I installed TensorFlow on my machine, and I planned to use it’s RTX 3070 for training the AI, when I try to run AI on the GPU, I reach the first epoch, but it does not start the training for some reason, and exits with code -1073740791, whenever I try to train the AI on the CPU everything works as intended.
I tried to research this exit code but have found no solutions, all help is appreciated.
Running using GPU:
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.saving.functional_saver has been moved to tensorflow.python.checkpoint.functional_saver. The old module will be deleted in version 2.11. WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.saving.checkpoint_options has been moved to tensorflow.python.checkpoint.checkpoint_options. The old module will be deleted in version 2.11. 2022-06-26 01:21:38.574693: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2022-06-26 01:21:40.878221: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1616] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 5472 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6 2022-06-26 01:22:54.239669: W tensorflow/core/framework/cpu_allocator_impl.cc:82] Allocation of 4414046208 exceeds 10% of free system memory. Epoch 1/10 2022-06-26 01:23:34.205541: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8401
Process finished with exit code -1073740791 (0xC0000409)
Running using the CPU: WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.saving.functional_saver has been moved to tensorflow.python.checkpoint.functional_saver. The old module will be deleted in version 2.11. WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.saving.checkpoint_options has been moved to tensorflow.python.checkpoint.checkpoint_options. The old module will be deleted in version 2.11. 2022-06-26 01:28:48.257288: E tensorflow/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected 2022-06-26 01:28:48.278422: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: DESKTOP-REDACTED 2022-06-26 01:28:48.278631: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: DESKTOP-REDACTED 2022-06-26 01:28:48.287345: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. Epoch 1/10 8/702 [..............................] - ETA: 16:01 - loss: 2.9990 - accuracy: 0.5078 Process finished with exit code -1
This neural network seems to be working fine when NUM_CLASSES = 15, but when I try to add more labels it is unable to train the model and the accuracy stay stable at 0.05. Any ideas on what might be wrong?
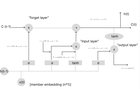
Say I wanted to build an LSTM architecture like the below. My input is a matrix of size [n * 10] where n is the rows (each row represents an embedded vector) and 10 is the columns. My output should be a prediction of an embedded vector of size [1 *10], this data is available from a “future” date. Would the following code do what I am looking for?
The CUDA library, nvCOMP, now offers support for zStandard and Deflate standards, as well as modified-CRC32 checksum support and improved ANS performance.
Considering new security software? AI and security experts Bartley Richardson and Daniel Rohrer from NVIDIA have advice: Ask a lot of questions.
Cybersecurity software is getting more sophisticated these days, thanks to AI and ML capabilities. It’s now possible to automate security measures without direct human intervention. The value in these powerful solutions is real—in stopping breaches, providing highly detailed alerts, and protecting attack surfaces. Still, it pays to be a skeptic.
This interview with NVIDIA experts Bartley Richardson and Daniel Rohrer covers key issues such as AI claims, the hidden costs of deployment, and how to best use the demo. They recommend a series of questions to ask vendors when considering investing in AI-enabled cybersecurity software.
Richardson leads a cross-discipline engineering team for AI infrastructure and cybersecurity, working on ML and Deep Learning techniques and new frameworks for cybersecurity. Rohrer, vice president of software security, has held a variety of technical and leadership roles during his 22 years at NVIDIA.
1. What type of AI is running in your software?
Richardson: A lot of vendors claim they have AI and ML solutions for cybersecurity, but only a small set of them are investing in thoughtful approaches using AI that address the core issue of cybersecurity as a data problem. Vendors can make claims that their solutions can do all kinds of things. But those claims are really only valid if you also have X, Y, and Z in your ecosystem. The conditions on their claims get buried most of the time.
Rohrer: It’s like saying that you can get these great features if you have full ptrace logs that go across your network all day long. Who has that? No one has that. It is cost-prohibitive.
Richardson: Oh sure, we can do amazing things for you. You just need to capture, store, and catalog all of the packets that go across your network. Then devote a lot of very powerful and expensive servers to analyzing those packets, only to then require 100 new cybersecurity experts to interpret those results. Everyone has those resources, right?
But seriously, AI is not magic. It’s math. AI is just another technique. You have to look critically at AI. Ask your vendor, what type of AI is running in their software and where are they running it? Because AI is used for everything, but not everything is AI. Overselling and underdelivering are causing “AI fatigue” in the market. People are getting bombarded with this all the time.
2. What deployment options can you offer?
Rohrer: Many people have hybrid cloud environments and a solution that works in just part of your environment. Certainly for cyber, it’s often deficient. How flexible is their deployment? Can they run in the cloud? On prem? In multiple environments like Linux, Windows, or whatever is needed to protect your data and achieve your goals?
You need the right multicloud. For example, we use Google and Alibaba Cloud and AWS and Azure. Do they have a deployable solution in all those environments, or just one of those environments? And do we need that? Sometimes we don’t need that, sometimes we do. Cybersecurity is one of those use cases where we need logs from everywhere. So understand your solution space and know how flexible your deployment model needs to be to solve your problem. And bake that in.
Cyber is often one of the harder ones to pull off, because we have lots of dynamic ephemeral data. We’re often in many, many complex heterogeneous environments that are data-heavy and IO-heavy. So if you want a worst case scenario, cyber is often it.
Richardson: There could be hidden costs in deployment, too. If you have an environment where the vendor is saying you can get all this AI, but by the way, you have to use our cloud. There’s an associated cost—if you’re not already cloud-native and pushing your data to the cloud—in time, engineering, and money.
Rohrer: Even if you are cloud-native, there’s I/O overhead to push whatever data you have over to them. And all of the sudden, you have a million-dollar project on your hands.
3. What new infrastructure will I need to buy to run your software?
Rohrer: What infrastructure will you need to deploy your model? Do you have what you need, or can you readily purchase it without exorbitant costs? Can you afford it? If it’s an on-prem solution, does the proposal include the additional infrastructure you’re going to need? If it’s cloud-based, does it include all the cloud instances and data ingress/egress fees, or are those all extra?
Richardson: If you’re telling me something is additive, great. If you’re telling me something’s rip and replace, that’s a different proposition.
4. How will you protect my model?
Richardson: People usually ask about data. How are you protecting my data?Is it isolated? Is it secure? Those are good questions to ask. But what happens when a service provider customizes an AI model for me?What are their policies around protecting that fine-tuned model for my environment? How are you protecting my model?
Because if they’re doing anything that’s real with ML or deep learning, the model is just as valuable as the data it’s trained on. It’s possible to back out training and fine-tuning data from a trained model, if you are sufficiently experienced with the techniques.
That means it’s possible for people to access my sensitive information. My data didn’t leak, but this massive embedding space of my neural net leaked, and now it’s possible for someone, with a lot of work, to back out my training data. And not a lot of people are encrypting models. The constant encrypt/decrypt would totally thrash your throughput. There should be policies and procedures in place, ideally ones that can be automatically enforced, that protect these models. Ensure that your vendor is following best practices around implementing the least privileges possible when those models contain embeddings of your data.
5. What can you do with my data?
Rohrer: There are many service providers who are aggregating data and events across customers to improve a model for everyone, which is fine as long as you’re up front about it. But you know, one question to ask is whether your data is being used to improve a model for competitors or everyone else in the market?And make sure that you’re comfortable with that. In some cases that’s fine, if it’s weather data or whatever. Sometimes not so much. Because some of that data and the models you build from it have a real competitive advantage for you.
Richardson: I always come back to companies like Facebook and Twitter. The real value for them is your data. So they can use everyone’s data and training–and that gives them a superior ability and extra value. They’re selling you a service or a product and using your data to improve it.
6. Can I bring my data to the demo?
Rohrer: Preparing for the demo is important, because that’s really where the rubber hits the road for most folks.
Richardson: Yeah, ideally you should have a set of criteria going in. Know what your requirements are. Maybe you have some incident or misconfiguration or problem. Can AI address that?Can we see it run in a customer environment, not just in your sandbox environment?
Rohrer: Bring your problems to the demo.
7. Does your solution require tuning, and if so, how often?
Rohrer: One recommendation is to bring some of your own data to the table. How do I ingest my data?What is the efficacy of problems that I actually have, not the one that the demo team is telling me I should have? And see how it performs with your data. If it doesn’t work with your data unless they tune it, then you know it’s not just buy and deploy. Now it’s a deploy after 3 months, 6 months, maybe 9 months of tuning.Now it’s not just a product purchase. It’s a purchase and integration contract and a support contract and the costs add up before you realize it.
8. How easy is your solution for our engineers to learn and use?
Richardson:A lot of people don’t evaluate the person load. I know that’s hard to do in a trial. But whether it’s cybersecurity or IT or whatever, get your people evaluating that. Get your engineers involved in the process. Ask how will your engineers interact with the new software on a daily basis?We see this a lot, especially in cybersecurity, where you’ve added something to do function X. And in the end, it just creates more cognitive load on your humans that are working with it. It’s generating more noise than they can handle, even if it’s doing it at a pretty low false-positive rate. It’s additive.
Rohrer: Yeah, it’s 99% accurate, but it doubled the number of events your people have to deal with. That didn’t help them.
Richardson: AI is not magic. It’s just math. But it’s framed in the context of magic. Just be willing to look at AI critically. It’s just another technique. It’s not a magic bullet that is going to solve all your problems. We’re not living in the future yet.
About Bartley Richardson
Bartley Richardson is Director of Cybersecurity Engineering at NVIDIA and leads a cross-discipline team researching GPU-accelerated ML and Deep Learning techniques and creating new frameworks for cybersecurity. His interests include NLP and sequence-based methods applied to cyber network datasets and threat detection. Bartley holds a PhD in Computer Science and Engineering working on loosely and unstructured logical query optimization, and a BS in Computer Engineering with a focus on software design and AI.
Daniel Rohrer is VP of Software Product Security at NVIDIA. In his 23 years at NVIDIA, he has held a variety of technical and leadership roles. Daniel has taken his integrated knowledge of ‘everything NVIDIA’ to hone security practices through the delivery of advanced technical solutions, reliable processes, and strategic investments to build trustworthy security solutions. He has a MS in Computer Science from the University of North Carolina, Chapel Hill.
Published in Nature Machine Intelligence, a panel of experts shares a vision for the future of biopharma featuring collaboration between ML and drug discovery powered by GPUs.
The field of drug discovery is at a fascinating inflection point. The physics of the problem are understood and calculable, yet quantum mechanical calculations are far too expensive and time consuming. Eroom’s Law observes that drug discovery is becoming slower and more expensive over time, despite improvements in technology.
Published in Nature Machine Intelligence, the review details numerous advances in challenges from molecular simulation and protein structure determination to generative drug design that are accelerating the computer-aided drug discovery workflow. These advances, driven by developments in highly parallelizable GPUs and GPU-enabled algorithms, are bringing new possibilities to computational chemistry and structural biology for the development of novel medicines.
The collaboration between researchers in drug discovery and machine learning to identify GPU-accelerated deep learning tools is creating new possibilities for these challenges that if solved, hold the key to faster, less expensive drug development.
“We expect that the growing availability of increasingly powerful GPU architectures, together with the development of advanced DL strategies, and GPU-accelerated algorithms, will help to make drug discovery affordable and accessible to the broader scientific community worldwide,” the study authors write.
Molecular simulation and free energy calculations
Molecular simulation powers many calculations important in drug discovery and is the computational microscope that can be used to perform virtual experiments using the laws of physics. GPU-powered molecular dynamics frameworks can simulate the cell’s machinery lending insight into fundamental mechanisms and calculate how strongly a candidate drug will bind to its intended protein target using calculations like free energy perturbation. Of central importance to molecular simulation is the calculation of potential energy surfaces.
In the highlighted review, the authors cover how machine-learned potentials are fundamentally changing molecular simulation. Machine-learned or neural network potentials are models, which learn energies and forces for molecular simulation with the accuracy of quantum mechanics.
The authors report that free energy simulations benefit greatly from GPUs. Neural network-based force fields such as ANI and AIMNet reduce absolute binding free-energy errors and human effort for force field development. Other deep learning frameworks like reweighted autoencoder variational Bayes (RAVE) are pushing the boundaries of molecular simulation, employing an enhanced sampling scheme for estimating protein-ligand binding free energies. Methods like Deep Docking are now employing DL models to estimate molecular docking scores and accelerate virtual screening.
Advances in protein structure determination
Over the last 10 years, there has been a 2.13x increase in the number of protein structures publicly available. An increasing rate of CryoEM structure deposition and the proliferation of proteomics has further contributed to an abundance of structure and sequence data.
CryoEM is projected to dominate high-resolution macromolecular structural determination in the coming years with its simplicity, robustness, and ability to image large macromolecules. It is also less destructive to samples as it does not require crystallization.
However, the data storage demands and computational requirements are sizable. The study’s authors detail how deep learning based approaches like DEFMap and DeepPicker are powering high-throughput automation of CryoEM for protein structure determination with the help of GPUs. With DEFMap, molecular dynamics simulations that understand relationships in local density data and deep learning algorithms are combined to extract dynamics associated with hidden atomic fluctuations.
The groundbreaking development of AlphaFold-2 and RoseTTAFold models that predict protein structure with atomic accuracy is ushering in a new era structure determination. A recent study by Mosalaganti et al. highlights the predictive power of these models. It also demonstrates how protein structure prediction models can be combined with cryoelectron tomography (CryoET) to determine the structure of the nuclear pore complex, a massive cellular structure comprised of over 1,000 proteins. Mosalagneti et al. go on to perform coarse-grained molecular dynamics simulations of the nuclear pore complex. This gives a glimpse into the future of the kinds of simulations made possible by the combination of AI-based protein structure prediction models, CryoEM and CryoET.
Generative models and deep learning architectures
One of the central challenges of drug discovery is the overwhelming size of the chemical space. There are 1060 drug-like molecules to consider, so researchers need a representation of the chemical space that is organized and searchable. By training on a large base of existing molecules, generative models learn the rules of chemistry and to represent chemical space in the latent space of the model.
Generative models, by implicitly learning the rules of chemistry, produce molecules that they’ve never seen before. This results in exponentially more unique, valid molecules than in the original training database. Researchers can also construct numerical optimization algorithms that operate in the latent space of the model to search for optimal molecules. These function as gradients in the latent space that computational chemists can use to steer molecule generation toward desirable properties.
The authors report that numerous state-of-the-art deep learning architectures are driving more robust generative models. Graph neural networks, generative adversarial networks, variational encoders, and transformers are creating generative models transforming molecular representation and de novo drug design.
Convolutional neural networks, like Chemception, have been trained to predict chemical properties such as toxicity, activity, and solvation. Recurrent neural networks have the capacity to learn latent representations of chemical spaces to make predictions for several datasets and tasks.
MegaMolBART is a transformer-based generative model that achieves 98.7% unique molecule generation at AI-supercomputing scale. With support for model parallel training, MegaMolBART can train 1B+ parameter models for training on large chemical databases and is tunable for a wide range of tasks.
The Million-X leap in scientific computing
Today, GPUs are accelerating every step of the computer aided drug discovery workflow, showing effectiveness in everything from target elucidation to FDA approval. With accelerated computing, scientific calculations are being massively parallelized on GPUs.
Supercomputers help these calculations to be scaled up and out to multiple nodes and GPUs, leveraging fast communication fabrics to tie GPUs and nodes together.
AT GTC, NVIDIA CEO Jensen Huang shared how NVIDIA has accelerated computing by a million-x over the past decade. The future is bright for digital biology, where these speed-ups are being realized to speed up drug discovery and deliver therapeutics to market faster.
You may not know of Todd Mozer, but it’s likely you have experienced his company: It has enabled voice and vision AI for billions of consumer electronics devices worldwide. Sensory, started in 1994 from Silicon Valley, is a pioneer of compact models used in mobile devices from the industry’s giants. Today Sensory brings interactivity to Read article >
To foster climate action for a healthy global environment, NVIDIA is working with the United Nations Satellite Centre (UNOSAT) to apply the powers of deep learning and AI. The effort supports the UN’s 2030 Agenda for Sustainable Development, which has at its core 17 interrelated Sustainable Development Goals. These SDGs — which include “climate action” Read article >


 The CUDA library, nvCOMP, now offers support for zStandard and Deflate standards, as well as modified-CRC32 checksum support and improved ANS performance.
The CUDA library, nvCOMP, now offers support for zStandard and Deflate standards, as well as modified-CRC32 checksum support and improved ANS performance. Considering new security software? AI and security experts Bartley Richardson and Daniel Rohrer from NVIDIA have advice: Ask a lot of questions.
Considering new security software? AI and security experts Bartley Richardson and Daniel Rohrer from NVIDIA have advice: Ask a lot of questions.

 Published in Nature Machine Intelligence, a panel of experts shares a vision for the future of biopharma featuring collaboration between ML and drug discovery powered by GPUs.
Published in Nature Machine Intelligence, a panel of experts shares a vision for the future of biopharma featuring collaboration between ML and drug discovery powered by GPUs.{kind=link}