The cellular industry spends over $50 billion on radio access networks (RAN) annually, according to a recent GSMA report on the mobile economy. Dedicated and…
The cellular industry spends over $50 billion on radio access networks (RAN) annually, according to a recent GSMA report on the mobile economy. Dedicated and…
The cellular industry spends over $50 billion on radio access networks (RAN) annually, according to a recent GSMA report on the mobile economy. Dedicated and overprovisioned hardware is primarily used to provide capacity for peak demand. As a result, most RAN sites have an average utilization below 25%.
This has been the industry reality for years as technology evolved from 2G to 4G. But it is set to become even more pronounced in 5G as the push for densification, combined with the use of mmWave, leads to a near doubling of the number of cell sites by 2027 to over 17 million. The implication is that RAN capital expenditures, as a share of overall network total cost of ownership (TCO), will grow to as much as 65% in 5G, compared to 45-50% in 4G.
A new game-changing approach turns underutilization into an opportunity: leverage the same cloud and data center infrastructure used for AI to dynamically load share with 5G virtual RAN (vRAN). This approach creates a new opportunity for cloud providers and helps reduce operational costs.
Figure 1 shows how NVIDIA is enabling the CloudRAN solution with the NVIDIA A100X converged card, Spectrum SN3750SX Switch, NVIDIA Aerial SDK, and containerized DU.
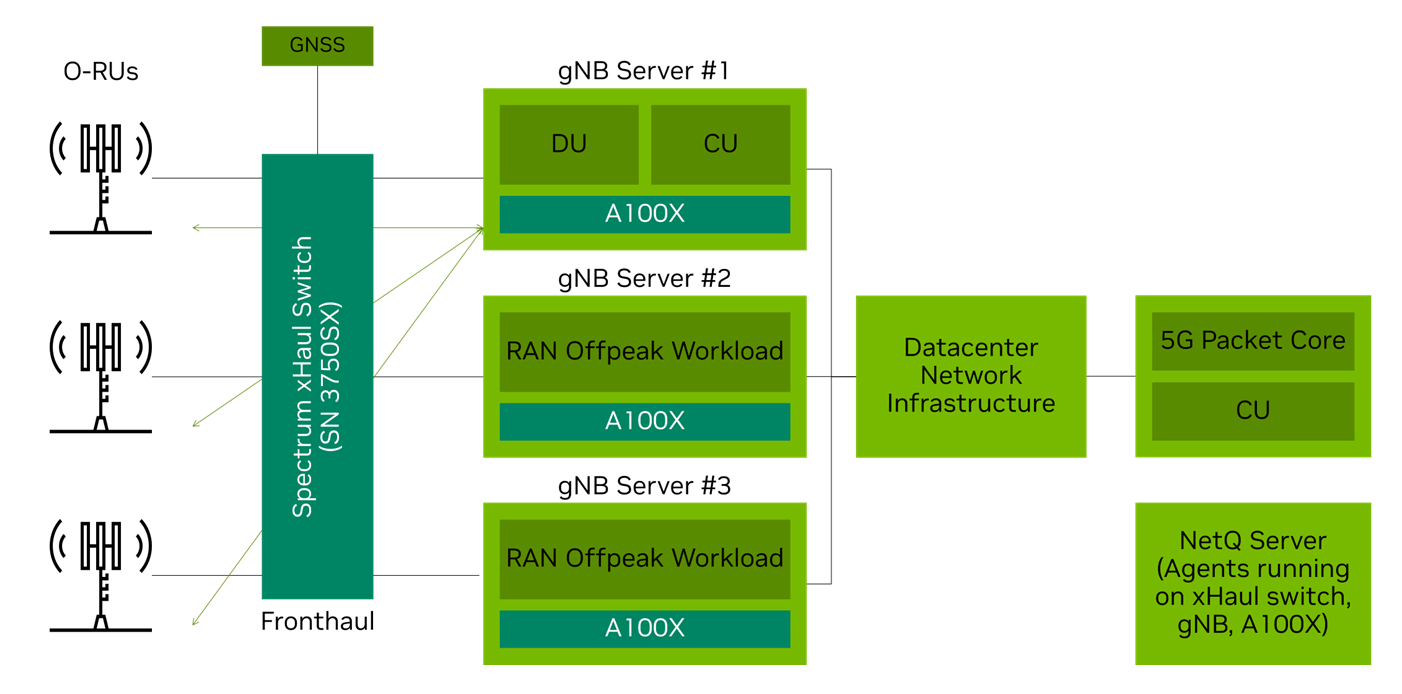
The opportunity of RAN underutilization
By pooling baseband computing resources into a cloud-native environment, the CloudRAN solution delivers significant improvements in asset utilization, creating efficiency gains for telcos and revenue opportunities for cloud service providers (CSPs). The solution achieves this by dynamically orchestrating resources between 5G and 5G RAN off-peak workloads.
Examples of 5G RAN off-peak workloads are AI workloads such as drive mapping, federated learning, offline video analytics, predictive maintenance, factory digital twins, and many more. 5G compute capacity is mapped to changes in traffic demands from 5G radios, while the remaining compute is used for AI workloads. For telcos, this can increase RAN operational efficiency by more than 2x for an estimated 25% or more impact on the operating margin.
For CSPs, running 5G vRAN as a workload alongside AI workloads within their existing data center architecture is a significant opportunity. To look at a specific example, the United States wireless market includes about 420,000 cell sites. If the telcos are using Centralized-RAN (C-RAN) for 50% of their network (mostly urban areas) and running a 4:1 configuration, then they will be using 52,000 GPUs to run their network.
In a typical data center, the hourly GPU compute rate is $2. A C-RAN configuration using dynamic orchestration to combine 5G and AI workloads and the CSP’s monetization of 52,000 GPUs will lead to a $500 million revenue opportunity. Globally, this is a multi-billion dollar opportunity.
Figure 2 shows the off-peak AI workloads that can dynamically share the C-RAN GPU with the 5G workload during off-peak periods.

To provide an example, the combination of in-vehicle AI supercomputer and GPU resources in the cloud enables offline processing for self-driving cars. The system incorporates deep learning algorithms to detect lanes, signs, and other landmarks using a combination of AI and visual simultaneous localization and mapping (VSLAM).
The industry recognizes the general trend to pull softwarized RAN resources together in a few centralized hub locations. While this improves RAN TCO by more than 30% over distributed-RAN topology, it does not solve RAN underutilization. Why? The unused RAN compute resource goes to waste during off-peak periods.
NVIDIA CloudRAN: Five building blocks
To realize the CloudRAN solution, current vRANs will need to evolve in the following five key focus areas.
First, there is a need for a software-defined fronthaul (SD-FH) with an optimal timing mechanism. Second, the RAN hardware needs to evolve from bespoke, dedicated, and (in many cases) non-cloud-native architecture, to COTS-based and cloud-native hardware. Third, the softwarized 5G RAN needs to be programmable in real time and capable of running on cloud infrastructure. Fourth, the lifecycle management (LCM) of the 5G RAN needs to be dynamic and based on open APIs.
Finally, there is a need for an end-to-end (E2E) network and service orchestrator that can dynamically manage RAN and other off-peak workloads based on network and infrastructure utilization information. E2E service orchestration executes service intent by dynamically composing the workflow based on service models, policy, and context and using closed-loop control to automate the entire service and network.
NVIDIA CloudRAN identifies and offers an enabling solution for each of the five identified evolution needs of vRAN, as shown in Figure 3.
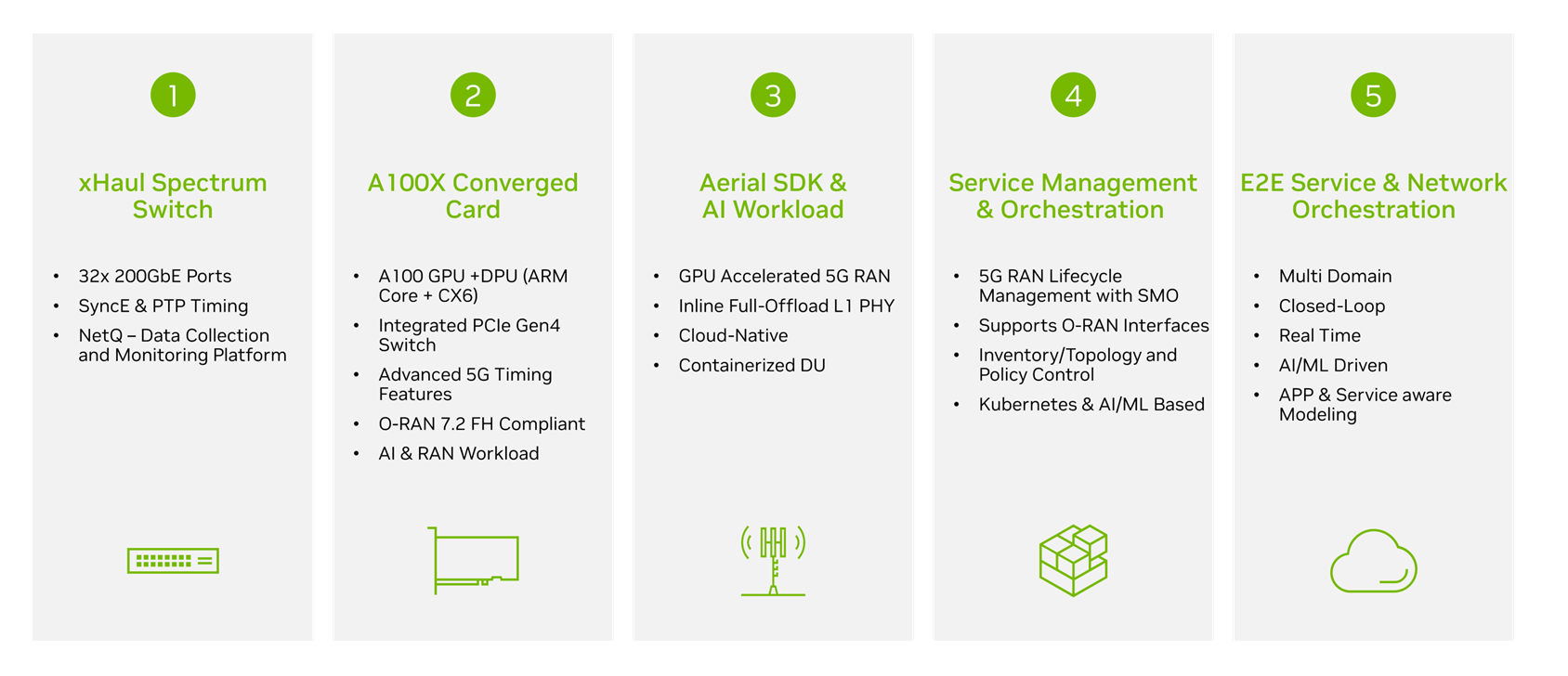
- SD-FH switch: NVIDIA SN3750-SX is a new 200G Ethernet switch based on the Spectrum-2 ASIC. It was purpose-built to provide the network fabric for CloudRAN-converged infrastructure where it runs AI training workloads alongside 5G networking. It has software-defined and hardware-accelerated 5G fronthaul capabilities to steer 5G traffic available DUs to RUs based on orchestrator mapping. It offers 5G time sync protocols with PTP telco profiles, SyncE, and PPS in/out. The switch also supports the NetQ validation toolset.
- General purpose computing hardware: The NVIDIA A100X converged card combines the power of the NVIDIA A100 Tensor Core GPU with the advanced networking capabilities of the NVIDIA BlueField-2 DPU in a single, unique platform. This convergence delivers unparalleled performance for GPU-powered, I/O-intensive workloads, such as distributed AI training in the enterprise data center and 5G vRAN processing as another workload within existing data center architecture.
- Programmable and cloud-native 5G software: The NVIDIA Aerial SDK provides the 5G workload in the CloudRAN solution. NVIDIA Aerial is a fully cloud-native virtual 5G RAN solution running on COTS servers. It realizes RAN functions as microservices in containers over bare-metal servers, using Kubernetes and applying DevOps principles. It provides a 5G RAN solution, with inline L1 GPU acceleration for 5G NR PHY processing and supports a full stack framework for a gNB integration L2/L3 (MAC, RLC, PDCP), along with manageability and orchestration.
- Open API lifecycle management: The O-RAN disaggregated, software-centric approach can help automate and orchestrate RAN complexity, irrespective of multi-vendor or multi-technology networks. Ultimately, the service management orchestration (SMO) will provide open and Kubernetes cluster APIs for RAN automation.
- E2E network and service orchestrator: E2E orchestration enables dynamic applications and services by consolidating an E2E view in real time across all technology and cloud domains. A single pane of glass enables automation of all aspects of cross-domain services and manages lifecycle management, optimization, and assurance of various workloads. The E2E orchestrator will also have an interface to interact with the cloud infrastructure manager.
Delivering the CloudRAN solution
The NVIDIA CloudRAN solution delivers a compelling value proposition with an SD-FH, general purpose data center compute, cloud-native architecture, RAN domain orchestrator, and E2E service and network orchestrator.
NVIDIA and its ecosystem partners are building a Kubernetes-based SMO and E2E service orchestrator to support dynamic workload management. With telcos, NVIDIA is working on COTS-based and cloud-native vRAN software. With CSPs, NVIDIA is working to optimize data center hardware to support 5G workloads.
Join us for the GTC 2022 session, Using AI Infrastructure in the Cloud for 5G vRAN to learn more about the CloudRAN solution.
 Developing for the medical imaging AI lifecycle is a time-consuming and resource-intensive process that typically includes data acquisition, compute, and…
Developing for the medical imaging AI lifecycle is a time-consuming and resource-intensive process that typically includes data acquisition, compute, and…
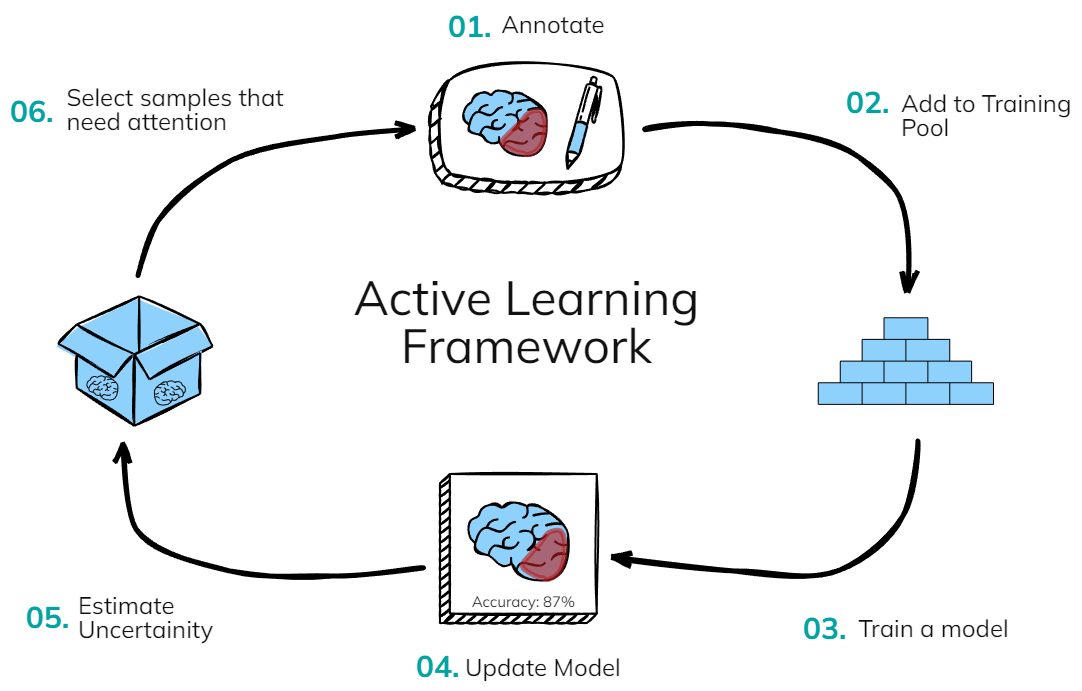
 The field of computational biology relies on bioinformatics tools that are fast, accurate, and easy to use. As next-generation sequencing (NGS) is becoming…
The field of computational biology relies on bioinformatics tools that are fast, accurate, and easy to use. As next-generation sequencing (NGS) is becoming…
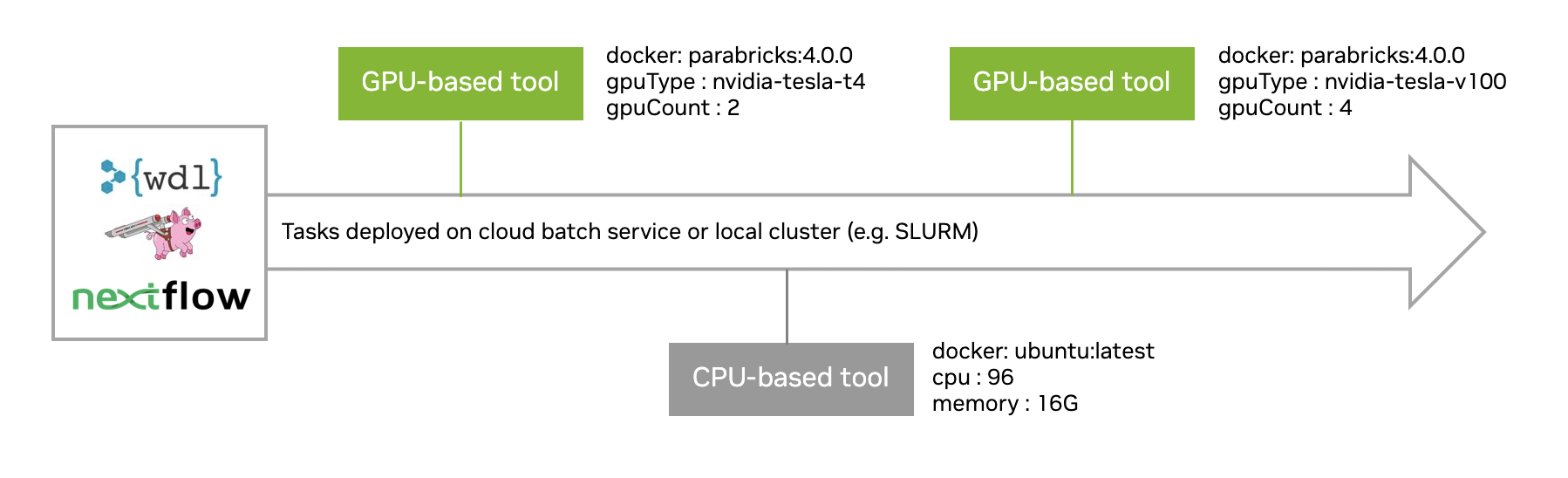
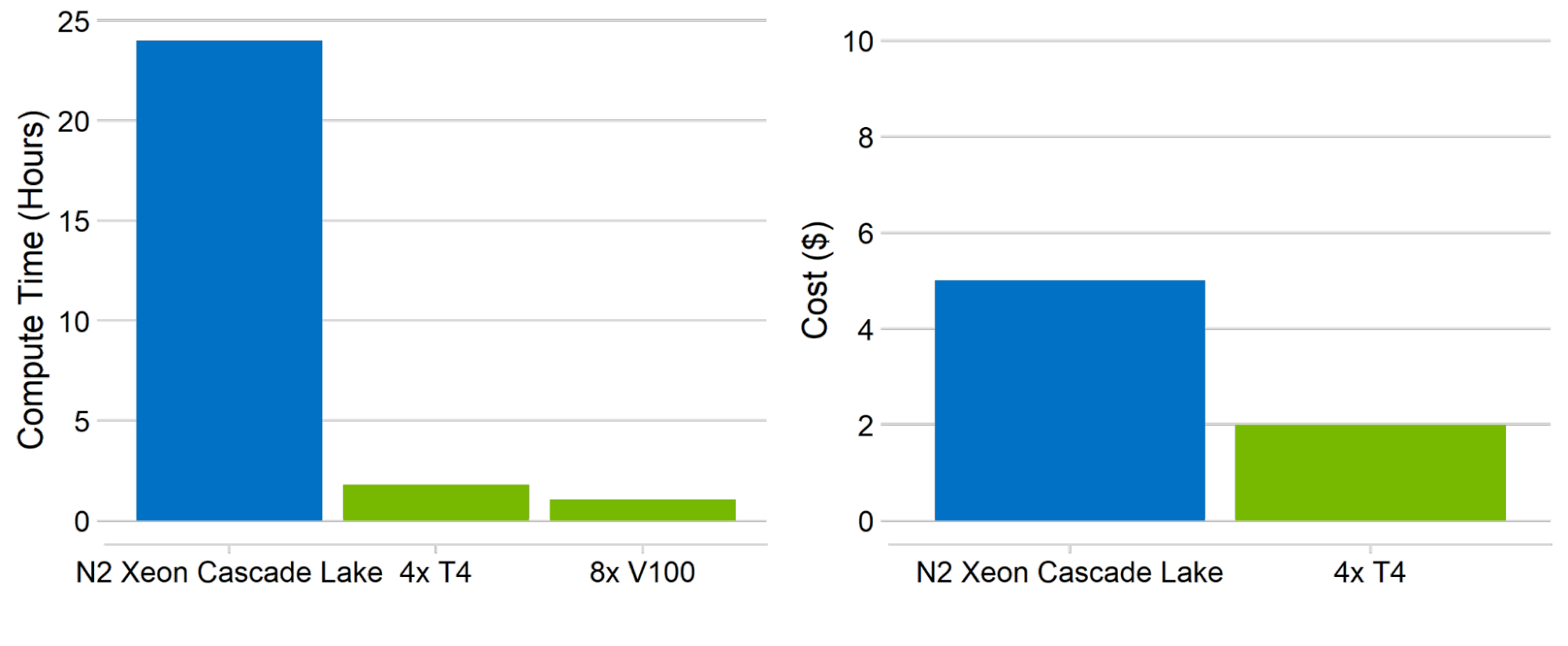

 At GTC 2022, NVIDIA revealed major updates to its suite of NVIDIA AI software for developers. The updates accelerate computing in several areas, such as machine…
At GTC 2022, NVIDIA revealed major updates to its suite of NVIDIA AI software for developers. The updates accelerate computing in several areas, such as machine… At GTC 2022, NVIDIA revealed major updates to its suite of NVIDIA AI frameworks for building real-time speech AI applications, designing high-performing…
At GTC 2022, NVIDIA revealed major updates to its suite of NVIDIA AI frameworks for building real-time speech AI applications, designing high-performing…") NVIDIA recently announced Ada Lovelace, the next generation of GPUs. Named the NVIDIA GeForce RTX 40 Series, these are the world’s most advanced graphics…
NVIDIA recently announced Ada Lovelace, the next generation of GPUs. Named the NVIDIA GeForce RTX 40 Series, these are the world’s most advanced graphics…