
 Deploying AI models in production to meet the performance and scalability requirements of the AI-driven application while keeping the infrastructure costs low…
Deploying AI models in production to meet the performance and scalability requirements of the AI-driven application while keeping the infrastructure costs low…
Deploying AI models in production to meet the performance and scalability requirements of the AI-driven application while keeping the infrastructure costs low is a daunting task.
This post provides you with a high-level overview of AI inference challenges that commonly occur when deploying models in production, along with how NVIDIA Triton Inference Server is being used today across industries to solve these cases.
We also examine some of the recently added features, tools, and services in Triton that simplify the deployment of AI models in production, with peak performance and cost efficiency.
Challenges to consider when deploying AI inference
AI inference is the production phase of running AI models to make predictions. Inference is complex but understanding the factors that affect your application’s speed and performance will help you deliver fast, scalable AI in production.
Challenges for developers and ML engineers
- Many types of models: AI, machine learning, and deep learning (neural network–based) models with different architectures and different sizes.
- Different inference query types: Real-time, offline batch, streaming video and audio, and model pipelines make meeting application service level agreements challenging.
- Constantly evolving models: Models in production must be updated continuously based on new data and algorithms, without business disruptions.
Challenges for MLOps, IT, and DevOps practitioners
- Multiple model frameworks: There are different training and inference frameworks like TensorFlow, PyTorch, XGBoost, TensorRT, ONNX, or just plain Python. Deploying and maintaining each of these frameworks in production for applications can be costly.
- Diverse processors: The models can be executed on a CPU or GPU. Having a separate software stack for each processor platform leads to unnecessary operational complexity.
- Diverse deployment platforms: Models are deployed on public clouds, on-premises data centers, at the edge, and on embedded devices on bare metal, virtualized, or a third-party ML platform. Disparate solutions or less than optimal solutions to fit the given platform leads to poor ROI. This might include slower rollouts, poor app performance, or using more resources.
A combination of these factors makes it challenging to deploy AI inference in production with the desired performance and cost efficiency.
New AI inference use cases using NVIDIA Triton
NVIDIA Triton Inference Server (Triton), is an open source inference serving software that supports all major model frameworks (TensorFlow, PyTorch, TensorRT, XGBoost, ONNX, OpenVINO, Python, and others). Triton can be used to run models on x86 and Arm CPUs, NVIDIA GPUs, and AWS Inferentia. It addresses the complexities discussed earlier through standard features.
Triton is used by thousands of organizations across industries worldwide. Here’s how Triton helps solves AI inference challenges for some customers.
NIO Autonomous Driving
NIO uses Triton to run their online services models in the cloud and data center. These models process data from autonomous driving vehicles. NIO used the Triton model ensemble feature to move their pre– and post-processing functions from client application to Triton Inference Server. The preprocessing was accelerated by 5x, increasing their overall inference throughput and enabling them to cost-efficiently process more data from the vehicles.
GE Healthcare
GE Healthcare uses Triton in their Edison platform to standardize inference serving across different frameworks (TensorFlow, PyTorch, ONNX, and TensorRT) for in-house models. The models are deployed on a variety of hardware systems from embedded (for example, an x-ray system) to on-premises servers.
Wealthsimple
The online investment management firm uses Triton on CPUs to run their fraud detection and other fintech models. Triton helped them consolidate their different serving software across applications into a single standard for multiple frameworks.
Tencent
Tencent uses Triton in their centralized ML platform for unified inference for several business applications. In aggregate, Triton helps them process 1.5M queries per day. Tencent achieved low cost of inference through Triton dynamic batching and concurrent model execution capabilities.
Alibaba Intelligent Connectivity
Alibaba Intelligent Connectivity is developing AI systems for their smart speaker applications. They use Triton in the data center to run models that generate streaming text to speech for the smart speaker. Triton delivered the lowest first packet latency needed for a good audio experience.
Yahoo Japan
Yahoo Japan uses Triton on CPUs in the data center to run models to find similar locations for the “spot search” functionality in the Yahoo Browser app. Triton is used to run the complete image search pipeline and is also integrated into their centralized ML platform to support multiple frameworks on CPUs and GPUs.
Airtel
The second largest wireless provider in India, Airtel uses Triton for automatic speech recognition (ASR) models for contact center application to improve customer experience. Triton helped them upgrade to a more accurate ASR model and still get a 2x throughput increase on GPUs compared to the previous serving solution.
How Triton Inference Server addresses AI inference challenges
From fintech to autonomous driving, all applications can benefit from out-of-box functionality to deploy models into production easily.
This section discusses a few key new features, tools, and services that Triton provides out-of-box that can be applied to deploy, run, and scale models in production.
Model orchestration with new management service
Triton brings a new model orchestration service for efficient multi-model inference. This software application, currently in early access, helps simplify the deployment of Triton instances in Kubernetes with many models in a resource-efficient way. Some of the key features of this service include the following:
- Loading models on demand and unloading models when not in use.
- Efficiently allocating GPU resources by placing multiple models on a single GPU server wherever possible
- Managing custom resource requirements for individual models and model groups
For a short demo of this service, see Take Your AI Inference to the Next Level. The model orchestration feature is in private early access (EA). If you are interested in trying it out, sign up now.
Large language model inference
In the area of natural language processing (NLP), the size of models is growing exponentially (Figure 1). Large transformer-based models with hundreds of billions of parameters can solve many NLP tasks such as text summarization, code generation, translation, or PR headline and ad generation.
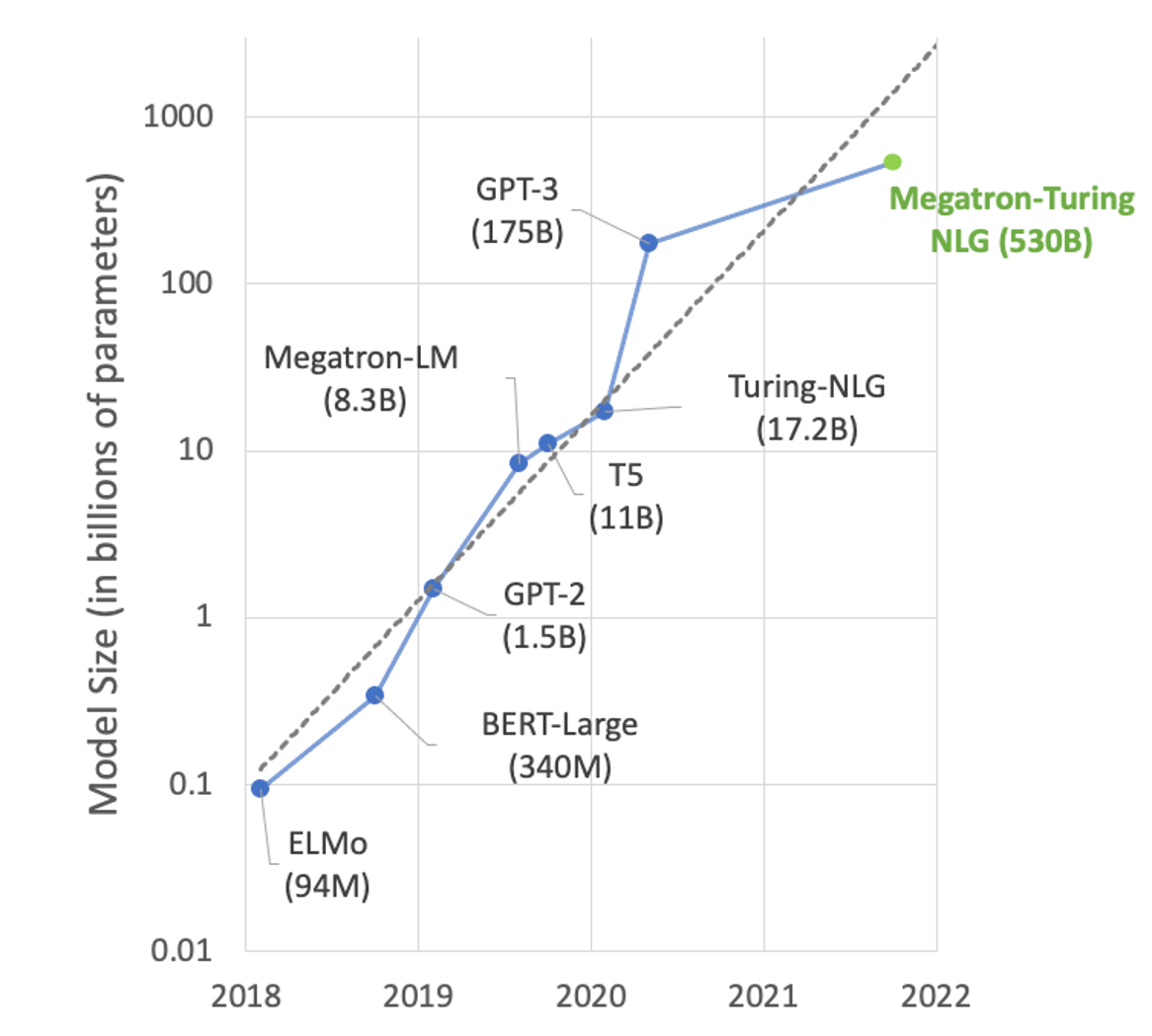
But these models are so large that they cannot fit in a single GPU. For example, Turing-NLG with 17.2B parameters needs at least 34 GB of memory to store weights and biases in FP16 and GPT-3 with 175B parameters needs at least 350 GB. To use them for inference, you need multi-GPU and increasingly multi-node execution for serving the model.
Triton Inference Server has a backend called FasterTransformer that brings multi-GPU multi-node inference for large transformer models like GPT, T5, and others. The large language model is converted to FasterTransformer format with optimizations and distributed inference capabilities and is then run using Triton Inference Server across GPUs and nodes.
Figure 2 shows the speedup observed with Triton to run the GPT-J (6B) model on a CPU or one and two A100 GPUs.
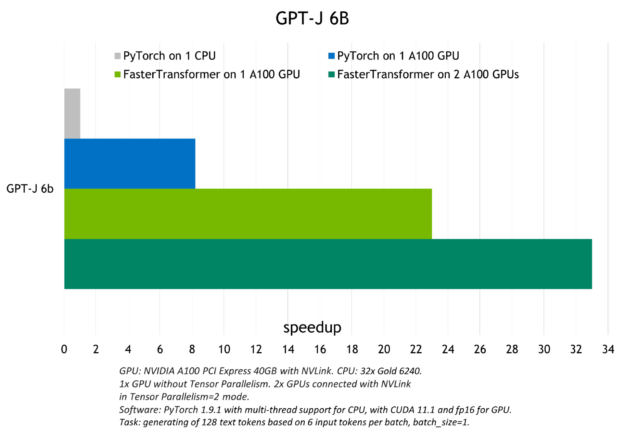
For more information about large language model inference with the Triton FasterTransformer backend, see Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server and Deploying GPT-J and T5 with NVIDIA Triton Inference Server.
Inference of tree-based models
Triton can be used to deploy and run tree-based models from frameworks such as XGBoost, LightGBM, and scikit-learn RandomForest on both CPUs and GPUs with explainability using SHAP values. It accomplishes that using the Forest Inference Library (FIL) backend that was introduced last year.
The advantage of using Triton for tree-based model inference is better performance and standardization of inference across machine learning and deep learning models. It is especially useful for real-time applications such as fraud detection, where bigger models can be used easily for better accuracy.
For more information about deploying a tree-based model with Triton, see Real-time Serving for XGBoost, Scikit-Learn RandomForest, LightGBM, and More. The post includes a fraud detection notebook.
Try this NVIDIA Launchpad lab to deploy an XGBoost fraud detection model with Triton.
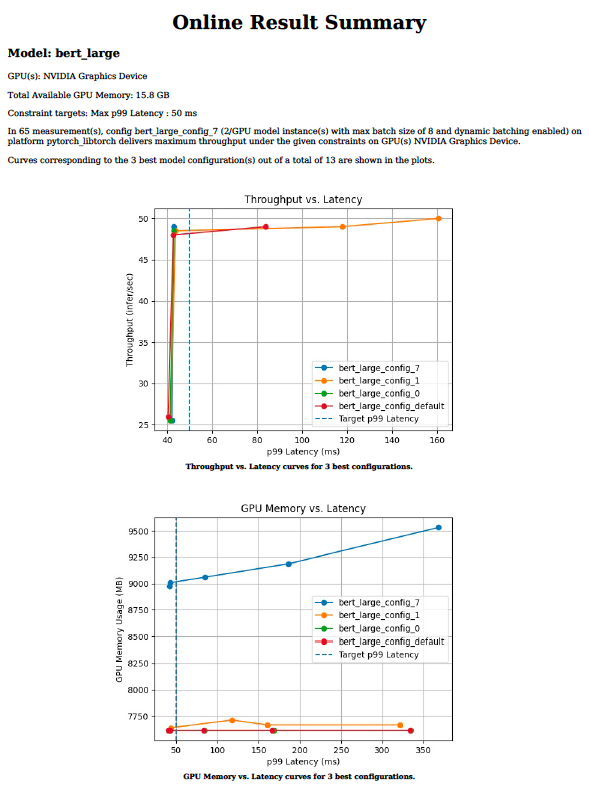
Optimal model configuration with Model analyzer
Efficient inference serving requires choosing optimal values for parameters such as batch size, model concurrency, or precision for a given target processor. These values dictate throughput, latency, and memory requirements. It can take weeks to try hundreds of combinations manually across a range of values for each parameter.
The Triton model analyzer tool reduces the time that it takes to find the optimal configuration parameters, from weeks to days or even hours. It does this by running hundreds of simulations of inference with different values of batch size and model concurrency for a given target processor offline. At the end, it provides charts like Figure 3 that make it easy to choose the optimal deployment configuration. For more information about the model analyzer tool and how to use it for your inference deployment, see Identifying the Best AI Model Serving Configurations at Scale with NVIDIA Triton Model Analyzer.
Model pipelines with business logic scripting
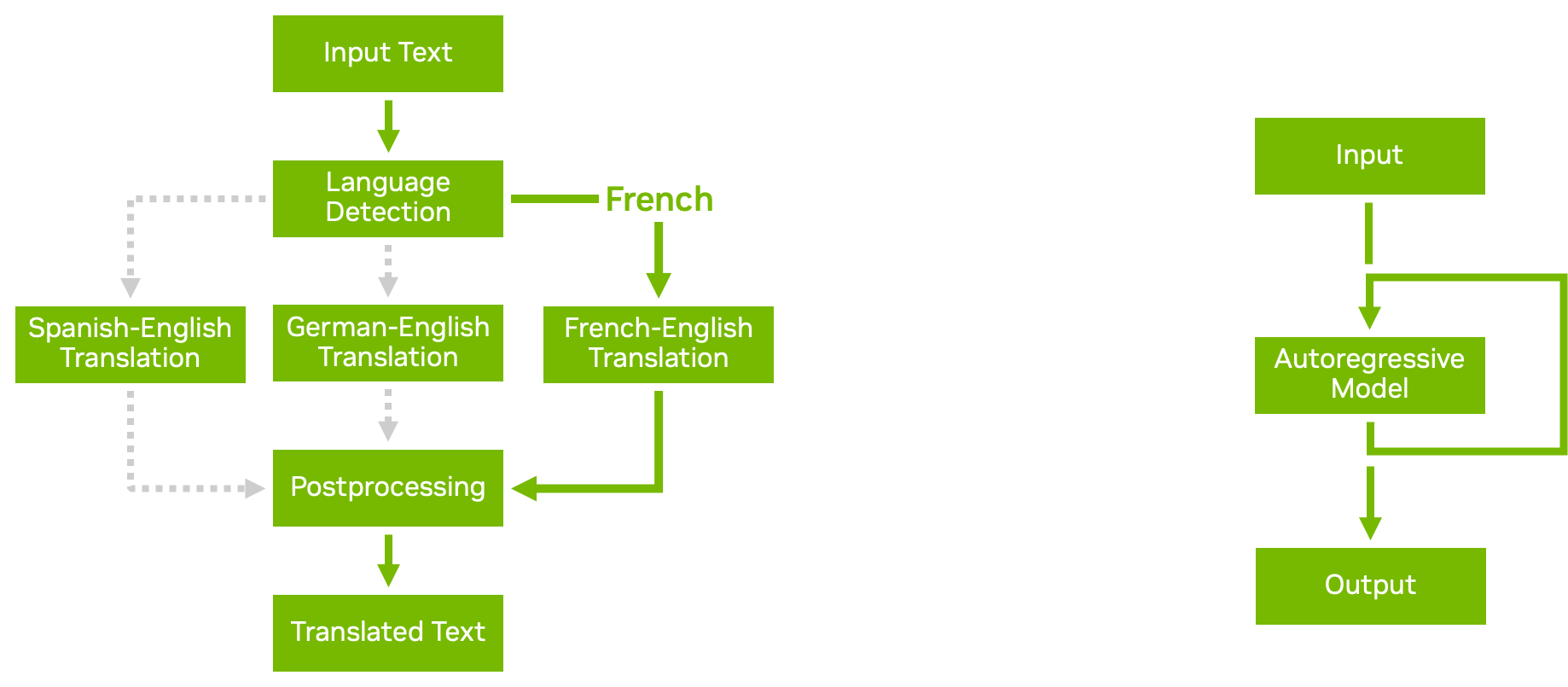
With the model ensemble feature in Triton, you can build out complex model pipelines and ensembles with multiple models and pre– and post-processing steps. Business logic scripting enables you to add conditionals, loops, and reordering of steps in the pipeline.
Using the Python or C++ backends, you can define a custom script that can call any other model being served by Triton based on conditions that you choose. Triton efficiently passes data to the newly called model, avoiding unnecessary memory copying whenever possible. Then the result is passed back to your custom script, from which you can continue further processing or return the result.
Figure 4 shows two examples of business logic scripting:
- Conditional execution helps you use resources more efficiently by avoiding the execution of unnecessary models.
- Autoregressive models, like transformer decoding, require the output of a model to be repeatedly fed back into itself until a certain condition is reached. Loops in business logic scripting enable you to accomplish that.
For more information, see Business Logic Scripting.
Auto-generation of model configuration
Triton can automatically generate config files for your models for faster deployment. For TensorRT, TensorFlow, and ONNX models, Triton generates the minimum required config settings to run your model by default when it does not detect a config file in the repository.
Triton can also detect if your model supports batched inference. It sets max_batch_size to a configurable default value.
You can also include commands in your own custom Python and C++ backends to generate model config files automatically based on the script contents. These features are especially useful when you have many models to serve, as it avoids the step of manually creating the config files. For more information, see Auto-generated Model Configuration.
Decoupled input processing
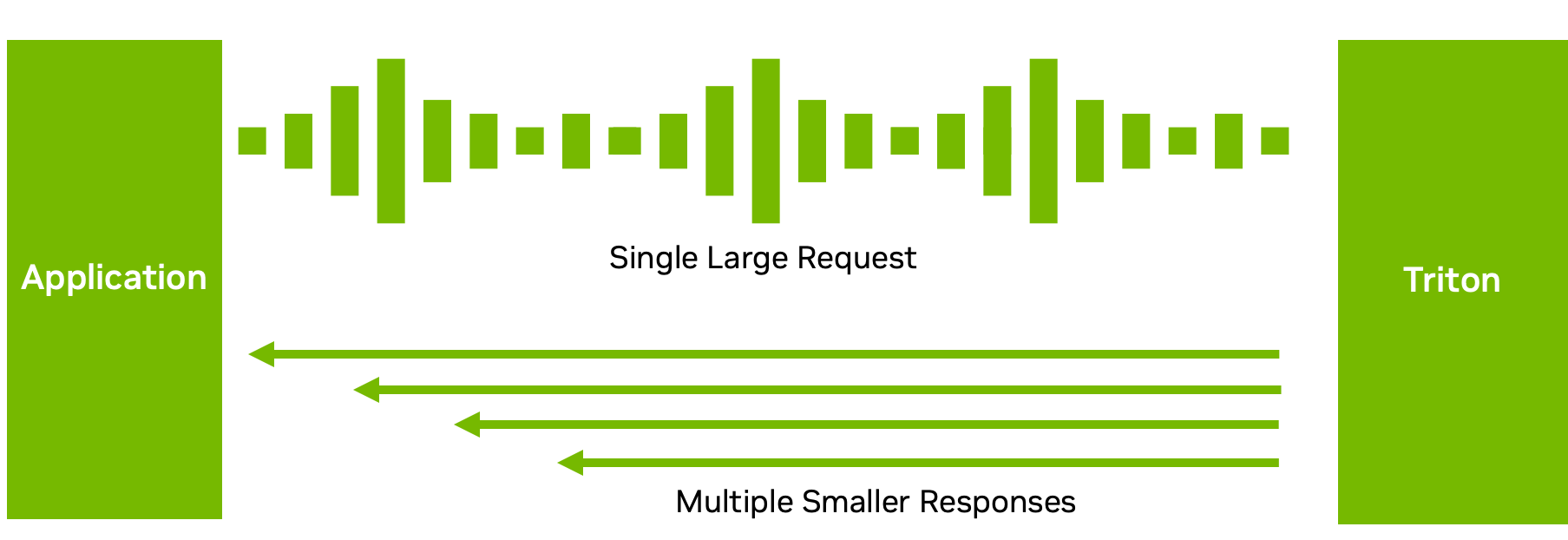
While many inference settings require a one-to-one correspondence between inference requests and responses, this isn’t always the optimal data flow.
For instance, with ASR models, sending the full audio and waiting for the model to finish execution may not result in a good user experience. The wait can be long. Instead, Triton can send back the transcribed text in multiple short chunks (Figure 5), reducing the latency and time to the first response.
With decoupled model processing in the C++ or Python backend, you can send back multiple responses for a single request. Of course, you could also do the opposite: send multiple small requests in chunks and get back one big response. This feature provides flexibility in how you process and send your inference responses. For more information, see Decoupled Models.
For more information about recently added features, see the NVIDIA Triton release notes.
Get started with scalable AI model deployment
You can deploy, run, and scale AI models with Triton to effectively mitigate AI inference challenges that you may have with multiple frameworks, a diverse infrastructure, large language models, optimal model configurations, and more.
Triton Inference Server is open-source and supports all major model frameworks such as TensorFlow, PyTorch, TensorRT, XGBoost, ONNX, OpenVINO, Python, and even custom frameworks on GPU and CPU systems. Explore more ways to integrate Triton with any application, deployment tool, and platform, on the cloud, on-premises, and at the edge.
For more information, see the following resources:
- Get started with NVIDIA Triton and access a variety of beginner to advanced resources.
- Uncover the features that you need in an inference platform when building a real-time or continuous data streaming application, Fast and Scalable AI Model Deployment with NVIDIA Triton Inference Server.
- Find out why traditional computing infrastructure is no longer enough to support large-scale AI, The secret to rapid and insightful AI–GPU-accelerated computing.
- Looking for a hands-on skills lab? Deploy an AI support chatbot or train your own AI model for image classification of online products on NVIDIA LaunchPad.