
 Join us on July 20 for a webinar highlighting how using NVIDIA A100 GPUs can help map and location-based service providers speed up map creation and workflows, while reducing costs.
Join us on July 20 for a webinar highlighting how using NVIDIA A100 GPUs can help map and location-based service providers speed up map creation and workflows, while reducing costs.
Month: July 2022
 This post covers best practices for Vulkan clearing and presentation on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
This post covers best practices for Vulkan clearing and presentation on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
This post covers best practices for Vulkan clearing and presenting on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
With the recent Vulkan 1.3 release, it’s timely to add some Vulkan-specific tips that are not necessarily explicitly covered by the other Advanced API Performance posts. In addition to introducing new Vulkan 1.3 core features, this post shares a set of good practices for clearing and presenting surfaces.
Vulkan 1.3 Core
Vulkan 1.3 brings improvements through extensions to key parts in the API. This section summarizes our recommendations for obtaining the best performance when working with a number of these new features.
Recommended
- Skip framebuffer and render pass object setup by taking advantage of dynamic rendering.
- Reduce the number of pipeline state objects with core support for dynamic states.
- Simplify synchronization and avoid unnecessary image layout transitions by using the improved synchronization API
Clears
This section provides a guideline for achieving performance when invoking clear commands. This type of command clears a region within a color image or within the bound framebuffer attachments.
- Use
VK_ATTACHMENT_LOAD_OP_CLEARto clear attachments at the beginning of a subpass instead of clear commands. This can allow the driver to skip loading unnecessary data. - Outside of a render pass instance, prefer the usage of
vkCmdClearColorImageinstead of a CS invocation to clear images. This path enables bandwidth optimizations. - If possible, batch clears to avoid interleaving single clears between dispatches.
- Coordinate
VkClearDepthStencilValuewith the test function to achieve better depth testing performance:- 0.5 ≤ depth value VK_COMPARE_OP_LESS_OR_EQUAL
- 0.0 ≤ depth value VK_COMPARE_OP_GREATER_OR_EQUAL
Not recommended
- Specifying more than 30 unique clear values per application (or more than 15 on Turing) does not make the most of clear bandwidth optimizations.
- “Clear shaders” should be avoided unless there is overlap of a compute clear with a neighboring dispatch.
Present
The following section offers insight into the preferred way of using the presentation modes supported by a surface in order to achieve good performance.
Recommended
- Rely on
VK_PRESENT_MODE_FIFO_KHRorVK_PRESENT_MODE_MAILBOX_KHR(forVSyncon). Noteworthy aspects:VK_PRESENT_MODE_FIFO_KHRis preferred as it does not drop frames and lacks tearing.
VK_PRESENT_MODE_MAILBOX_KHRmay offer lower latency, but frames might be dropped.
VK_PRESENT_MODE_FIFO_RELAXED_KHRis compelling when your application only occasionally lags behind the refresh rate, allowing tearing so that it can “catch back up”.
- Rely on
VK_PRESENT_MODE_IMMEDIATE_KHRforVSyncoff. - On Windows systems, use the
VK_EXT_full_screen_exclusiveextension to bypass compositing. - Handle both out-of-date and suboptimal swapchains to re-create stale swapchains when windows resize, for example.
- For latency-sensitive applications, use the Vulkan Reflex SDK to minimize latency by completing game engine work just-in-time for rendering.
More information
For more information about using Vulkan with NVIDIA GPUs, see Vulkan Do’s and Don’ts.
To view the Vulkan API state, use the API Inspector in Nsight Graphics. (free download)
With Nsight Systems, you can view Vulkan usage on a unified CPU-GPU timeline, investigate stutter, and track GPU cold spots to their CPU origins. Download Nsight Systems for free.
Acknowledgments
Thanks to Piers Daniell, Ivan Fedorov, Adam Moss, Ryan Prescott, Joshua Schnarr, Juha Sjöholm, and Márton Tamás for their feedback and contributions.
 NVIDIA is helping push the limits of training AI generalist agents with a new open-sourced framework called MineDojo.
NVIDIA is helping push the limits of training AI generalist agents with a new open-sourced framework called MineDojo.
Using video games as a medium for training AI has become a popular method within the AI research community. These autonomous agents have had great success in Atari games, Starcraft, Dota, and Go. But while these advancements have been popular for AI research, the agents do not generalize beyond a very specific set of tasks, unlike humans that continuously learn from open-ended tasks.
Building an embodied agent that can attain high-level performance across a wide spectrum of tasks has been one of the greatest challenges facing the AI research community. In order to build a successful generalist agent, users need an environment that supports a multitude of tasks and goals, a large-scale database of multimodal knowledge, and a flexible and scalable agent architecture.
Enter Minecraft, the most played game in the world. With its flexible gameplay players can do a wide variety of actions. This ranges from building a medieval castle to exploring dangerous environments to gathering resources for building a Nether Portal to battle the Nether Dragon. This creative atmosphere is the perfect environment for an embodied agent to train.

To take advantage of such an optimal training ground, NVIDIA researchers created MineDojo. MineDojo has built a massive framework that features a simulation suite with thousands of diverse open-ended tasks and an internet-scale knowledge base. Building an AI powerful enough to complete these tasks would not be possible without an expansive data library.
The mission of MineDojo is to promote research towards the goal of generally capable embodied agents. In order for the embodied agent to be successful, the environment needs to provide an almost infinite number of open-ended tasks and actions. This is done by giving the agent access to a large database of information to pull knowledge and then apply learnings. The training gained from the embodied agent needs to be scalable to convert the large-scale knowledge into actionable insights later on.

In MineDojo, the embodied agent has access to three internet-scale datasets. With 750,000 Minecraft YouTube videos—amounting to over 33 years of Minecraft videos—pulled into the database, over 2 million words were transcribed.
MineDojo also scraped over 6,000 web pages from the Minecraft Wiki, with over 2.2 million bounding boxes created for the visual elements of those pages). Also, millions of Reddit threads related to Minecraft and the variety of activities one can do within the game were captured. The questions included how to solve certain tasks and showcase achievements and creations in image and video formats, along with general tips and tricks.
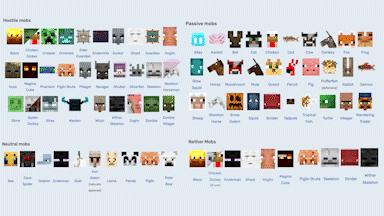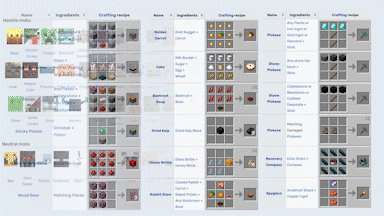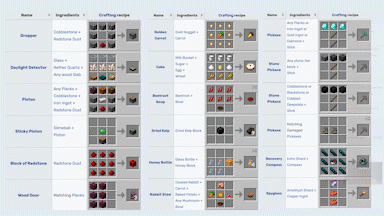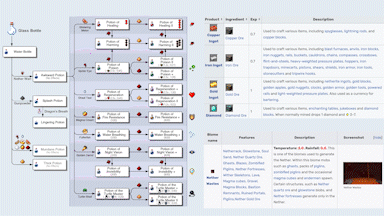
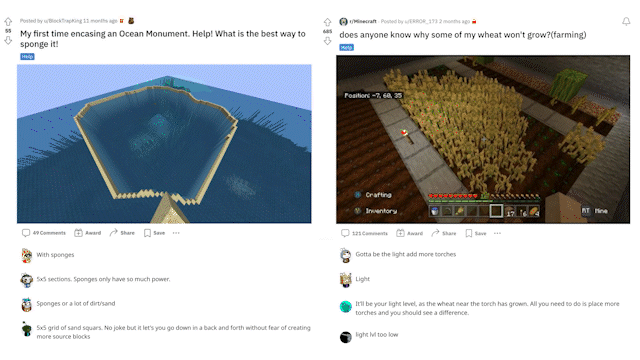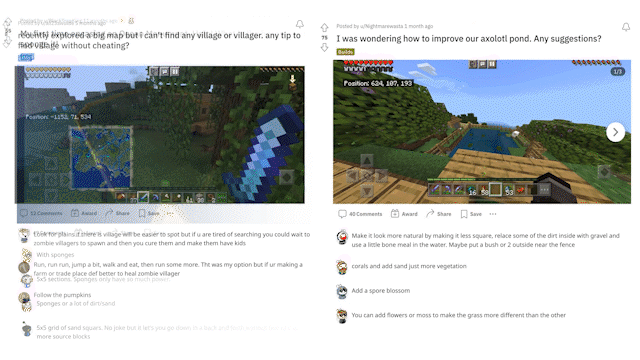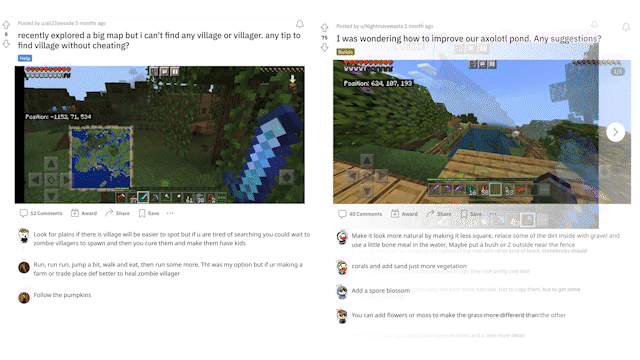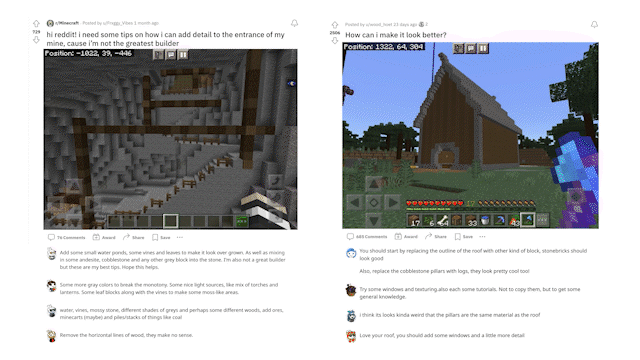
MineDojo offers a set of simulator APIs that users can use to train their AI agents. It provides unified observation and action spaces to help facilitate the agent to adapt to new scenarios and multitask. Additionally, using the APIs users can take advantage of all three worlds within the Minecraft universe to expand on the number of tasks and actions the agent can do.
Within the simulator, MIneDojo splits the benchmarking tasks into two categories: programmatic tasks and creative tasks.
Programmatic tasks are well defined and can be easily evaluated, such as “surviving 3 days” or “obtain one unit of pumpkin in the forest.”
Creative tasks are much more open-ended, such as “build a beautiful beach house.” It is very difficult to define what qualifies as a beach house by an explicit set of rules. these tasks are to encourage the research community to develop more human-like and imaginative AI agents.
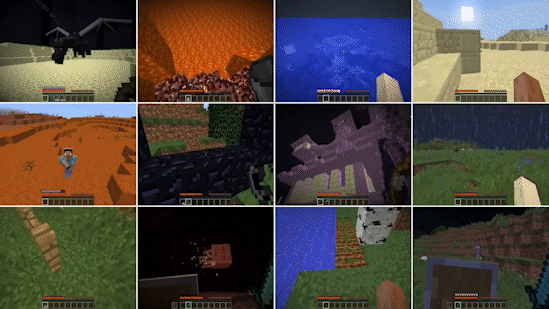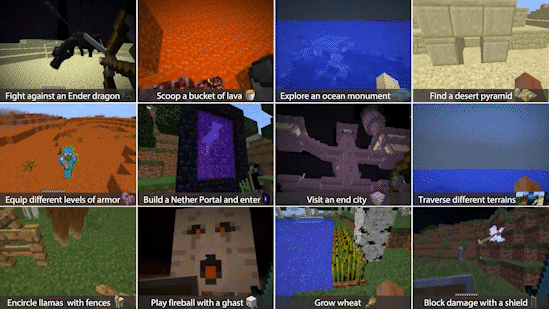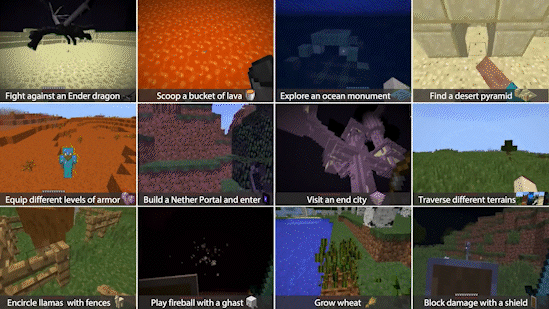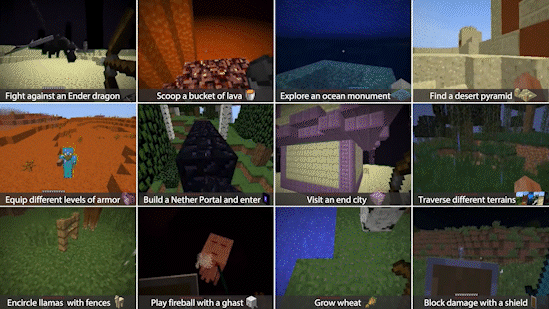
Natural language is a cornerstone of the MineDojo framework. It aids open-vocabulary understanding, provides grounding for image and video modalities, and serves as an intuitive interface to specify instructions. Combined with the latest speech recognition technology, it is possible in the near future to talk to an AI Agent as you would to a friend in multiplayer co-op mode.
For example: “plant a row of blue flowers in front of our house. Add some gold decorations to the door frame. Let’s go explore the cave next to the river,” could all be possible.
Proof of concept using MineCLIP
To help promote the project and provide a proof of concept, the MineDojo researchers have implemented a single language-prompted agent to complete several complex tasks within Minecraft, called MineCLIP. This novel agent learning algorithm takes advantage of the 33 years worth of Minecraft YouTube videos. However, it is good to point out that any agent can use any or all three sections of the Internet-scale database at the user’s discretion.
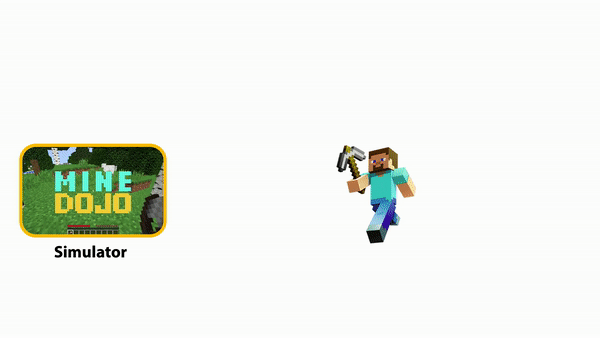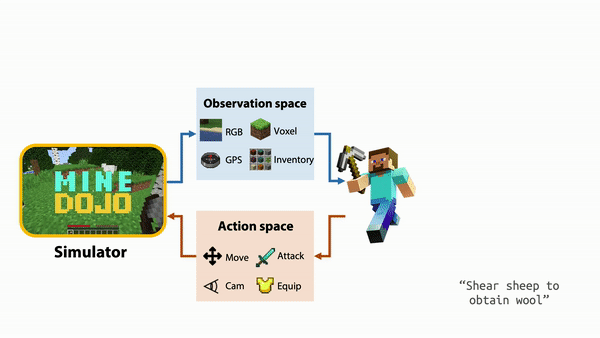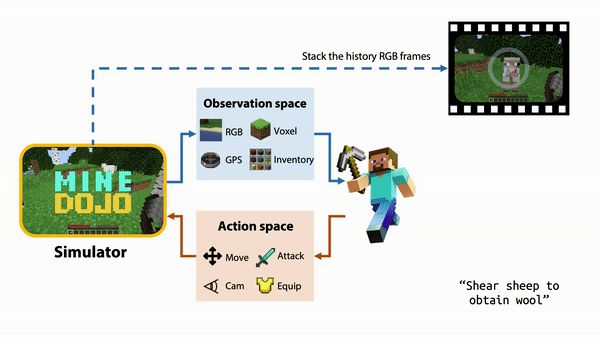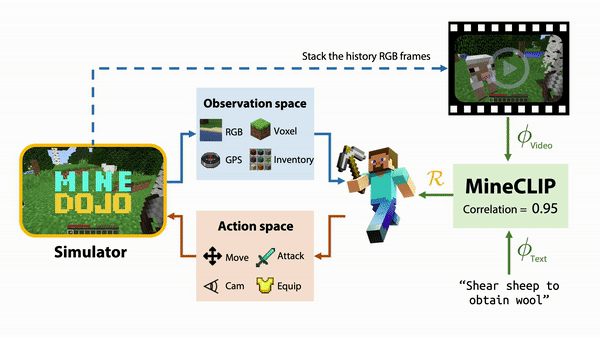
MineCLIP as an embodied agent learns from the YouTube videos the concepts and actions of Minecraft without human hand labeling. YouTubers typically narrate what they are doing as they stream the gameplay video. MineCLIP is a large Transformer model that learns to associate a video clip and its corresponding English transcripts.
This association score can be provided as a reward signal to guide a reinforcement learning agent towards completing the task. For the example task, “shear a sheep to obtain wool,” MineCLIP gives a high reward to the agent if it approaches the sheep, but a low reward if the agent wanders aimlessly. It is even capable of multitasking within the game to complete a wide range of simple tasks.
Building generally capable embodied agents is a holy grail goal of AI research. MineDojo provides a benchmark of 1000s of tasks, an internet-scale rich knowledge base, and an innovative algorithm as a first step towards solving the grand challenge.
Stay posted to see what new models and techniques the research community comes up with next! Start using MineDojo today.
Read more about the framework and its findings. Explore other NVIDIA research.