traffic patterns. Such an infrastructure provides the capabilities to test with large workloads using a dedicated Ethernet AI cluster. By leveraging telemetry from Spectrum Ethernet switches and BlueField-3 DPUs, NVIDIA NetQ can detect network issues proactively and troubleshoot network issues faster for optimal use of network capacity.
The NVIDIA NetQ network validation and ASIC monitoring tool set provide visibility into the network health and behavior. The NetQ flow telemetry analysis shows the paths that data flows take as they traverse the network, providing network latency and performance insights.
Increased energy efficiency
Power capping has become a common practice in data centers due to the growing demand for computing resources and the need to control energy costs. The Spectrum-4 ASIC and optical innovations enable simplified network designs that improve performance per watt, achieving better efficiency and delivering faster AI insights, without exceeding network power budgets.
Summary
NVIDIA Spectrum-X networking platform is designed especially for demanding AI applications. With higher performance compared to traditional Ethernet, lower power consumption, lower TCO, full stack software-hardware integration, and massive scale, NVIDIA Spectrum-X is the ideal platform for running existing and future AI workloads.
Learn more
Looking for more information? Check out these resources:
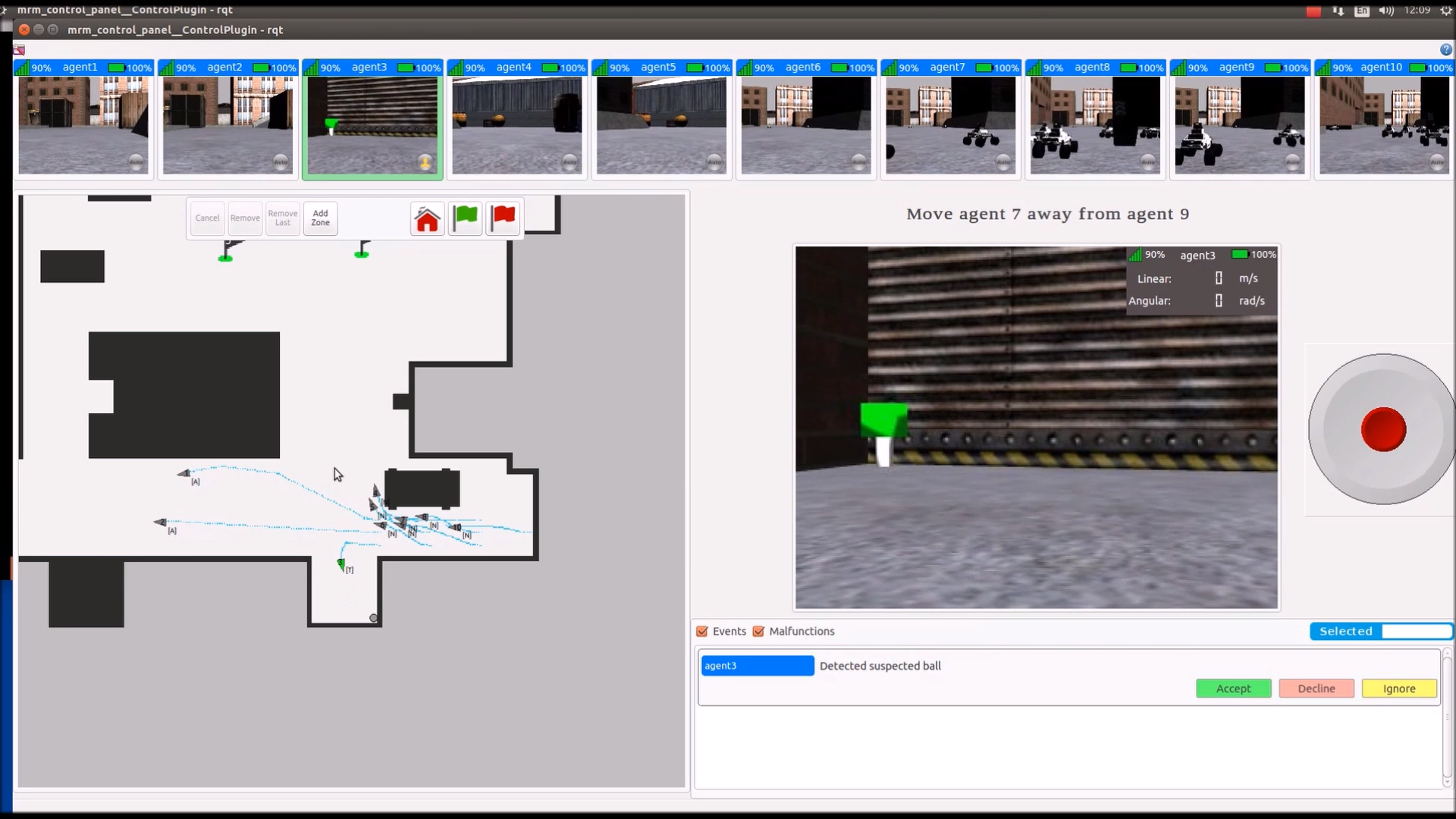
 The need for a high-fidelity multi-robot simulation environment is growing rapidly as more and more autonomous robots are being deployed in real-world…
The need for a high-fidelity multi-robot simulation environment is growing rapidly as more and more autonomous robots are being deployed in real-world…


 The telecom sector is transforming how communication happens. Striving to provide reliable, uninterrupted service, businesses are tackling the challenge of…
The telecom sector is transforming how communication happens. Striving to provide reliable, uninterrupted service, businesses are tackling the challenge of…