
 This is the second part of a two-part series about NVIDIA tools that allow you to run large transformer models for accelerated inference. For an introduction to…
This is the second part of a two-part series about NVIDIA tools that allow you to run large transformer models for accelerated inference. For an introduction to…
This is the second part of a two-part series about NVIDIA tools that allow you to run large transformer models for accelerated inference. For an introduction to the NVIDIA FasterTransformer library (Part 1), see Accelerated Inference for Large Transformer Models Using FasterTransformer and Triton Inference Server.
Introduction
This post is a guide to optimized inference of large transformer models such as EleutherAI’s GPT-J 6B and Google’s T5-3B. Both of these models demonstrate good results in many downstream tasks and are among the most available to researchers and data scientists.
NVIDIA FasterTransformer (FT) in NVIDIA Triton allows you to run both of these models in a similar and simple manner while providing enough flexibility to integrate/combine with other inference or training pipelines. The same NVIDIA software stack can be used for inference of the trillion-parameters models combining tensor parallelism (TP) and pipeline parallelism (PP) techniques on multiple nodes.
Transformer models are increasingly used in numerous domains and demonstrate outstanding accuracy. More importantly, the size of the model directly affects its quality. Apart from the NLP, this is applicable to other domains as well.
Researchers from Google demonstrated that the scaling of the transformer-based text encoder was crucial for the whole image generation pipeline in their Imagen model, the latest and one of the most promising generative text-to-image models. Scaling the transformers leads to outstanding results in both single and multi-domain pipelines. This guide uses transformer-based models of the same structure and a similar size.
Overview and walkthrough of main steps
This section presents the main steps for running T5 and GPT-J in optimized inference using FasterTransformer and Triton Inference Server. Figure 1 demonstrates the overall process for one neural network.
You can reproduce all steps using the step-by-step fastertransformer_backend notebook on GitHub.
It is highly recommended to do all the steps in a Docker container to reproduce the results. Instructions about preparing a FasterTransformer Docker container are available at the beginning of the same notebook.
If you have pretrained one of these models, you will have to convert the weights from your framework saved-model files into the binary format recognizable by the FT. Scripts for conversion are provided in the FasterTransformer repository.
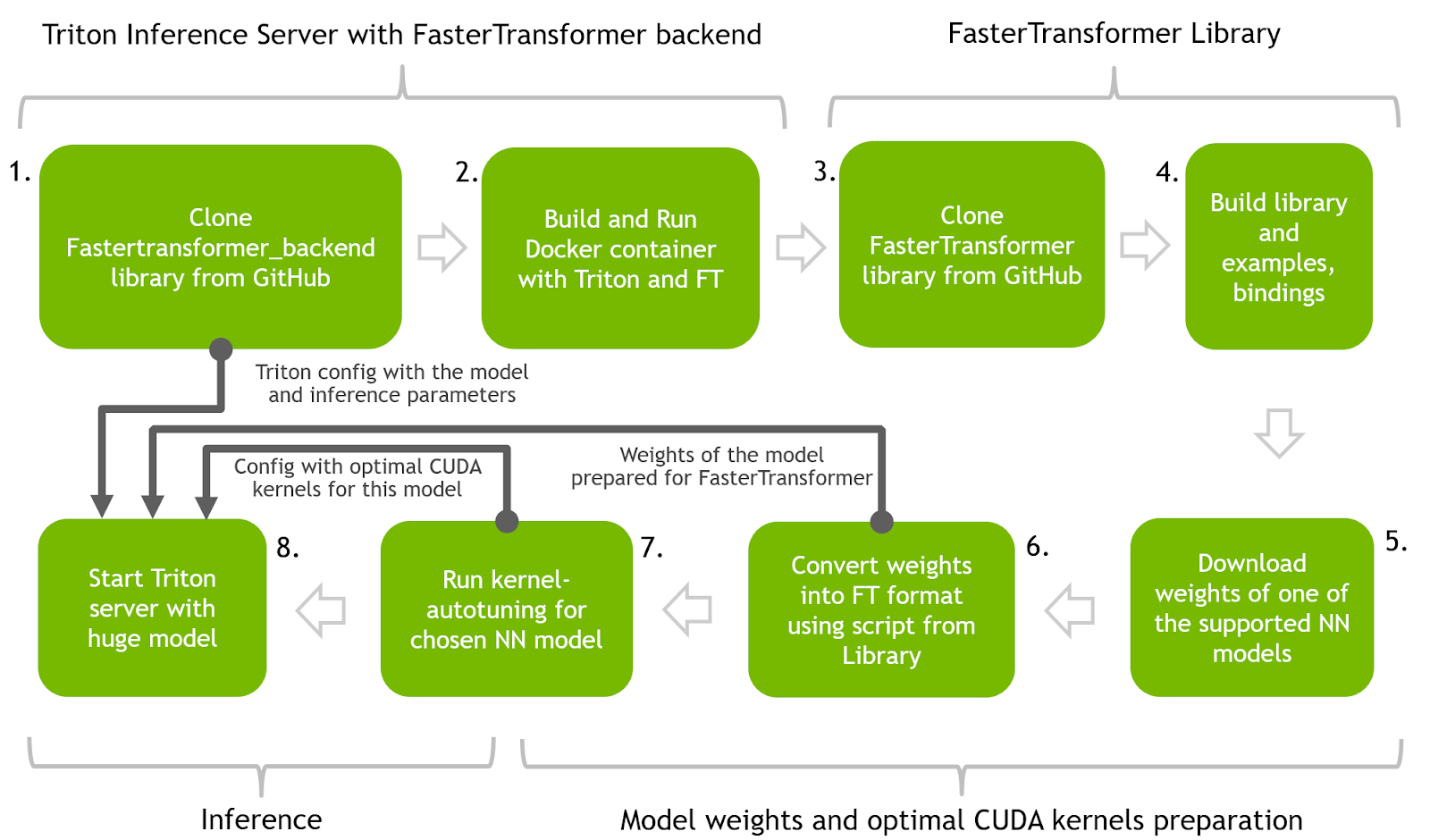
Steps 1 and 2: Build Docker container with Triton inference server and FasterTransformer backend. Use the Triton inference server as the main serving tool proxying requests to the FasterTransformer backend.
Steps 3 and 4: Build the FasterTransformer library. This library contains many useful tools for inference preparation as well as bindings for multiple languages and examples of how to do inference in C++ and Python.
Steps 5 and 6: Download weights of the pretrained models (T5-3B and GPT-J) and prepare them for the inference with FT by converting into binary format and splitting them into multiple partitions for parallelism and accelerated inference. Code from the FasterTransformer library will be used in this step.
Step 7: Use code from the FasterTransformer library to find optimal low-level kernels for the NN.
Step 8: Start the Triton server that uses all artifacts from previous steps and run the Python client code to send requests to the server with accelerated models.
Step 1: Clone fastertransformer_backend from the Triton GitHub repository
Clone the fastertransformer_backend repo from GitHub:
git clone https://github.com/triton-inference-server/fastertransformer_backend.git
cd fastertransformer_backend && git checkout -b t5_gptj_blog remotes/origin/dev/t5_gptj_blogStep 2: Build Docker container with Triton and FasterTransformer libraries
Build the Docker image using this file:
docker build --rm --build-arg TRITON_VERSION=22.03 -t triton_with_ft:22.03
-f docker/Dockerfile .
cd ../
Run the Docker container and start an interactive bash session with this code:
docker run -it --rm --gpus=all --shm-size=4G -v $(pwd):/ft_workspace
-p 8888:8888 triton_with_ft:22.03 bashAll further steps need to be run inside the Docker container interactive session. Jupyter Lab is also needed in this container to work with the notebook provided.
apt install jupyter-lab && jupyter lab -ip 0.0.0.0The Docker container was built with Triton and FasterTransformer and started with the fastertransformer_backend source codes inside.
Steps 3 and 4: Clone FasterTransformer source codes and build the library
The FasterTransformer library is pre-built and placed into our container during the Docker build process.
Download the FasterTransformer source code from GitHub to use the additional scripts that allow converting the pre-trained model files of the GPT-J or T5 into FT binary format that will be used at the time of inference.
git clone https://github.com/NVIDIA/FasterTransformer.gitThe library has the ability to run code for kernel autotuning later:
mkdir -p FasterTransformer/build && cd FasterTransformer/build
git submodule init && git submodule update
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON ..
make -j32GPT-J inference
GPT-J is a decoder model that was developed by EleutherAI and trained on The Pile, an 825GB dataset curated from multiple sources. With 6 billion parameters, GPT-J is one of the largest GPT-like publicly-released models.
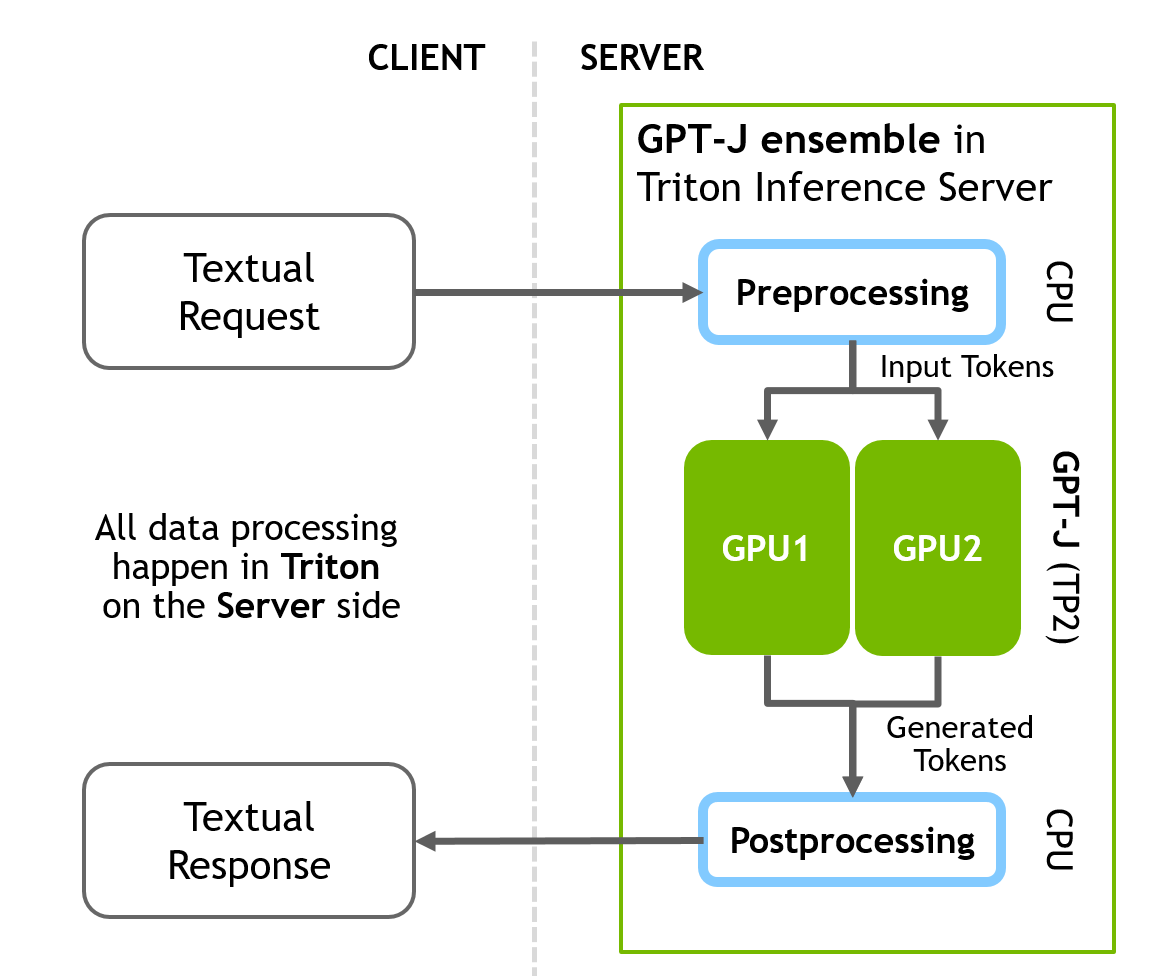
FasterTransformer backend has a config for the GPT-J model under fastertransformer_backend/all_models/gptj. This config is a perfect demonstration of a Triton ensemble. Triton allows you to run a single model inference, as well as construct complex pipes/pipelines comprising many models required for an inference task.
You can also add additional Python/C++ scripts before and/or after any neural network for pre/post processing steps that could transform your data/results into the final form.
The GPT-J inference pipeline includes three different sequential steps at the server side:
pre-processing -> FasterTransformer -> post-processing
The config file combines all three stages into a single pipeline. Figure 2 illustrates the client-server inference scheme.
Steps 5-8 are the same for both GPT-J and T5 and are provided below (GPT first, followed by T5).
Step 5 (GPT-J): Download and prepare weights of the GPT-J model
wget https://mystic.the-eye.eu/public/AI/GPT-J-6B/step_383500_slim.tar.zstd
tar -axf step_383500_slim.tar.zstd -C ./models/ These weights need to be converted into the binary format recognized by the C++ FasterTransformer backend. FasterTransformer provides the tools/scripts for different pretrained neural networks.
For the GPT-J weights you can use the script:
FasterTransformer/examples/pytorch/gptj/utils/gptj_ckpt_convert.py to convert the checkpoint as follows:
Step 6 (GPT-J): Convert weights into FT format
python3 ./FasterTransformer/examples/pytorch/gptj/utils/gptj_ckpt_convert.py
--output-dir ./models/j6b_ckpt
--ckpt-dir ./step_383500/
--n-inference-gpus 2The n-inference-gpus specifies the number of GPUs for tensor parallelism. This script will create ./models/j6b_ckpt/2-gpu directory and automatically write prepared weights there. These weights will be ready for TensorParallel 2 inference. Using this parameter, you can split your weights onto a larger number of GPUs to achieve even higher speed using the TP technique.
Step 7 (GPT-J): Kernel-autotuning for the GPT-J inference
The next step is kernel-autotuning. Matrix multiplication is the main and the heaviest operation in transformer-based neural networks. FT uses functionalities from CuBLAS and CuTLASS libraries to execute this type of operation. It is important to note that MatMul operation can be executed in tens of different ways using different low-level algorithms at the “hardware” level.
The FasterTransformer library has a script that allows real-time benchmarking of all low-level algorithms and selection of the best one for the parameters of the model (size of the attention layers, number of attention heads, size of the hidden layer) and for your input data. This step is optional but achieves a higher inference speed.
Run the ./FasterTransformer/build/bin/gpt_gemm binary file that was built at the stage of building FasterTransformer library. Arguments for the script may be found in the GitHub’s documentation or by using --help argument.
./FasterTransformer/build/bin/gpt_gemm 8 1 32 12 128 6144 51200 1 2Step 8 (GPT-J): Prepare the Triton config and serve the model
With the weights ready, the next step is to prepare a Triton config file for the GPT-J model. Open the main Triton config for the GPT-J model at fastertransformer_backend/all_models/gptj/fastertransformer/config.pbtxt for editing. Only two mandatory parameters need to be changed there to start inference.
Update tensor_para_size. Weights were prepared for two GPUs, so set it equal to 2.
parameters {
key: "tensor_para_size"
value: {
string_value: "2"
}
}Update the path to the checkpoint folder from the previous step:
parameters {
key: "model_checkpoint_path"
value: {
string_value: "./models/j6b_ckpt/2-gpu/"
}
}Now start the Triton inference server with Triton backend and GPT-J:
CUDA_VISIBLE_DEVICES=0,1 /opt/tritonserver/bin/tritonserver --model-repository=./triton-model-store/gptj/ &If Triton starts successfully, you will see output lines informing that the models are loaded by Triton and the server is listening the designated ports for incoming requests:
# Info about T5 model that was found by the Triton in our directory:
+-------------------+---------+--------+
| Model | Version | Status |
+-------------------+---------+--------+
| fastertransformer | 1 | READY |
+-------------------+---------+--------+
# Info about that Triton successfully started and waiting for HTTP/GRPC requests:
I0503 17:26:25.226719 1668 grpc_server.cc:4421] Started GRPCInferenceService at 0.0.0.0:8001
I0503 17:26:25.227017 1668 http_server.cc:3113] Started HTTPService at 0.0.0.0:8000
I0503 17:26:25.283046 1668 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002Next, send the inference requests to the server. On the client side, the tritonclient Python library allows communicating with our server from any of the Python apps.
This example with GPT-J sends textual data straight to the Triton server and all preprocessing and postprocessing will happen on the server side. The full client script can be found at fastertransformer_backend/tools/end_to_end_test.py or in the Jupyter notebook provided.
The main parts include:
# Import libraries
import tritonclient.http as httpclient
# Initizlize client
client = httpclient.InferenceServerClient("localhost:8000",
concurrency=1,
verbose=False)
# ...
# Request text promp from user
print("Write any input prompt for the model and press ENTER:")
# Prepare tokens for sending to the server
inputs = prepare_inputs( [[input()]])
# Sending request
result = client.infer(MODEl_GPTJ_FASTERTRANSFORMER, inputs)
print(result.as_numpy("OUTPUT_0"))T5 inference
T5 (Text-to-Text Transfer Transformer) is a recent architecture created by Google. It consists of encoder and decoder parts and is an instance of a full transformer architecture. It reframes all the natural language processing (NLP) tasks into a unified text-to-text format where the input and output are always text strings.
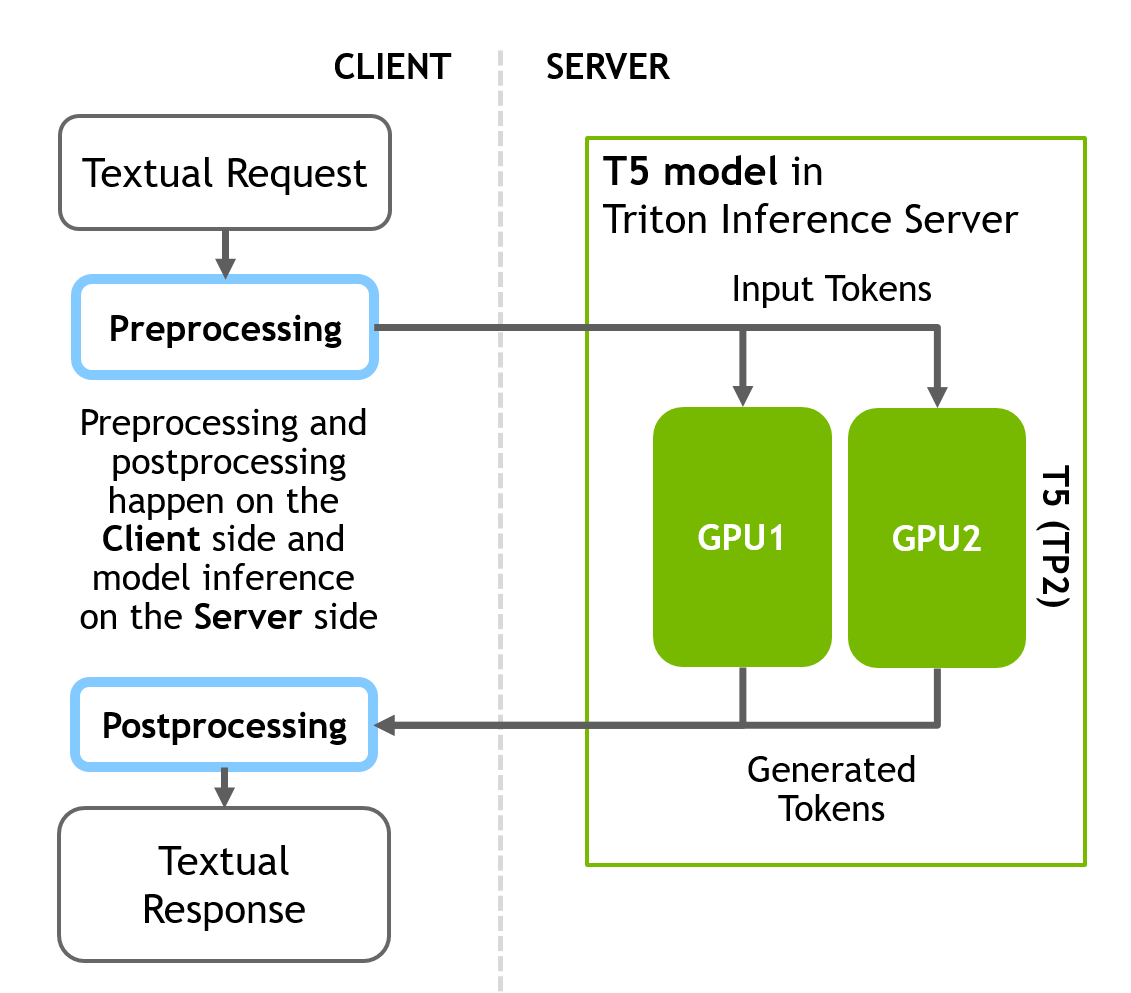
The T5 inference pipeline prepared in this section differs from the GPT-J model, in that only the NN inference stage is on the server side, not a full pipeline with data preprocessing and results in postprocessing. All computations for the pre- and post-processing stages are happening on the client side.
Triton allows you to configure your inference flexibly so it is possible to build a full pipeline on the server side too, but other configurations are also possible.
First, do a conversion from text into tokens in Python using the Huggingface library on the client side. Next, send an inference request to the server. Finally, after getting a response from the server, convert the generated tokens into text on the client side.
Figure 3 illustrates the client-server inference scheme.
Preparation steps for T5 are the same as for GPT-J. Details for steps 5-8 are provided below for T5:
Step 5 (T5): Download weights of the T5-3B
First download weights of the T5 3b size. You will have to install git-lfs to successfully download the weights.
git clone https://huggingface.co/t5-3bStep 6 (T5): Convert weights into FT format
Again, the weights need to be converted into the binary format recognized by the C++ FasterTransformer backend. For T5 weights you can use the script at FasterTransformer/blob/main/examples/pytorch/t5/utils/huggingface_t5_ckpt_convert.py to convert the checkpoint.
The converter requires the following arguments. Quite similar to GPT-J but parameter i_g means the number of GPUs will be used for the inference in TP regime, so set it to 2:
python3 FasterTransformer/examples/pytorch/t5/utils/huggingface_t5_ckpt_convert.py
-i t5-3b/
-o ./models/t5-3b/
-i_g 2Step 7 (T5): Kernel-autotuning for the T5-3B inference
The next step is kernel-autotuning for T5 using the t5_gemm binary file that will run experiments to benchmark the heaviest parts of the T5 model and find the best low-level kernels. Run ./FasterTransformer/build/bin/t5_gemm binary file that was built at the stage of building the FasterTransformer library (Step 2). This step is optional but including it achieves a higher inference speed. Again, the arguments for the script may be found in the GitHub’s documentation or by using --help argument.
./FasterTransformer/build/bin/t5_gemm 1 1 32 1024 32 128 16384 1024 32 128 16384 32128 1 2 1 1Step 8 (T5): Prepare the Triton config of the T5 model
You will have to open the copied Triton config for the T5 model triton-model-store/t5/fastertransformer/config.pbtxt for editing. Only two mandatory parameters need to be changed there to start the inference.
Then update tensor_para_size. Weights were prepared for two GPUs, so set it to 2.
parameters {
key: "tensor_para_size"
value: {
string_value: "2"
}
}Next, update the path to the folder with weights:
parameters {
key: "model_checkpoint_path"
value: {
string_value: "./models/t5-3b/2-gpu/"
}
}Start the Triton inference server. Update the path to the converted model prepared in the previous step:
CUDA_VISIBLE_DEVICES=0,1 /opt/tritonserver/bin/tritonserver --model-repository=./triton-model-store/t5/ If Triton starts successfully, you will see these lines in the output:
# Info about T5 model that was found by the Triton in our directory:
+-------------------+---------+--------+
| Model | Version | Status |
+-------------------+---------+--------+
| fastertransformer | 1 | READY |
+-------------------+---------+--------+
# Info about that Triton successfully started and waiting for HTTP/GRPC requests:
I0503 17:26:25.226719 1668 grpc_server.cc:4421] Started GRPCInferenceService at 0.0.0.0:8001
I0503 17:26:25.227017 1668 http_server.cc:3113] Started HTTPService at 0.0.0.0:8000
I0503 17:26:25.283046 1668 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002Now run the client script. On the client side, transform the textual input to tokens using the Huggingface library and only then send a request to the server using the Python’s tritonclient library. Implement function preprocessing for this purpose.
Then use an instance of the tritonclient http class that will request the 8000 port on the server (“localhost” if deployed locally) to send tokens to the model through HTTP.
After receiving the response containing the tokens, again transform the tokens into text form using a postprocessing helper function.
# Import libraries
from transformers import (
T5Tokenizer,
T5TokenizerFast
)
import tritonclient.http as httpclient
# Initialize client
client = httpclient.InferenceServerClient(
URL, concurrency=request_parallelism, verbose=verbose
)
# Initialize tokenizers from HuggingFace to do pre and post processings
# (convert text into tokens and backward) at the client side
tokenizer = T5Tokenizer.from_pretrained(MODEL_T5_HUGGINGFACE, model_max_length=1024)
fast_tokenizer = T5TokenizerFast.from_pretrained(MODEL_T5_HUGGINGFACE, model_max_length=1024)
# Implement the function that takes text converts it into the tokens using
# HFtokenizer and prepares tensorts for sending to Triton
def preprocess(t5_task_input):
...
# Implement function that takes tokens from Triton's response and converts
# them into text
def postprocess(result):
...
# Run translation task with T5
text = "Translate English to German: He swung back the fishing pole and cast the line."
inputs = preprocess(text)
result = client.infer(MODEl_T5_FASTERTRANSFORMER, inputs)
postprocess(result)Adding custom layers and new NN architectures
If you have some custom neural network with the transformer blocks inside, or you have added some custom layers into default NNs supported by FT (T5, GPT), this NN won’t be supported by FT out-of-the-box. You can either change the source code of FT to add support for this NN by adding support for new layers, or you can use FT blocks and C++, PyTorch, and TensorFlow API to integrate fast transformer blocks from FT into your custom inference script/pipeline.
Results
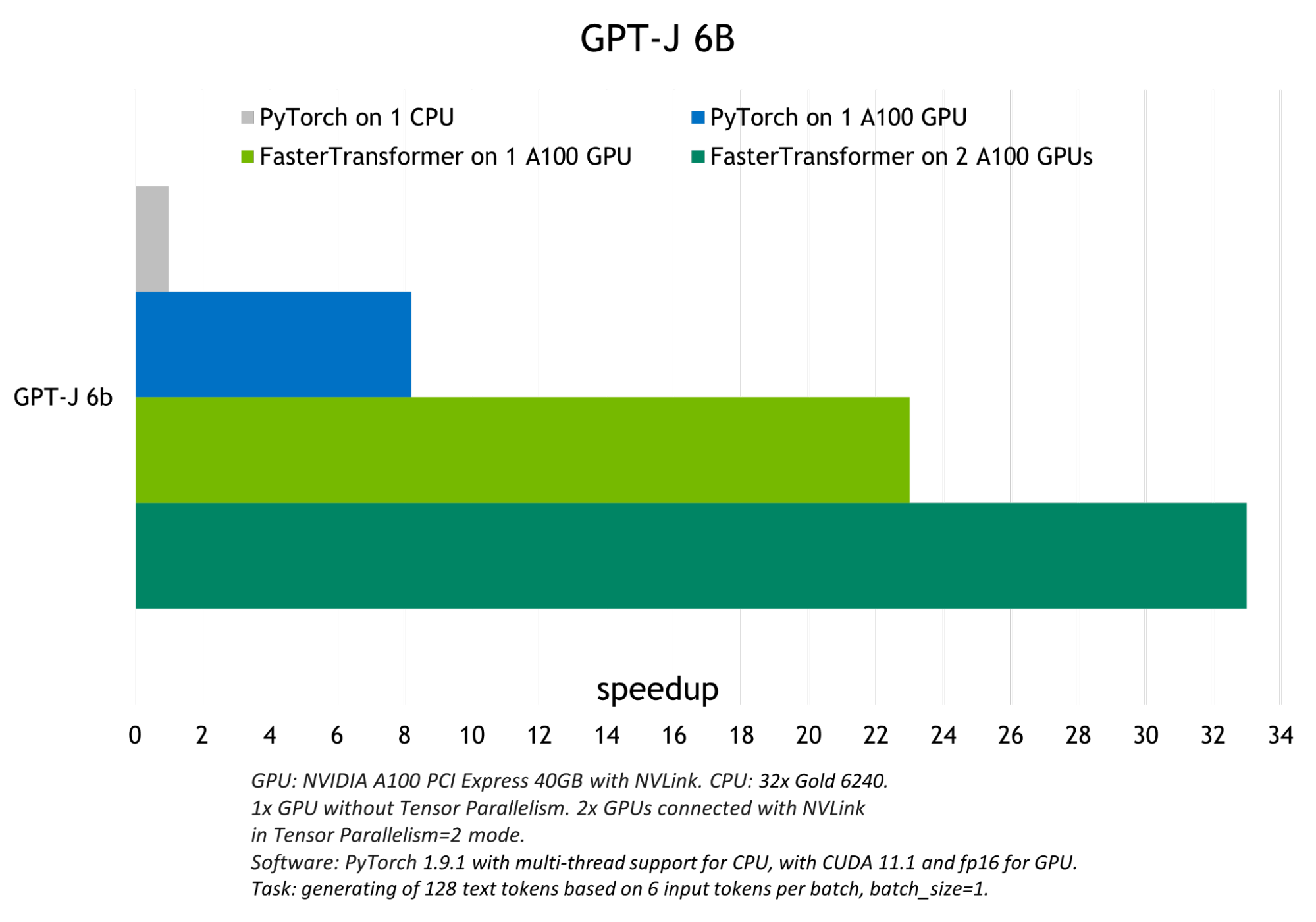
The optimizations carried out by FasterTransformer achieved up to 6x speed-up over native PyTorch GPU inference in FP16 mode and up to 33x speedup over PyTorch CPU inference for GPT-J and T5-3B.
Figure 4 shows the inference results for the GPT-J, and Figure 5 shows the inference results for T5-3B model at batch size 1 for the translation task.
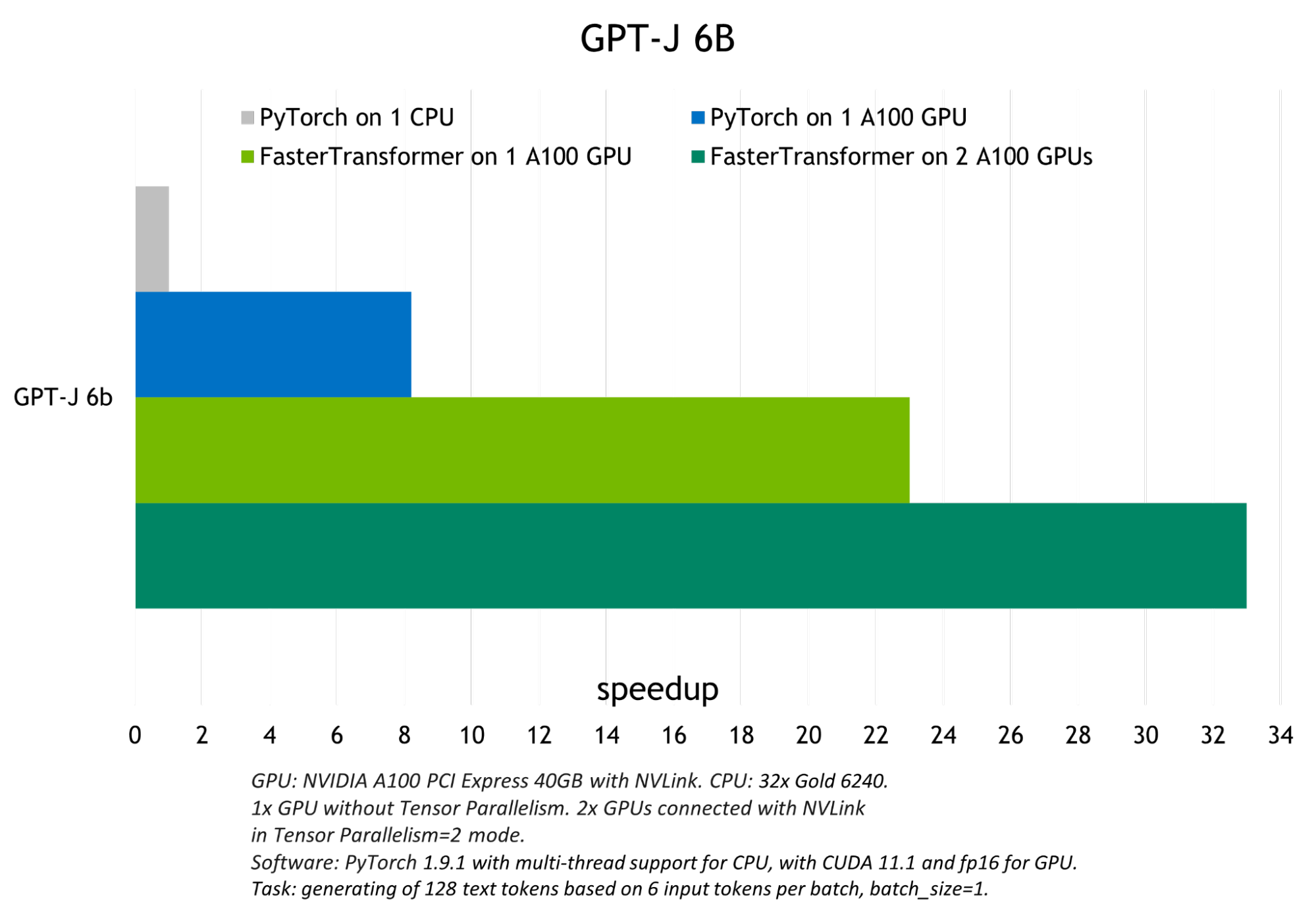
The smaller the model and the bigger the batch size, the better optimization FasterTransformer demonstrates due to increasing computational bandwidth. Figure 6 shows the T5-small model, tests of which can be found on the FasterTrasformer GitHub. It demonstrates a ~22x throughput increase in comparison with GPU PyTorch inference. Similar results can be found on GitHub for the T5-base model.

Conclusion
The code example demonstrated here uses FasterTransformer and Triton inference server to run inference of the GPT-J-6B and T5-3B models. It achieved up to 33x acceleration in comparison with CPU and up to 22x in comparison with native PyTorch backend on GPU.
The same approach can be used for small transformer models like T5-small and BERT as well as huge models with trillions of parameters like GPT-3. Triton with FasterTransformer uses techniques like tensor and pipeline parallelism to provide optimized and highly accelerated inference to achieve low latency and high throughput for all of them.
Read more about Triton and FasterTransformer or access the fastertransformer_backend example used in this post.
Training and inference of large models is a non-trivial task on the edge between AI and HPC. If you are interested in huge neural networks, NVIDIA released multiple tools that can help you make the most of them in the easiest, most efficient way.
NeMo Megatron is a new capability in the NeMo framework that allows developers to effectively train and scale language models to billions of parameters. The inferencing relies on the same tools presented in this post. Learn more with Model Parallelism: Building and Deploying Large Neural Networks, a hands-on interactive live course on theoretical and practical aspects in training and inferencing of large models.