 Jacques Khisa, community leader at Africa Data School Emerging Chapters Nairobi, shares his experience on getting started in AI in Africa.
Jacques Khisa, community leader at Africa Data School Emerging Chapters Nairobi, shares his experience on getting started in AI in Africa.
In the quest for knowledge in understanding data, I never pictured my passion shifting towards AI. As a matter of fact, AI is all data!
For context, the major hindrance to the implementation of AI projects across the African continent has been the lack of digitized data upon which AI algorithms are built. In my local region of Kenya, for instance, we have struggled to convert data stacked in traditional formats in both public and private data silos, despite a higher penetration of digital products in the past decade compared to neighboring countries.
Ironically, this incentivized my enthusiasm for AI and created the need to help democratize it. As Paulo Coelho said in The Alchemist, “And, when you want something, all the universe conspires in helping you to achieve it.”
NVIDIA Emerging Chapters
With my particular interest in natural language processing, I attended the AI Expo Africa virtual conference to enable me to network with local developers, experts, and researchers in the field of AI.
There, I had a life-changing conversation with the head of Developer Ecosystems and Strategic Partnerships at NVIDIA, Amulya Vishwanath, about the Emerging Chapters program. This is a program that enables local communities in emerging areas to build and scale AI, data science, and graphics projects by providing the following:
- Technological tools
- Educational resources
- Co-marketing opportunities
In Kenya, the academic and entrepreneurial communities are particularly active. Emerging AI hotspots are mostly in academia.
Being a young conversational AI developer, I faced constraints in obtaining compute resources, research papers, and a feasible guide into the immense field of deep learning. I looked for educational opportunities to help other young enthusiasts easily access these resources and practice AI for good in my local community.
Training opportunities
As the NVIDIA DLI Ambassador and Certified DLI Instructor in deep learning and conversational AI at the Africa Data School community, I helped enable members of the Emerging Chapters to have access to training and development opportunities through the NVIDIA Deep Learning Institute (DLI). This includes free passes to select self- or instructor-led courses on AI and data science. Developers receive a NVIDIA DLI certificate upon course completion that highlights their skills, thereby advancing their careers.
Since partnering with NVIDIA, members have had great exposure and high participation in the NVIDIA GTC conference and DLI workshops. I was able to help facilitate these workshops at the Nairobi Garage co-working space, which not only allowed the attendees to get connected to a dynamic community of innovative companies and professionals but also increased our scale and impact.
The training gave participants access to world-class best practices, and knowledge to facilitate their development as AI engineers. Although some students find the content challenging, their enthusiasm is contagious. The content uses real-life case studies and shows the application of different deep learning algorithms on end-to-end applications in startups.
As individuals in my local community make full use of these resources, more talent becomes available, which consequently attracts and increases investments, accelerating growth.
After our in-person workshop, I realized that we needed more talent to educate and inspire. As it was our first workshop, we only provided 20 students with GPU instances and course materials from NVIDIA DLI. There will be many more workshops to come. We are also using free DLI courses that we were granted as part of the Emerging Chapters program to frequent training participants.
Working with the Africa Data School Emerging Chapter community has literally enabled the democratization of AI through the provision of educational resources and development opportunities in my region. Our goal is to create a community of young researchers, developers, AI engineers, and students passionate about NLP and computer vision in fintech, education, and agriculture.
These projects are in line with the Kenya Vision 2030: transforming Kenya into a newly industrializing, middle-income country that provides a high quality of life to all its citizens.
Student feedback from the first workshop
“Deep Learning doesn’t have to be a black box and is a potent tool in the right context with proper constraints. We discussed and implemented the various aspects and techniques fundamental to deep learning at the workshop. The level of discussion and implementation continues to showcase the sheer engineering talent in Kenya and the deep technical talent pool that we are known for across the continent. More efforts such as this will be vital in cementing our position as the Silicon Savannah. We appreciate NVIDIA for providing their state-of-the-art cloud-based GPU compute resources.”
Wilfred Odero
“The AI space is evidently a partnership-intensive space ranging from data collectors, developers, computing resources manufacturers, data regulators, etc. I may not have a clear bird’s-eye view of the scale of what’s happening on the ground, but from where I sit, the continent is taking off in terms of organizing itself toward a structure/ecosystem of some sort that supports the continent’s unanimous AI strategy and AI policy frameworks, with efforts such as the AU-commissioned ‘African stance on Artificial Intelligence’ and a number of big-tech sponsored tech hubs specializing on AI/ML-focused solutions. At the moment, most of the effort is being put into developing ready talent, though all stakeholders need to be ready.”
Rita Grace
“The exciting world of deep learning was introduced with practical examples and by the end of the day we could train models with over 95% accuracy. The training was well planned and our instructor Jacques Khisa explained all the topics in detail. It was a great experience to set up my own AI application development environment and earn a certificate in Fundamentals of Deep Learning. I would like to thank NVIDIA AI Emerging Chapters and Africa Data School for their workshops and commitment to developing future leaders in AI.”
Ibrahim Abdi
Conclusion
Joining the NVIDIA developer program and making Africa Data School a part of the Emerging Chapters community has helped us elevate our technology skills and connect with like-minded local and global professionals.
The NVIDIA Emerging Chapters program is for developer communities. If you are interested in starting a local chapter, apply to the NVIDIA Emerging Chapters pilot program.
For more about developer communities and upcoming educational series webinars, see the NVIDIA Emerging Chapters program page.

 This post covers best practices for using SetStablePowerState on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
This post covers best practices for using SetStablePowerState on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.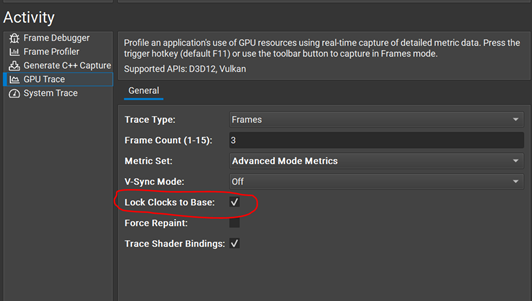
 Experience the “Summer of Jetson” now through Sept. 30, with quizzes, prizes, and a project showcase to learn about the joys of working with Jetson Nano developer kit.
Experience the “Summer of Jetson” now through Sept. 30, with quizzes, prizes, and a project showcase to learn about the joys of working with Jetson Nano developer kit.