
 When examining an intricate speech AI robotic system, it’s easy for developers to feel intimidated by its complexity. Arthur C. Clarke claimed, “Any…
When examining an intricate speech AI robotic system, it’s easy for developers to feel intimidated by its complexity. Arthur C. Clarke claimed, “Any…
When examining an intricate speech AI robotic system, it’s easy for developers to feel intimidated by its complexity. Arthur C. Clarke claimed, “Any sufficiently advanced technology is indistinguishable from magic.”
From accepting natural-language commands to safely interacting in real-time with its environment and the humans around it, today’s speech AI robotics systems can perform tasks to a level previously unachievable by machines.
Take Spot, a speech AI-enabled robot that can fetch drinks on its own, for example. To easily add speech AI skills, such as automatic speech recognition (ASR) or text-to-speech (TTS), many developers leverage simpler low-code building blocks when building complex robot systems.

For developers creating robotic applications with speech AI skills, this post breaks down the low-code building blocks provided by the NVIDIA Riva SDK.
By following along with the provided code examples, you learn how speech AI technology makes it possible for intelligent robots to take food orders, relay those orders to a restaurant employee, and finally navigate back home when prompted.
Design an AI robotic system using building blocks
Complex systems consist of several building blocks. Each building block is much simpler to understand on its own.
When you understand the function of each component, the end product becomes less daunting. If you’re using low-code building blocks, you can now focus on domain-specific customizations requiring more effort.
Our latest project uses “Spot,” a four-legged robot, and an NVIDIA Jetson Orin, which is connected to Spot through an Ethernet cable. This project is a prime example of using AI building blocks to form a complex speech AI robot system.
Our goal was to build a robot that could fetch us snacks on its own from a local restaurant, with as little intervention from us as possible. We also set out to write as little code as possible by using what we could from open-source libraries and tools. Almost all the software used in this project was freely available.
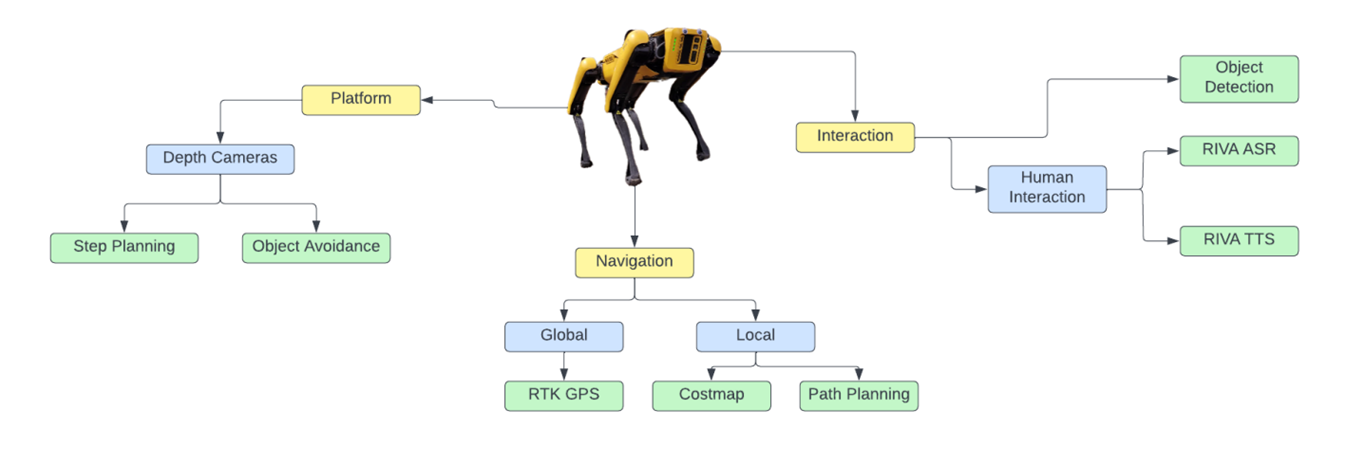
To achieve this goal, an AI system must be able to interact with humans vocally, perceive its environment (in our case, with an embedded camera), and navigate through the surroundings safely. Figure 2 shows how interaction, platform, and navigation represent our Spot robot’s three fundamental operation components, and how those components are further subdivided into low-code building blocks.
This post focuses solely on the human interaction blocks from the Riva SDK.
Add speech recognition and speech synthesis skills using Riva
We have so many interactions with people every day that it is easy to overlook how complex those interactions actually are. Speaking comes naturally to humans but is not nearly so simple for an intelligent machine to understand and talk.
Riva is a fully customizable, GPU-accelerated speech AI SDK that handles ASR and TTS skills, and is deployable on-premises, in all clouds, at the edge, and on embedded devices. It facilitates human-machine speech interactions.
Riva runs entirely locally on the Spot robot. Therefore, processing is secure and does not require internet access. It is also completely configurable with a simple parameter file, so no extra coding is needed.
Riva code examples for each speech AI task
Riva provides ready-to-use Python scripts and command-line tools for real-time transformation of audio data captured by a microphone into text (ASR, speech recognition, or speech-to-text) and for converting text into an audio output (TTS, or speech synthesis).
Adapting these scripts for compatibility with Open Robotics (ROS) requires only minor changes. This helps simplify the robotic system development process.
ASR customizations
The Riva OOTB Python client ASR script is named transcribe_mic.py. By default, it prints ASR output to the terminal. By modifying it, the ASR output is routed to a ROS topic and can be read by anything in the ROS network. The critical additions to the script’s main() function are shown in the following code example:
inter_pub = rospy.Publisher('intermediate', String, queue_size=10)
final_pub = rospy.Publisher('final', String, queue_size=10)
rospy.init_node('riva_asr', anonymous=True)
The following code example includes more critical additions to main:
for response in responses:
if not response.results:
continue
partial_transcript = ""
for result in response.results:
if not result.alternatives:
continue
transcript = result.alternatives[0].transcript
if result.is_final:
for i, alternative in enumerate(result.alternatives):
final_pub.publish(alternative.transcript)
else:
partial_transcript += transcript
if partial_transcript:
inter_pub.publish(partial_transcript)
TTS customizations
Riva also provides the talk.py script for TTS. By default, you enter text in a terminal or Python interpreter, from which Riva generates audio output. For Spot to speak, the input text talk.py script is modified so that the text comes from a ROS callback rather than a human’s keystrokes. The key changes to the OOTB script include this function for extracting the text:
def callback(msg): global TTS TTS = msg.data
They also include these additions to the main() function:
rospy.init_node('riva_tts', anonymous=True)
rospy.Subscriber("speak", String, callback)
These altered conditional statements in the main() function are also key:
while not rospy.is_shutdown():
if TTS != None:
text = TTS
Voice interaction script
Simple scripts like voice_control.py consist primarily of the callback and talker functions. They tell Spot what words to listen for and how to respond.
def callback(msg):
global pub, order
rospy.loginfo(msg.data)
if "hey spot" in msg.data.lower() and "fetch me" in msg.data.lower():
order_start = msg.data.index("fetch me")
order = msg.data[order_start + 9:]
pub.publish("Fetching " + order)
def talker():
global pub
rospy.init_node("spot_voice_control", anonymous=True)
pub = rospy.Publisher("speak", String, queue_size=10)
rospy.Subscriber("final", String, callback)
rospy.spin()
In other words, if the text contains “Hey Spot, … fetch me…” Spot saves the rest of the sentence as an order. After the ASR transcript indicates that the sentence is finished, Spot activates the TTS client and recites the word “Fetching” plus the contents of the order. Other scripts then engage a ROS action server instructing Spot to navigate to the restaurant, while taking care to avoid cars and other obstacles.
When Spot reaches the restaurant, it waits for a person to take its order by saying “Hello Spot.” If the ASR analysis script detects this sequence, Spot recites the order and ends it with “please.” The restaurant employee places the ordered food and any change in the appropriate container on Spot’s back. Spot returns home after Riva ASR recognizes that the restaurant staffer has said, “Go home, Spot.”
The technology behind a speech AI SDK like Riva for building and deploying fully customizable real-time speech AI applications deployable on-premises, in all clouds, at the edge, and embedded, brings AI robotics into the real world.
When a robot seamlessly interacts with people, it opens up a world of new areas where robots can help without needing a technical person on a computer to do the translation.
Deploy your own speech AI robot with a low-code solution
Teams such as NVIDIA, Open Robotics, and the robotics community, in general, have done a fantastic job in solving speech AI and robotics problems and making that technology available and accessible for everyday robotics users.
Anyone eager to get into the industry or to improve the technology they already have can look to these groups for inspiration and examples of cutting-edge technology. These technologies are usable through free SDKs (Riva, ROS, NVIDIA DeepStream, NVIDIA CUDA) and capable hardware (robots, NVIDIA Jetson Orin, sensors).
I am thrilled to see this level of community support from technology leaders and invite you to build your own speech AI robot. Robots are awesome!
For more information, see the following related resources:
- Explore how to get started with integrating and deploying Riva ASR and TTS models in production with high-performance inference and minimal effort with the free ebook, Building Speech AI Applications.
- Explore the NVIDIA Riva Quick Start Guide for Embedded Platforms for scripts and utilities for getting started with Riva Speech Skills on Embedded platforms.
- Get started with downloading Riva, try guided Riva labs on ready-to-run infrastructure in LaunchPad, or get support for large-scale Riva deployments with NVIDIA AI Enterprise software.
") The latest version of NVIDIA Modulus, an AI framework that enables users to create customizable training pipelines for digital twins, climate models, and…
The latest version of NVIDIA Modulus, an AI framework that enables users to create customizable training pipelines for digital twins, climate models, and… Quantum circuit simulation is critical for developing applications and algorithms for quantum computers. Because of the disruptive nature of known quantum…
Quantum circuit simulation is critical for developing applications and algorithms for quantum computers. Because of the disruptive nature of known quantum…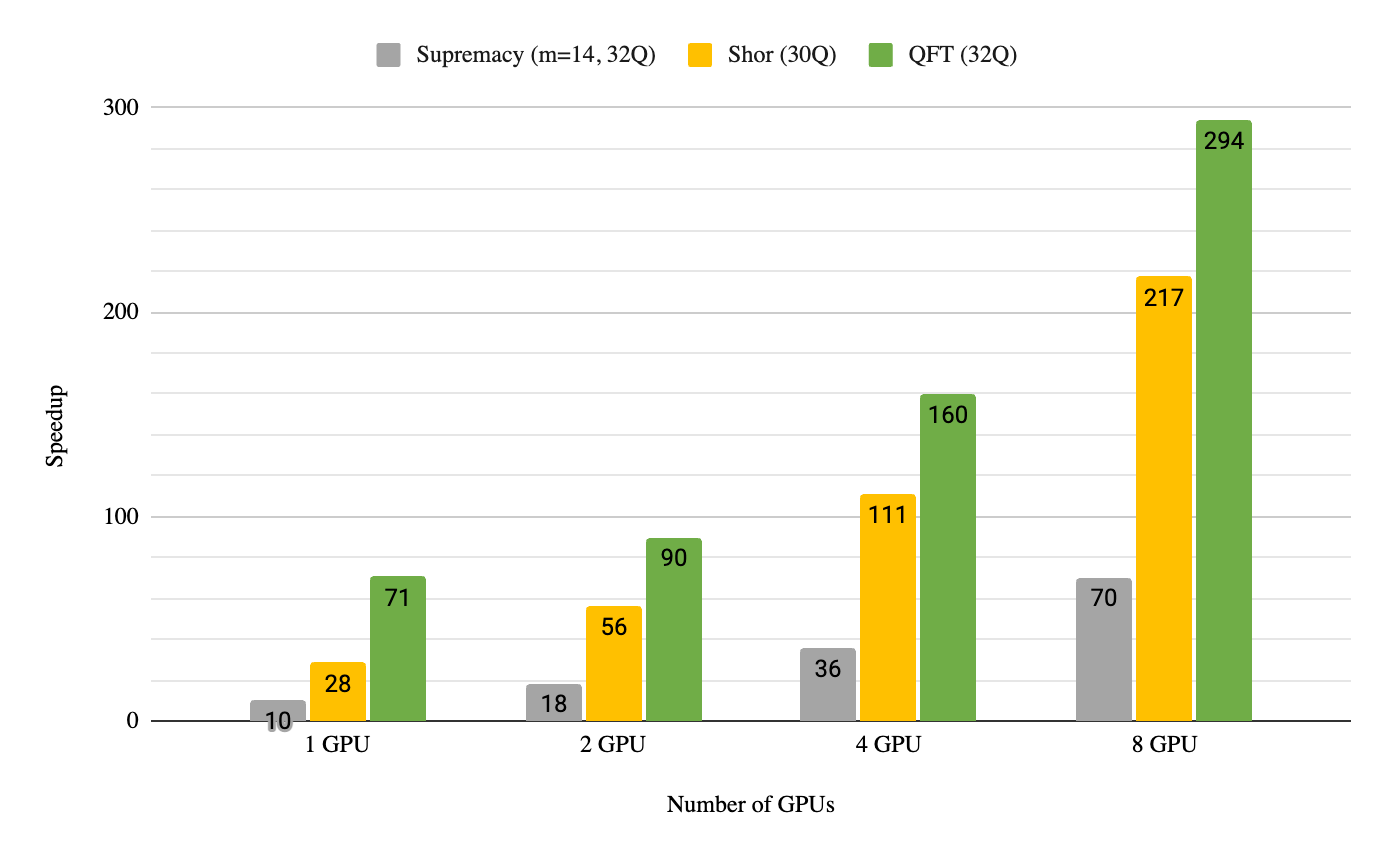
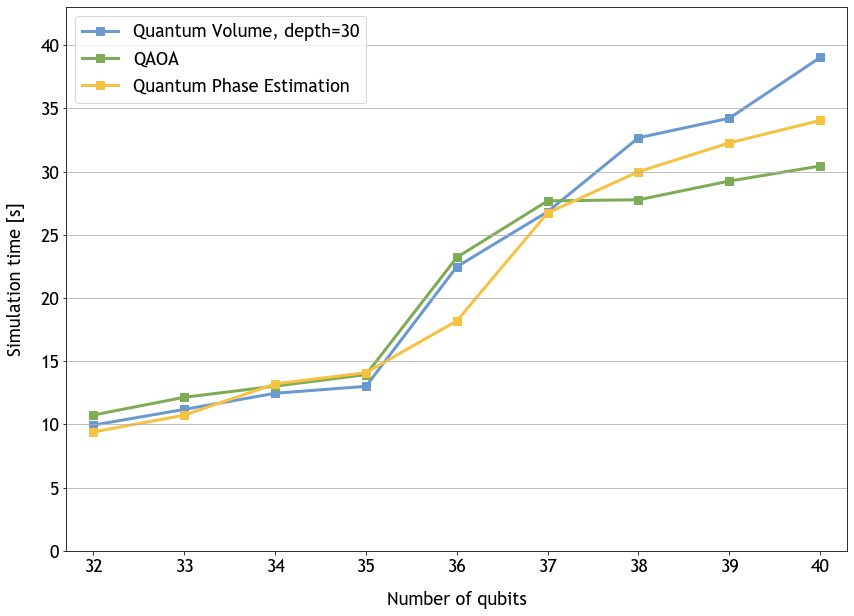
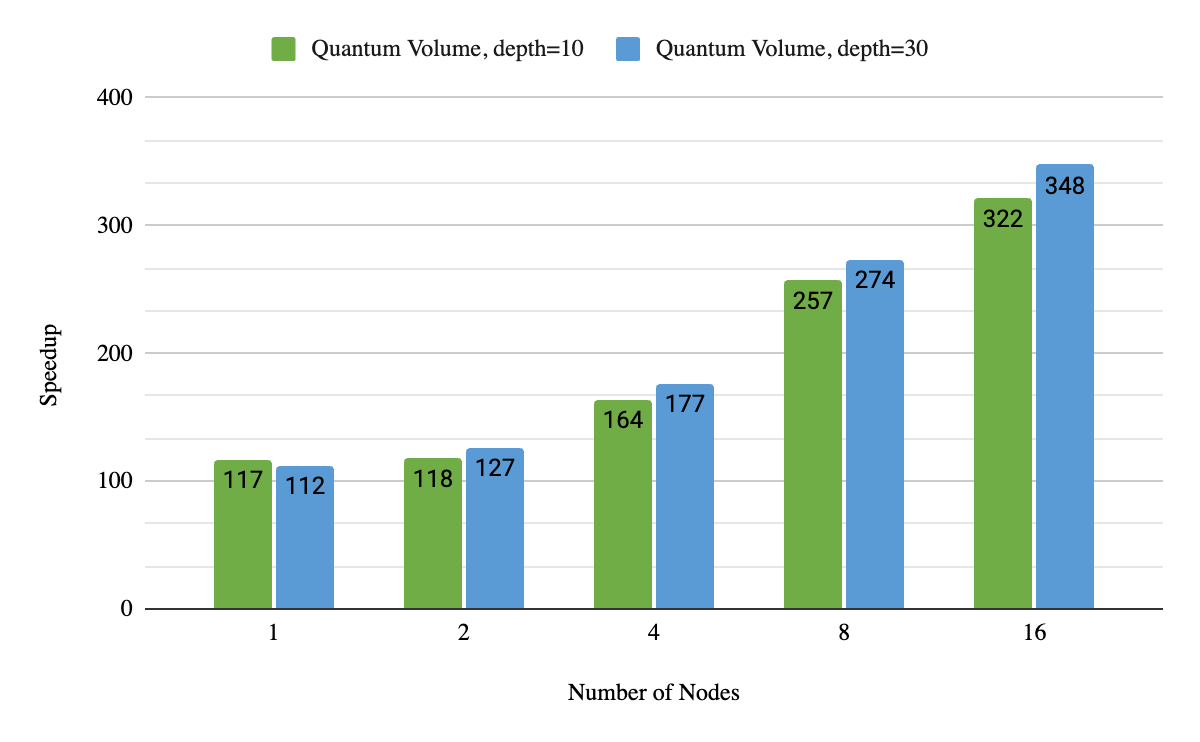








 Deploying AI models in production to meet the performance and scalability requirements of the AI-driven application while keeping the infrastructure costs low…
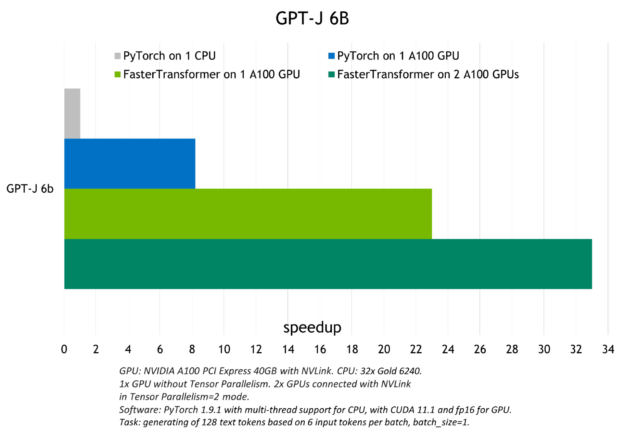
Deploying AI models in production to meet the performance and scalability requirements of the AI-driven application while keeping the infrastructure costs low…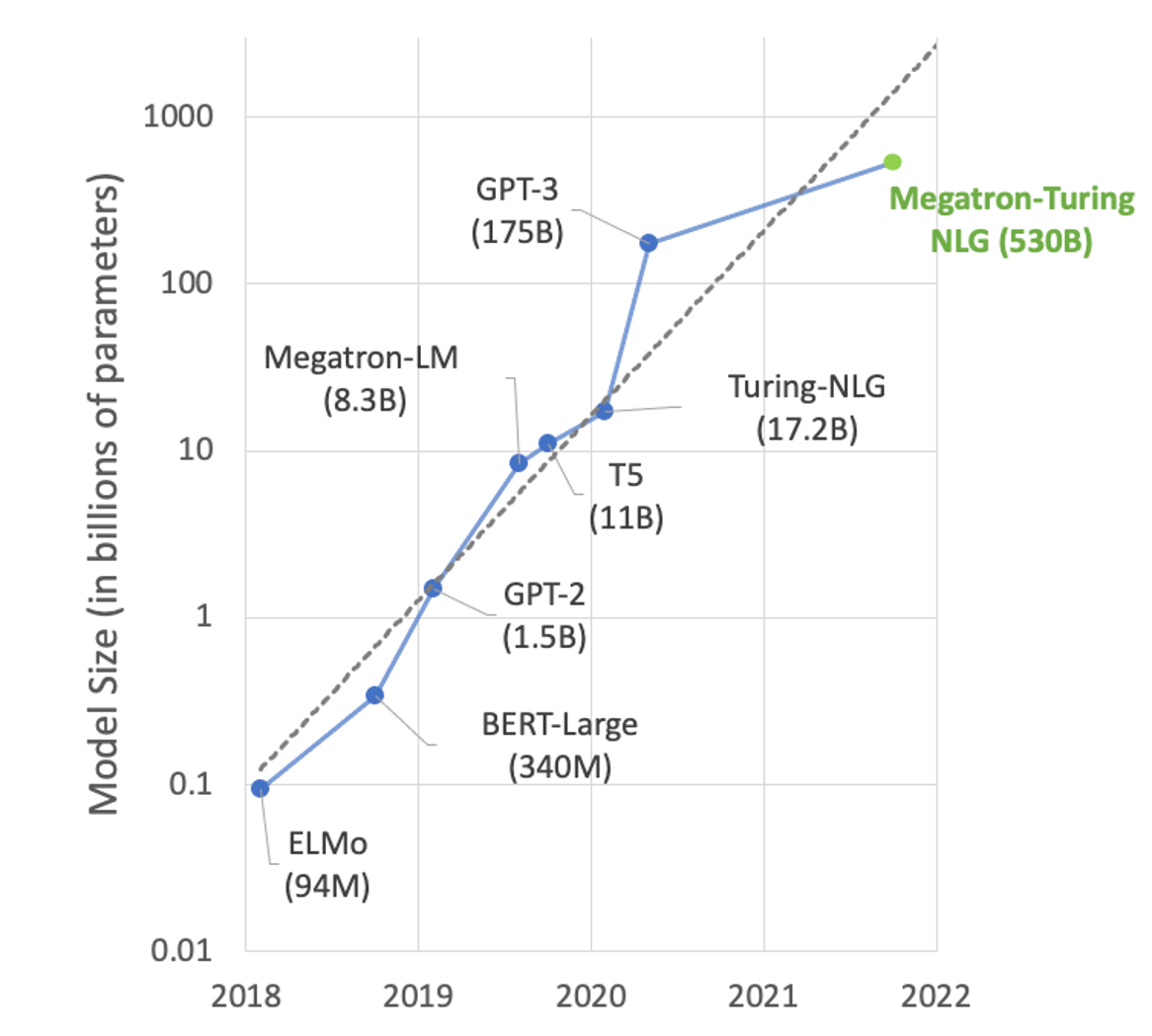
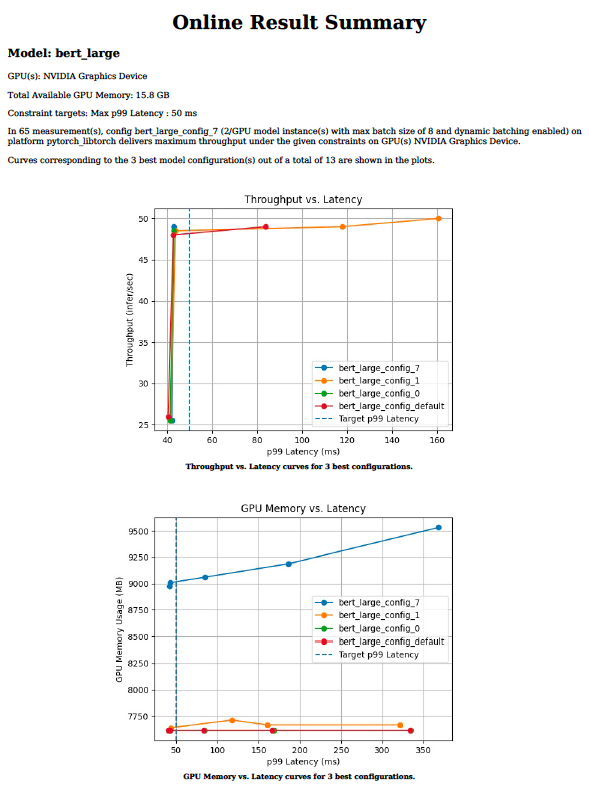
 In the operating room, the latency and reliability of surgical video streams can make all the difference for patient outcomes. Ultra-high-speed frame rates from…
In the operating room, the latency and reliability of surgical video streams can make all the difference for patient outcomes. Ultra-high-speed frame rates from…
 Explore the AI technology powering Violet, the interactive avatar showcased this week in the NVIDIA GTC 2022 keynote. Learn new details about NVIDIA Omniverse…
Explore the AI technology powering Violet, the interactive avatar showcased this week in the NVIDIA GTC 2022 keynote. Learn new details about NVIDIA Omniverse…