The U.S. National Oceanic and Atmospheric Administration has selected Lockheed Martin and NVIDIA to build a prototype system to accelerate outputs of Earth Environment Monitoring and their corresponding visualizations. Using AI techniques, such a system has the potential to reduce by an order of magnitude the amount of time necessary for the output of complex Read article >
Gaming in the living room is getting an upgrade with GeForce NOW. This GFN Thursday, kick off the weekend streaming GeForce NOW on Samsung TVs, with upcoming support for 4K resolution. Get started with the 10 new titles streaming this week. Plus, Yes by YTL Communications, a leading 5G provider in Malaysia, today announced it Read article >
NVIDIA today reported revenue for the third quarter ended October 30, 2022, of $5.93 billion, down 17% from a year ago and down 12% from the previous quarter.
Our trust in AI will largely depend on how well we understand it — explainable AI, or XAI, helps shine a flashlight into the “black box” of complexity in…
Our trust in AI will largely depend on how well we understand it — explainable AI, or XAI, helps shine a flashlight into the “black box” of complexity in AI models.
Posted by Yanqi Zhou, Research Scientist, Google Research Brain Team
The capacity of a neural network to absorb information is limited by the number of its parameters, and as a consequence, finding more effective ways to increase model parameters has become a trend in deep learning research. Mixture-of-experts (MoE), a type of conditional computation where parts of the network are activated on a per-example basis, has been proposed as a way of dramatically increasing model capacity without a proportional increase in computation. In sparsely-activated variants of MoE models (e.g., Switch Transformer, GLaM, V-MoE), a subset of experts is selected on a per-token or per-example basis, thus creating sparsity in the network. Such models have demonstrated better scaling in multiple domains and better retention capability in a continual learning setting (e.g., Expert Gate). However, a poor expert routing strategy can cause certain experts to be under-trained, leading to an expert being under or over-specialized.
In “Mixture-of-Experts with Expert Choice Routing”, presented at NeurIPS 2022, we introduce a novel MoE routing algorithm called Expert Choice (EC). We discuss how this novel approach can achieve optimal load balancing in an MoE system while allowing heterogeneity in token-to-expert mapping. Compared to token-based routing and other routing methods in traditional MoE networks, EC demonstrates very strong training efficiency and downstream task scores. Our method resonates with one of the vision for Pathways, which is to enable heterogeneous mixture-of-experts via Pathways MPMD (multi program, multi data) support.
Overview of MoE Routing
MoE operates by adopting a number of experts, each as a sub-network, and activating only one or a few experts for each input token. A gating network must be chosen and optimized in order to route each token to the most suited expert(s). Depending on how tokens are mapped to experts, MoE can be sparse or dense. Sparse MoE only selects a subset of experts when routing each token, reducing computational cost as compared to a dense MoE. For example, recent work has implemented sparse routing via k-means clustering, linear assignment to maximize token-expert affinities, or hashing. Google also recently announced GLaM and V-MoE, both of which advance the state of the art in natural language processing and computer vision via sparsely gated MoE with top-k token routing, demonstrating better performance scaling with sparsely activated MoE layers. Many of these prior works used a token choice routing strategy in which the routing algorithm picks the best one or two experts for each token.
Token Choice Routing. The routing algorithm picks the top-1 or top-2 experts with highest affinity scores for each token. The affinity scores can be trained together with model parameters.
The independent token choice approach often leads to an imbalanced load of experts and under-utilization. In order to mitigate this, previous sparsely gated networks introduced additional auxiliary losses as regularization to prevent too many tokens being routed to a single expert, but the effectiveness was limited. As a result, token choice routings need to overprovision expert capacity by a significant margin (2x–8x of the calculated capacity) to avoid dropping tokens when there is a buffer overflow.
In addition to load imbalance, most prior works allocate a fixed number of experts to each token using a top-k function, regardless of the relative importance of different tokens. We argue that different tokens should be received by a variable number of experts, conditioned on token importance or difficulty.
Expert Choice Routing
To address the above issues, we propose a heterogeneous MoE that employs the expert choice routing method illustrated below. Instead of having tokens select the top-k experts, the experts with predetermined buffer capacity are assigned to the top-k tokens. This method guarantees even load balancing, allows a variable number of experts for each token, and achieves substantial gains in training efficiency and downstream performance. EC routing speeds up training convergence by over 2x in an 8B/64E (8 billion activated parameters, 64 experts) model, compared to the top-1 and top-2 gating counterparts in Switch Transformer, GShard, and GLaM.
Expert Choice Routing. Experts with predetermined buffer capacity are assigned top-k tokens, thus guaranteeing even load balancing. Each token can be received by a variable number of experts.
In EC routing, we set expert capacity k as the average tokens per expert in a batch of input sequences multiplied by a capacity factor, which determines the average number of experts that can be received by each token. To learn the token-to-expert affinity, our method produces a token-to-expert score matrix that is used to make routing decisions. The score matrix indicates the likelihood of a given token in a batch of input sequences being routed to a given expert.
Similar to Switch Transformer and GShard, we apply an MoE and gating function in the dense feedforward (FFN) layer, as it is the most computationally expensive part of a Transformer-based network. After producing the token-to-expert score matrix, a top-k function is applied along the token dimension for each expert to pick the most relevant tokens. A permutation function is then applied based on the generated indexes of the token, to create a hidden value with an additional expert dimension. The data is split across multiple experts such that all experts can execute the same computational kernel concurrently on a subset of tokens. Because a fixed expert capacity can be determined, we no longer overprovision expert capacity due to load imbalancing, thus significantly reducing training and inference step time by around 20% compared to GLaM.
Evaluation
To illustrate the effectiveness of Expert Choice routing, we first look at training efficiency and convergence. We use EC with a capacity factor of 2 (EC-CF2) to match the activated parameter size and computational cost on a per-token basis to GShard top-2 gating and run both for a fixed number of steps. EC-CF2 reaches the same perplexity as GShard top-2 in less than half the steps and, in addition, we find that each GShard top-2 step is 20% slower than our method.
We also scale the number of experts while fixing the expert size to 100M parameters for both EC and GShard top-2 methods. We find that both work well in terms of perplexity on the evaluation dataset during pre-training — having more experts consistently improves training perplexity.
Evaluation results on training convergence: EC routing yields 2x faster convergence at 8B/64E scale compared to top-2 gating used in GShard and GLaM (top). EC training perplexity scales better with the scaling of number of experts (bottom).
To validate whether improved perplexity directly translates to better performance in downstream tasks, we perform fine-tuning on 11 selected tasks from GLUE and SuperGLUE. We compare three MoE methods including Switch Transformer top-1 gating (ST Top-1), GShard top-2 gating (GS Top-2) and a version of our method (EC-CF2) that matches the activated parameters and computational cost of GS Top-2. The EC-CF2 method consistently outperforms the related methods and yields an average accuracy increase of more than 2% in a large 8B/64E setting. Comparing our 8B/64E model against its dense counterpart, our method achieves better fine-tuning results, increasing the average score by 3.4 points.
Our empirical results indicate that capping the number of experts for each token hurts the fine-tuning score by 1 point on average. This study confirms that allowing a variable number of experts per token is indeed helpful. On the other hand, we compute statistics on token-to-expert routing, particularly on the ratio of tokens that have been routed to a certain number of experts. We find that a majority of tokens have been routed to one or two experts while 23% have been routed to three or four experts and only about 3% tokens have been routed to more than four experts, thus verifying our hypothesis that expert choice routing learns to allocate a variable number of experts to tokens.
Final Thoughts
We propose a new routing method for sparsely activated mixture-of-experts models. This method addresses load imbalance and under-utilization of experts in conventional MoE methods, and enables the selection of different numbers of experts for each token. Our model demonstrates more than 2x training efficiency improvement when compared to the state-of-the-art GShard and Switch Transformer models, and achieves strong gains when fine-tuning on 11 datasets in the GLUE and SuperGLUE benchmark.
Our approach for expert choice routing enables heterogeneous MoE with straightforward algorithmic innovations. We hope that this may lead to more advances in this space at both the application and system levels.
Acknowledgements
Many collaborators across google research supported this work. We particularly thank Nan Du, Andrew Dai, Yanping Huang, and Zhifeng Chen for the initial ground work on MoE infrastructure and Tarzan datasets. We greatly appreciate Hanxiao Liu and Quoc Le for contributing the initial ideas and discussions. Tao Lei, Vincent Zhao, Da Huang, Chang Lan, Daiyi Peng, and Yifeng Lu contributed significantly on implementations and evaluations. Claire Cui, James Laudon, Martin Abadi, and Jeff Dean provided invaluable feedback and resource support.
NVIDIA RTX Global Illumination (RTXGI) 1.3 includes highly requested features such as dynamic library support, an increased maximum probe count per DDGI volume…
NVIDIA RTX Global Illumination (RTXGI) 1.3 includes highly requested features such as dynamic library support, an increased maximum probe count per DDGI volume by 2x, support for Shader Model 6.6 Dynamic Resources in D3D12, and more.
The NVIDIA Arm HPC Developer Kit is an integrated hardware and software platform for creating, evaluating, and benchmarking HPC, AI, and scientific computing…
The NVIDIA Arm HPC Developer Kit is an integrated hardware and software platform for creating, evaluating, and benchmarking HPC, AI, and scientific computing applications on a heterogeneous GPU- and CPU-accelerated computing system. NVIDIA announced its availability in March of 2021.
The Oak Ridge National Laboratory Leadership Computing Facility (OLCF) integrated the NVIDIA Arm HPC Developer Kit into their existing Wombat Arm cluster. Application teams worked to build, validate, and benchmark several HPC applications to evaluate application readiness for the next generation of Arm- and GPU-based HPC systems. The teams have jointly submitted for publication in the IEEE Transactions on Parallel and Distributed Systems Journal demonstrating that the suite of software and tools available for GPU-accelerated Arm systems are ready for production environments. To learn more, see Early Application Experiences on a Modern GPU-Accelerated Arm-based HPC Platform.
OLCF Wombat Cluster
Wombat is an experimental cluster equipped with Arm-based processors from various vendors. It is operational from 2018. The cluster is managed by the OLCF and is freely accessible to users and researchers.
At the time of the study, the cluster consisted of three types of compute nodes:
4 HPE Apollo 70 nodes, each equipped with dual Cavium (now Marvell) ThunderX2 CN9980 processors and two NVIDIA V100 Tensor Core GPUs
16 HPE Apollo 80 nodes, each equipped with a single Fujitsu A64FX processor
8 NVIDIA Arm HPC Developer Kit nodes, each equipped with a single Ampere Computing Altra Q80–30 CPU and 2 NVIDIA A100 GPUs
These three types of nodes share a common TX2-based login node, Arm-based, and all nodes are connected through InfiniBand EDR and HDR.
HPC application evaluation
Eleven different teams carried out the evaluation work. Teams included researchers from Oak Ridge National Laboratory, Sandia National Laboratories, University of Illinois at Urbana – Champaign, Georgia Institute of Technology, University of Basel, Swiss National Supercomputing Center (SNSC), Helmholtz-Zentrum Dresden-Rossendorf, University of Delaware, and NVIDIA.
Table 1 summarizes the final list of applications and their various characteristics. The applications cover eight different scientific domains and include codes written in Fortran, C, and C++. The parallel programming models used were MPI, OpenMP/OpenACC, Kokkos, Alpaka, and CUDA. No changes were made to the application codes during the porting activities. The evaluation process primarily focused on application porting and testing, with less emphasis on absolute performance considering the experimental nature of the testbed.
App Name
Science Domain
Language
Parallel Programming Model
ExaStar
Stellar Astrophysics
Fortran
OpenACC, OpenMP offload
GPU-I-TASSER
Bioinformatics
C
OpenACC
LAMMPS
Molecular Dynamics
C++
OpenMP, KOKKOS
MFC
Fluid Dynamics
Fortran
OpenACC
MILC
QCD
C/C++
CUDA
MiniSweep
Sn Transport
C
OpenMP, CUDA
NAMD/VMD
Molecular Dynamics
C++
CUDA
PIConGPU
Plasma Physics
C++
Alpaka, CUDA
QMCPACK
Chemistry
C++
OpenMP offload, CUDA
SPECHPC 2021
Variety of Apps
C/C++/Fortran
OpenMP offload, OpenMP
SPH-EXA2
Hydrodynamics
C++
OpenMP, CUDA
Table 1. Applications evaluated on the Wombat test bed
Bioinformatics for protein structure and function prediction
GPU-I-TASSER is a GPU-capable bioinformatics method for protein structure and function prediction. The I-TASSER suite predicts protein structures through four main steps. These include threading template identification, iterative structure assembly simulation, model selection, and refinement. The final step is structure-based function annotation. The structure folding and reassembling stage is conducted by replica exchange Monte Carlo simulations.
Figure 1. Performance of GPU-I-TASSER on Wombat and Summit
Figure 1 shows the performance of Wombat’s ThunderX2 and Ampere Altra processors and NVIDIA A100 and V100 GPUs relative to the POWER9 processor on Summit. For Ampere Ultra, NVIDIA V100, and A100, speedups of 1.8x, 6.9x, and 13.3x, respectively, were observed.
Fluid flow solver for physical problems
Multi-component Flow Code (MFC) is an open-source fluid flow solver that provides high-order accurate solutions to a wide variety of physical problems, including multi-phase compressible flows and sub-grid dispersions.
Table 2 shows average wall-clock times and relative performance metrics for the different hardware. The Time column has little absolute meaning, with the relative performance being the most meaningful (also shown in the last column). All comparisons use either the NVHPC v22.1 or GCC v11.1 compilers as indicated.The CPU wall-clock times are normalized by the number of CPU cores per chip. The results show that the A100 GPU is 1.72x faster than the V100 on Summit.
Compiler
Time (sec)
Speedup
NVIDIA A100
NVHPC
0.28
15.71
NVIDIA V100
NVHPC
0.5
8.80
2xXeon 6248
NVHPC
2.7
1.63
2xXeon 6248
GCC
2.1
2.10
Ampera Altra
NVHPC
3.9
1.13
Ampera Altra
GCC
2.7
1.63
2xPOWER9
NVHPC
4.4
1.00
2xPOWER9
GCC
3.5
1.26
2xThunderX2
NVHPC
21
0.21
2xThunderX2
GCC
5.4
0.81
A64FX
NVHPC
4.3
1.02
A64FX
GCC
13
0.34
Table 2. Comparison of wall-clock times per time step on various architectures. Bold indicates use of NVIDIA Arm HPC Development Kit hardware.
NAMD and VMD for biomolecular dynamics simulation and visualization
NAMD and VMD are biomolecular modeling applications for molecular dynamics simulation (NAMD) and for preparation, analysis, and visualization (VMD). Researchers use NAMD and VMD to study biomolecular systems ranging from individual proteins, large multiprotein complexes, photosynthetic organelles, and entire viruses.
Table 3 shows that the simulations on A100 for NAMD are as much as 50% faster than on the V100. Similar performance is demonstrated between Cavium ThunderX2 and IBM POWER9, with the latter benefiting from its low latency NVIDIA NVLink connection between CPU and GPU.
CPU
GPU
Compiler
Perf (ns/day)
2x EPYC 7742
A100-SXM4
GCC
187.5
1x Ampera Altra
A100-PCIe
GCC
182.2
2x Xeon 6134
A100-PCIe
ICC
181.4
2x POWER9
V100-NVLINK
XLC
125.7
2x ThunderX2
V100-PCIe
GCC
124.9
Table 3. NAMD single-GPU performance for 1M-atom STMV simulation, NVE ensemble with 12A cutoff, rigid bond constraints, multiple time stepping with 2fs fast time step, and 4fs for PME. Bold indicates use of NVIDIA Arm HPC Development Kit hardware.
For VMD, the GPU-accelerated results in Table 4 showcase the performance gains provided by the much higher peak arithmetic throughput and memory bandwidth provided by GPUs, relative to existing CPU platforms. The GPU molecular orbital results highlight GPU performance and host-GPU interconnect bandwidth.
CPU
Compiler
SIMD
Time (sec)
AMD TR 3975WX
ICC
AVX2
1.32
AMD TR 3975WX
ICC
SSE2
2.89
1x Ampere Alta
ArmClang
NEON
1.35
2x ThunderX2
ArmClang
NEON
3.02
A64FX
ArmClang
SVE
4.15
A64FX
ArmClang
NEON
13.89
2x POWER9
ArmClang
VSX
6.43
Table 4. Comparison of VMD molecular orbital runtime on each platform. Bold indicates use of NVIDIA Arm HPC Development Kit hardware.
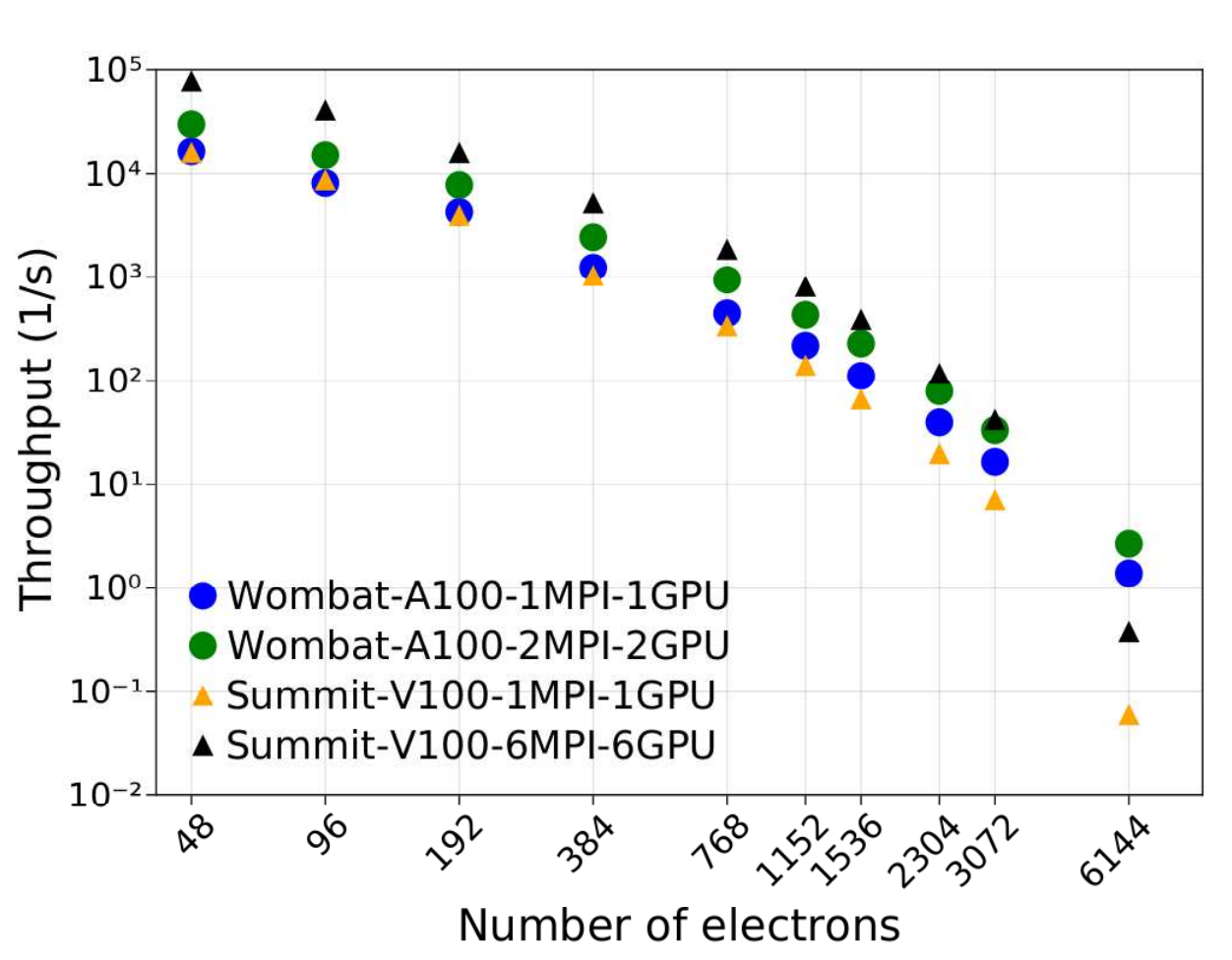
QMCPACK
QMCPACK is an open-source, high-performance Quantum Monte Carlo (QMC) package that solves the many-body Schrödinger equation using a variety of statistical approaches. The few approximations made in QMC can be systematically tested and reduced, potentially allowing the uncertainties in the predictions to be quantified at a trade-off of the significant computational expense compared to more widely used methods such as density functional theory.
Applications include weakly bound molecules, two dimensional nanomaterials, and solid-state materials such as metals, semiconductors, and insulators.
Figure 2. QMCPACK DMC throughput for Wombat and Summit nodes as a function of the number of electrons in the NiO benchmark
As shown in Figure 2, single A100 GPU runs on Wombat outperform those on V100s, with significantly larger throughput for nearly all problem sizes. Wombat’s A100 2 GPUs are significantly more performant for the largest and most computationally challenging case. For these system sizes, greater GPU memory is the most significant factor in increased performance.
NVIDIA Arm HPC Developer Kit evaluation results
The research teams working with the NVIDIA Arm HPC Developer Kit as part of the Wombat cluster said, “In our deployment of Wombat testbed nodes incorporating NVIDIA VGPUs, we found that general cluster setup was made easier by contributions across the stack from Arm Server Ready firmware OSes, software, libraries, and end-user packages.”
“Many of the GPU-accelerated applications tested in this study derived most of their performance from application kernels optimized for the GPU architecture,” they added. “This does not negate the importance of testing new Arm and GPU platforms. We noted that the biggest limitations seemed to be related to limited GPU memory sizes and the mechanisms used to migrate and keep data near the GPU accelerators.”
The path to NVIDIA Grace Hopper systems
The NVIDIA Arm HPC Developer Kit was developed to offer customers a stable hardware and software platform for development and performance analysis of accelerated HPC, AI, and scientific computing applications in the Arm Ecosystem. The NVIDIA Grace Hopper Superchip combines the very high single threaded performance of 72 Arm Neoverse V2 CPU cores with the next generation of NVIDIA Hopper H100 GPUs to offer unparalleled performance for HPC and AI applications. The NVIDIA Grace Hopper Superchip innovates by connecting the CPU to the GPU through NVLink-C2C, which is 7x faster than the PCIe Gen5 and supporting 3.5 TB/s of memory bandwidth through LPDDR5X and HBM3 memory.
The NVIDIA Grace Hopper Superchip has already been adopted by leading HPC customers, including the Swiss National Supercomputing Centre (CSCS), Los Alamos National Laboratory (LANL), and King Abdullah University of Science and Technology (KAUST).
Systems based on the NVIDIA Grace Hopper Superchip will be available from leading Original Equipment Manufacturers in the first half of 2023. Customers interested in getting a head start on moving applications to the Arm Ecosystem can still purchase an NVIDIA Arm HPC Developer Kit from Gigabyte Systems.
NVIDIA today announced a multi-year collaboration with Microsoft to build one of the most powerful AI supercomputers in the world, powered by Microsoft Azure’s advanced supercomputing infrastructure combined with NVIDIA GPUs, networking and full stack of AI software to help enterprises train, deploy and scale AI, including large, state-of-the-art models.
Content creators can now pick up the GeForce RTX 4080 GPU, available from top add-in card providers including ASUS, Colorful, Gainward, Galaxy, GIGABYTE, INNO3D, MSI, Palit, PNY and ZOTAC, as well as from system integrators and builders worldwide.
Join experts from NVIDIA and Microsoft on November 30 to discover the latest development in deep learning through hands-on demos and practical guidance for…
Join experts from NVIDIA and Microsoft on November 30 to discover the latest development in deep learning through hands-on demos and practical guidance for getting started on the cloud.

 Our trust in AI will largely depend on how well we understand it — explainable AI, or XAI, helps shine a flashlight into the “black box” of complexity in…
Our trust in AI will largely depend on how well we understand it — explainable AI, or XAI, helps shine a flashlight into the “black box” of complexity in…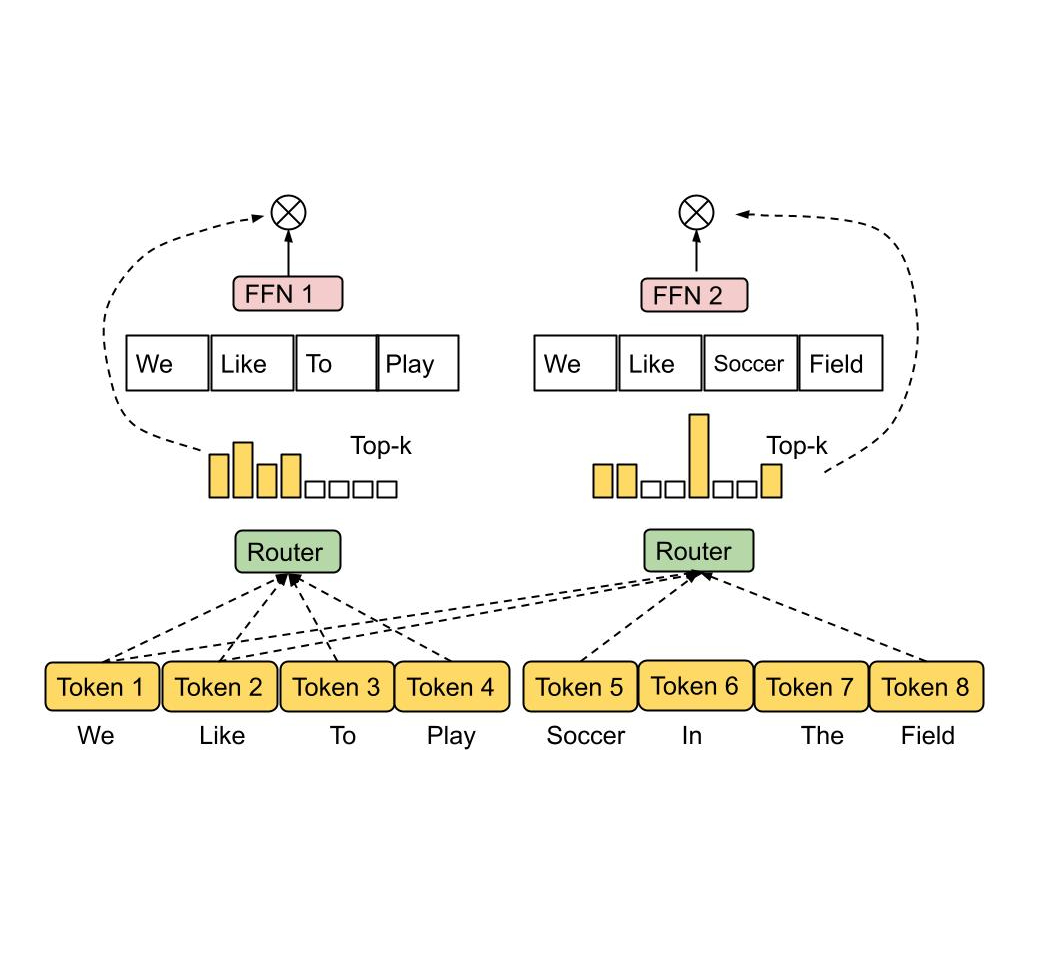



 NVIDIA RTX Global Illumination (RTXGI) 1.3 includes highly requested features such as dynamic library support, an increased maximum probe count per DDGI volume…
NVIDIA RTX Global Illumination (RTXGI) 1.3 includes highly requested features such as dynamic library support, an increased maximum probe count per DDGI volume… The NVIDIA Arm HPC Developer Kit is an integrated hardware and software platform for creating, evaluating, and benchmarking HPC, AI, and scientific computing…
The NVIDIA Arm HPC Developer Kit is an integrated hardware and software platform for creating, evaluating, and benchmarking HPC, AI, and scientific computing…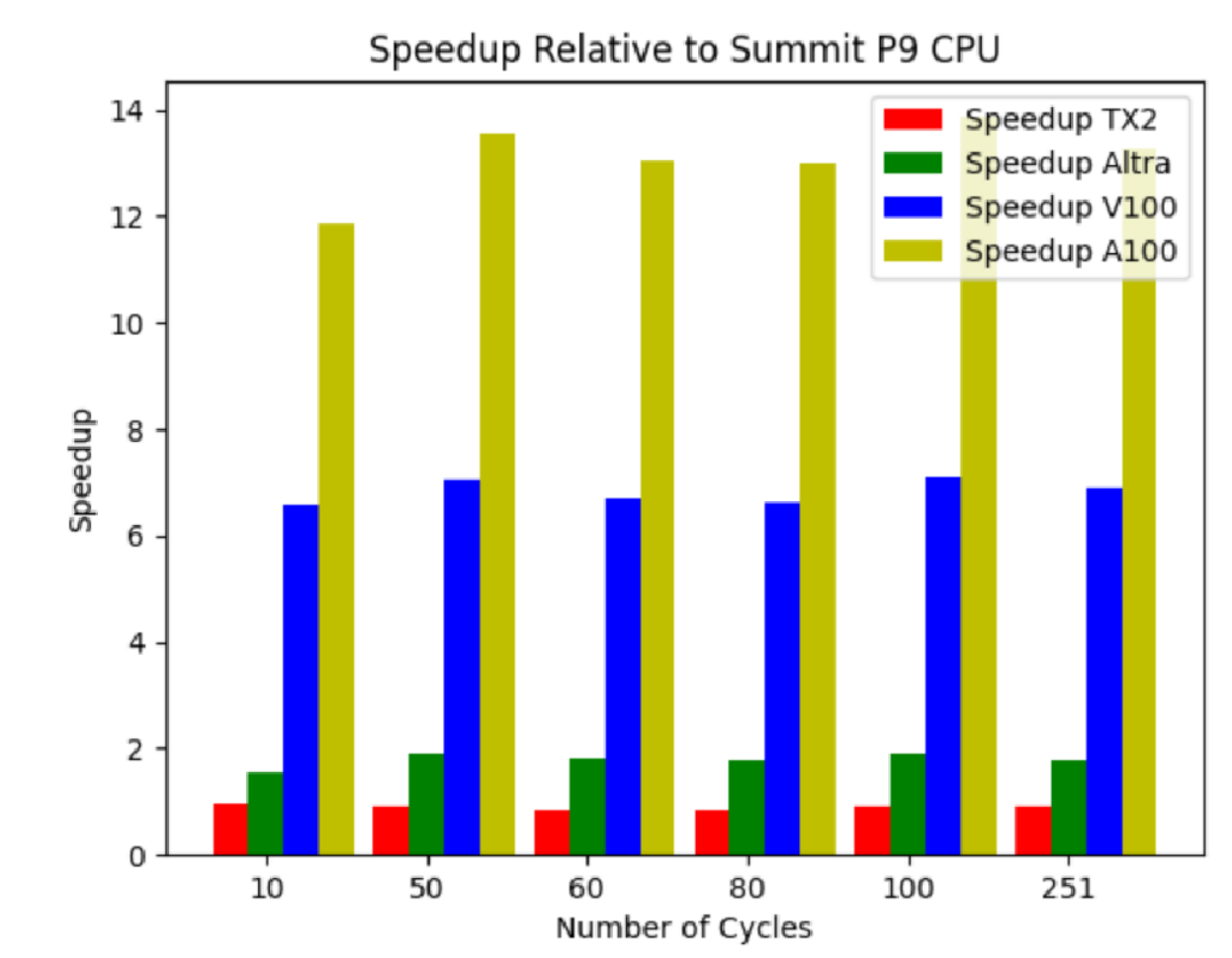
 Join experts from NVIDIA and Microsoft on November 30 to discover the latest development in deep learning through hands-on demos and practical guidance for…
Join experts from NVIDIA and Microsoft on November 30 to discover the latest development in deep learning through hands-on demos and practical guidance for…