NVIDIA and its partners continued to provide the best overall AI training performance and the most submissions across all benchmarks with 90% of all entries coming from the ecosystem, according to MLPerf benchmarks released today. The NVIDIA AI platform covered all eight benchmarks in the MLPerf Training 2.0 round, highlighting its leading versatility. No other Read article >
Learn about the full-stack optimizations that enabled the NVIDIA platform to deliver even more performance in MLPerf Training v2.0.
MLPerf benchmarks are developed by a consortium of AI leaders across industry, academia, and research labs, with the aim of providing standardized, fair, and useful measures of deep learning performance. MLPerf training focuses on measuring time to train a range of commonly used neural networks for the following tasks:
Natural language processing
Speech recognition
Recommender systems
Biomedical image segmentation
Object detection
Image classification
Reinforcement learning
Lower training times are important to speed time to deployment, minimizing the total cost of ownership and maximizing return on investment.
However, just as important as a platform’s performance is its versatility. The ability to train every model, as well as provide infrastructure fungibility to run all AI workloads from training to inference, is critical to allowing organizations to maximize return on their infrastructure investments.
The NVIDIA platform, with full-stack innovation and a rich developer and application ecosystem, continues to be the only one to submit results on all eight MLPerf Training tests, as well as to submit on all MLPerf Inference and MLPerf high-performance computing (HPC) tests.
In this post, you will learn about the methods that NVIDIA deployed across the entire stack to deliver more performance in MLPerf v2.0.
Through continued innovation across the entire stack, including system software, libraries, and algorithms, NVIDIA has yet again delivered performance improvements compared to prior submissions using the same A100 Tensor Core GPU.
Compared to NVIDIA MLPerf v0.7 submissions, which marked the first A100 Tensor Core GPU submissions, results showed gains of up to 2.1x on a per-chip basis, and 5.7x for max-scale training (Table 1).
Benchmark
v2.0 Max-Scale Time to Train (min) (vs. v1.1) (vs. v0.7)
v2.0 Per-Accelerator Time to Train (min) (vs. v1.1) (vs. v0.7)
Per-Accelerator performance for A100 computed using 8xA100 server time-to-train and multiplying it by 8. 3D U-Net and RNN-T were not part of MLPerf v0.7. (**) RetinaNet was not part of either MLPerf v0.7 or v1.1. MLPerf name and logo are trademarks. For more information, see www.mlperf.org.
The following sections highlight some of the work done to achieve these improvements.
BERT
The latest NVIDIA BERT submission took advantage of the following optimizations:
Sequence packing
Fusion of fully connected and GELU layers
Sequence packing
In previous rounds, the overhead related to padding required to fill up the batch was already optimized by introducing an unpadding optimization. Unpadding, however, results in dynamically sized buffers, as the total number of tokens is not fixed anymore.
This is not an issue when we do not have to use CUDA graphs, such when large-batch sizes are used. However, for small batch sizes, where CUDA graphs are used to reduce CPU overhead, dynamically sized buffers require many separate graphs for each possible size. To take advantage of CUDA graphs efficiently while minimizing the overhead of padding, NVIDIA used the concept of sequence packing this round.
In MLPerf Bidirectional Encoder Representations from Transformers (BERT), a training sample has been restricted to 512 tokens, but it often has fewer tokens than 512. As the training sequences have different lengths, it is possible to fit more than one sequence within a 512-token sample.
Sequence packing requires that the length distribution of the training set sequences be known in advance. The sequences can be merged into packed samples such that none of the merged samples exceed a length of 512 tokens.
NVIDIA used a similar packing algorithm that another submitter used in MLPerf v1.1. Adopting an algorithm from a different submitter was made possible by the high degree of general-purpose programmability of GPUs.
To strike a good balance between implementation complexity and performance, up to three sequences were packed in per sample. This results in each training sample containing a varying number of sequences as a batch of three samples can each contain three to nine sequences.
CUDA graphs require buffer sizes to be fixed across time for each graph. The varying number of total sequences was handled by creating a separate graph for each possible number of sequences within a batch.
For large-scale training, we used a batch size of two per chip. This translates into five to seven separate graphs, which is much less than would be required with the unpadding optimization mentioned at the beginning.
Overall, this technique improved the results for large-scale runs by 10% and 33% for 4096-GPU and 1024-GPU scenarios, respectively.
Fusion of fully connected and GELU layers
BERT uses a Gaussian error linear unit (GELU) activation function that follows a fully connected layer. In prior submissions, the GELU activation function was implemented as a single kernel. This approach required additional memory transactions for both input reads and output writes.
In this round, NVIDIA implemented the fusion of a fully connected layer (a matrix multiply operation) with the GELU activation function. This eliminated the need for a large number of memory read and write operations, yielding a 2-4% increase in overall throughput – larger gains are observed for larger per-chip batch sizes.
In general, it is more efficient to fuse activation math into the end of matrix multiply operations, which means fusing the GELU activation function into different fully connected layers (Figure 1).
Figure 1. Left: Pattern of operations in BERT, middle: Fusion graph in forward pass, right: Fusion graph in backward pass. Each box represents a single kernel.
Deep learning recommendation models
The latest NVIDIA deep learning recommendation models (DLRM) submission again leverages NVIDIA Merlin HugeCTR, an optimized open-source deep neural network training framework for recommender systems.
Kernel fusions
Multilayer perceptrons (MLP) represent a key building block for DLRM. To reduce the number of trips to global memory, fusions of elementwise kernels and general matrix multiply (GEMM) kernels have been widely employed.
The NVIDIA cuBLAS library has recently introduced a new fusion type: GEMM with DReLU (fusing ReLU gradient computation with matrix multiply operations in the backward pass). HugeCTR takes advantage of this new fusion type to enhance the performance of MLPs.
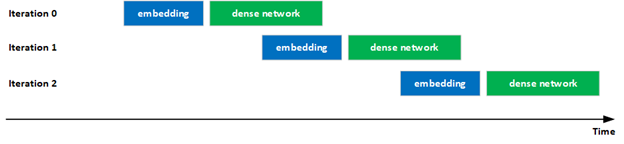
Improved overlap of computation and communication
Increasing GPU utilization is important to provide the highest performance.
In this latest submission, NVIDIA notably improved the overlap of computations and communications in the evaluation of hybrid embeddings to improve GPU utilization. Specifically, the execution of the dense network in iteration i overlapped with the execution of the embedding in iteration i+1 through pipelining, increasing the utilizations of the GPUs.
This overlapping is possible because there are no inter-iteration dependences in the evaluation phase.
Additionally, several of the key kernels in the forward/backward hierarchical all-to-all operations for hybrid embedding were also optimized.
Figure 2. Overlapping execution of embedding and dense network
ResNet-50
For ResNet-50, we employed the following optimizations to boost performance:
Better max-scale training configuration
Faster cuDNN kernels
Better max scale training configuration
When a model is trained on a large scale, if the global batch size is not an integer multiple of the training images in the dataset, the last iteration of the epoch gets added extra data to keep the batch size consistent across iterations. This wasted computation can be saved if the global batch size is close to the integer multiple of the dataset. This is especially important for larger-scale training, where the global batch size is relatively large.
In this round of MLPerf, we concluded that using 527 nodes with a global batch size of 67,456 significantly reduced wasted computation, resulting in a performance boost of 3.5% compared to NVIDIA’s ResNet-50 submission in MLPerf v1.1.
Faster CuDNN kernels
For the ResNet50 submission, NVIDIA significantly improved the kernels picked up by cuDNN. This includes both better kernels being picked up for the layer sizes and optimized kernel implementation for different tile sizes.
From these optimized kernel samplings, we observed over 4% throughput improvement in the large-scale configurations from MLPerf v1.1.
RetinaNet
The NVIDIA RetinaNet submission takes advantage of several software optimizations, including:
Channel last memory format and automatic mixed precision
Using fusion for speed-up
Optimizing loss block
Asynchronous scoring
CUDA Graphs
Channel last memory format and automatic mixed precision
For the RetinaNet submission, NVIDIAtook advantage of several fusion opportunities. The cuDNN runtime fusion through the Apex library was used to fuse CONV-bias-ReLU and CONV-bias patterns, and PyTorch NVFuser were used to fuse element-wise operations, such as scale-bias-ReLU and scale-bias-add-ReLU.
The cuDNN runtime fusion Python interface can be found in the Apex repository (import ConvBiasReLU or ConvBias from apex.contrib.conv_bias_relu).
Optimizing loss block
The RetinaNet loss-related calculations are separated into two stages: ground truth data preprocessing and the actual loss calculation.
As the ground truth data preprocessing is not dependent on the model output, part of the ground truth data processing was offloaded to DALI with custom functions, enabling it to be performed asynchronously, improving system resource utilization. The remainder of the preprocessing was reimplemented and then merged into the model graph to avoid jitter.
For the loss calculation, an optimized focal loss implementation was used, which can be found in the Apex library.
Asynchronous scoring
The RetinaNet submission guidelines require that evaluation (inference and scoring) be performed after each training epoch. The scoring time overhead is significant due to the large number of images and bounding boxes in the OpenImages validation dataset, as well as the sequential implementation of the scoring code.
To mitigate the scoring overheads—particularly in large-scale execution, asynchronous scoring was implemented so that the next training epoch masked the previous epoch scoring procedure.
Figure 3. Execution of asynchronous COCO scoring in evaluation
CUDA Graphs
CUDA Graphs were used extensively in the NVIDIA RetinaNet submission. The entire model and portions of the ground truth preprocessing were graphed which required that they be reimplemented to fit CUDA graph constraints.
The model’s forward and backward passes were graph captured, as well as portions of the ground truth preprocessing. The latter required code adaptation to fit CUDA graph constraints.
The NVIDIA Mask R-CNN submissions utilized several techniques to improve performance:
Bottleneck block optimizations
RPN head fusion
Evaluation
Top-K
Bottleneck block optimizations
The resnet backbone is built as a stack of bottleneck blocks, each composed of three sequential convolutions. Each convolution is followed by a batch-norm and a ReLu. The batch-norm modules have four parameters, and some math is required to compute a couple of intermediate terms in the forward method.
As the batch-norms are frozen, the parameters never change, meaning that the intermediate terms do not change either. To save time, these intermediate terms were computed just one time.
Backpropagation of ReLu involves creating and applying a mask. In earlier versions of the code, this mask was stored with half (FP16) precision. In this round, the DReLU mask is represented as a Boolean and not FP16 to reduce memory transactions.
During back propagation, data gradients and weight gradients were computed for each of the three convolution layers. NVIDIA found empirically that while the data gradient GPU kernels were launched with a sufficient number of CTAs to fully use the GPUs, the weight gradient kernels were launched with far fewer CTAs.
One optimization that was implemented was to launch the data gradient kernels first, and then launch all three weight gradient kernels on separate streams so that they ran concurrently. This reduced total computation time for weight gradients.
A new Apex module, which fuses convolution, bias, and ReLu, was implemented, as discussed in the RetinaNet section. This module was in MaskR-CNN as well to fuse forward propagation of some of the layers in RPN head block.
Evaluation
Evaluation, on average, takes almost as much time as training. Evaluation is done asynchronously on dedicated nodes, but the results are shared with the training nodes through a blocking broadcast.
The training nodes wait for a certain number of steps before they start waiting for the evaluation broadcast to minimize any evaluation result wait time. The learning rate curve has two inflection points in it, and it is extremely unlikely that the model will have converged before passing the last inflection point. That’s why you should wait for as long as possible to check for evaluation results, until training has passed the last learning rate curve inflection point.
Top-K
In earlier versions of PyTorch, the number of CTAs launched by the top-k kernel was proportional to the per-GPU batch size. This yielded poor performance when the batch size equaled 1, the batch size that is always used for NVIDIA max-scale runs.
This issue was addressed in previous rounds with a two-stage top-k method, which was implemented in Python, but this solution did not generalize well. Work on a more general solution was already underway.
In this round, NVIDIA worked with the PyTorch team to ensure that the new top-k implementation that yielded far better performance for a batch size of 1 made it into PyTorch. When this was complete, the prior two-stage top-k implementation was replaced with the new PyTorch module.
3D U-Net
3D U-Net has multiple large layers with an input channel count of 32. For wgrad kernels, using a kernel with the default 64x256x64 meant significant tile size quantization loss.
Thanks to the introduction of the new 32x256x32 wgrad kernels in cuDNN, this tile size quantization loss was saved. This resulted in a speedup of over 5% on a single node in MLPerf v2.0 over MLPerf v1.1.
RNN-T
The preprocessing step of Recurrent Neural Network Transducer (RNN-T) is relatively intensive. Thanks to DALI, most of the preprocessing overhead can be pipelined and hidden under the main training loop.
However, because the size of the input data might vary, there was a need for relocating the internal memory buffers after the initial iteration, increasing the length of the warm-up phase.
DALI has recently switched to a memory-pool based allocator, where the pool is managed using the cuMem API. This significantly reduces the overhead of allocating new buffers, yielding a much faster warm-up process in training.
Conclusion
Thanks to optimizations across the stack, the NVIDIA platform was yet again able to boost performance in MLPerf Training v2.0 using the proven NVIDIA A100 Tensor Core GPU and NVIDIA DGX A100 platforms.
NVIDIA continues to be the only platform to submit results in the MLPerf benchmarking suite, including MLPerf Training, MLPerf Inference, and MLPerf HPC. This showcases the performance and versatility of the entire platform, which is crucial as modern AI becomes pervasive across every computing domain.
In addition to providing the software used for NVIDIA MLPerf submissions in the MLPerf repository, dozens of additional models were also made and optimized for NVIDIA GPUs, available on the NGC hub.
The NVIDIA platform is also ubiquitous, providing customers with the choice of where to run models. NVIDIA A100 is available from all major server makers and cloud service providers, allowing you to deploy on-premises, in the cloud, in a hybrid environment, or at the edge.
Siemens, a leader in industrial automation and software, infrastructure, building technology and transportation, and NVIDIA, a pioneer in accelerated graphics and artificial intelligence (AI), today announced an expansion of their partnership to enable the industrial metaverse and increase use of AI-driven digital twin technology that will help bring industrial automation to a new level.
This post discusses infrastructure factors to consider, such as performance, hardware, and types of AI software for implementing a fraud prevention strategy.
By using AI and big data analytics, enterprises can efficiently prevent fraud attempts in real time.
This post discusses the infrastructure factors to consider, such as performance, hardware, and types of AI software for implementing a fraud prevention strategy.
Pre– and post-transaction fraud detection
Before discussing fraud detection, let’s be clear on the difference between prevention and detection. Fraud prevention describes the overall effort to manage and eliminate fraud. Fraud detection is simply the ability to identify fraudulent activity.
There are two approaches to fraud detection, both necessary for a comprehensive fraud prevention strategy.
Pre-transaction detection: Detecting and blocking attempted fraud transactions before transaction completion. When anomalous data or behavior is detected before a transaction, the transaction is blocked.
Post-transaction detection: A fraudulent transaction is identified after transaction completion based on data analysis or post-transaction inputs. This is followed by damage mitigation.
The ideal approach is to detect and block attempted fraud before its occurrence. When fraud is detected after a transaction, the only recourse is to assess the damage, notify relevant parties, and work to recover from the fraud damage.
Although fraud can never fully be eliminated, both pre– and post-transaction fraud efforts are important in developing a fraud risk management plan.
Best enterprise IT practices for developing an effective anti-fraud solution
If fraud prevention was as simple as instant breakfast cereal, you’d just add hot water and stir. A standard server and software is all that’s needed for effective fraud prevention. Correct? Not exactly.
Fraud prevention software is obviously essential, but choosing just any hardware and software combination does not ensure success. In spite of widespread fraud prevention “solutions” across enterprises, fraud continues to increase, causing financial damage in the process.
Enterprise IT must ensure that multiple infrastructure elements are in place:
AI-driven software: There is a trend toward AI-driven fraud solutions because traditional static intelligence is not as effective as the dynamic intelligence of AI. To prevent sophisticated fraud attempts, software must learn. Thus, AI must be at the core.
Accelerated performance: Real-time AI-driven fraud detection requires the highest performance possible. Delays can impact customer experience. With performance, more fraud factors can be evaluated in real time, resulting in more accurate fraud detection.
Availability and scale: A highly available scale-out architecture is required to support 24-7 data ingest and prevention.
Without these three components, you can expect less efficiency, which can result in greater fraud loss for businesses and customers.
AI-driven software
AI-driven software is already pervasive in the enterprise. Through AI-trained fraud prevention models, the accuracy of detecting real fraud can be evaluated and tuned based on model training iteration. After training, the prevention solution runs as an inferencing application to evaluate and block potentially fraudulent transactions. Data from the application is then fed back to the model for re-training and greater accuracy and efficiency. The continuously retrained model is then used to update the production application and so on.
As machine learning (ML) and deep learning (DL) are increasingly applied to growing datasets, Apache Spark has become popular for data preprocessing and feature engineering as raw data is prepared for training. It is also used as a data execution engine for analytics workloads. GPUs parallelize and accelerate data processing queries in the same way they accelerate deep-learning and AI workloads. RAPIDS is commonly used to accelerate Spark as well as ML/DL frameworks within a GPU-accelerated infrastructure.
In addition, AI frameworks like NVIDIA Morpheus can run in an unsupervised manner to flag anomalous activity and enhance fraud prevention efforts. AI-based fraud prevention is dynamic and can automatically adapt to threats.
Figure 1. Example of an NVIDIA Morpheus-driven framework
Accelerated performance
Yes, there is a need for speed, especially for pre-transaction fraud detection.
Pre-transaction detection
Without hardware acceleration, customers executing transactions can be inconvenienced with unacceptable delays as fraud prevention software analyzes each transaction. Slow processing impacts customer satisfaction and merchants realize less revenue. Standard CPUs were sufficient for legacy fraud prevention, but no longer.
Modern AI-based solutions powered by enterprise-class GPUs can be an order of magnitude more effective in speed and accuracy. High-performance GPU acceleration can enable the evaluation of more risk factors in a given time frame. Alternatively, the same number of risk factors can be evaluated in less time.
Post-transaction detection
Post-transaction fraud detection is not bound by real-time constraints. Still, GPU acceleration can provide benefits. Faster processing power allows for more data to be evaluated within a given period of time.
As with pre-transaction results, post-transaction results can be used to update pre– and post-processing models to improve future results (inferencing).
Other performance considerations
IT departments may mistakenly evaluate server performance requirements solely based on transaction speed. However, high performance is also required for initial model training and retraining based on incoming feedback data from the inference application.
Without GPU acceleration, initial training can take hours or days, and retraining can be unacceptably long. Time-to-results is not just about GPU clock rate. Some GPUs are not certified as enterprise-class and lack substantial GPU memory or a sufficient number of cores to deliver fast training results.
Yes, training of large fraud prevention models can be executed in the cloud with both performance and scale. Unfortunately, cloud processing cycles can be expensive after multiple training iterations.
Fortunately, model training can be cost-effectively executed locally in an iterative manner on enterprise GPU-accelerated workstations using a representative subset of data or with lower-resolution accuracy parameters. This makes the cost of preliminary model training essentially free after the capital expense of data science workstations or GPU-enabled servers.
After preliminary training, full-scale training in the cloud or enterprise server or server cluster can be executed on a large data set with greater efficiency.
Availability and scale
Fraudsters never sleep, so enterprise fraud prevention also cannot rest. Transactional apps run non-stop, so fraud prevention software must do the same. Enterprise IT infrastructure must deliver resiliency and availability for the prevention solution. As I’ve noted, performance is important, but when it’s not always available, it negates any performance benefits.
As I discussed earlier, fraud and associated damage are increasing each year. Prevention solutions must seamlessly scale out to accommodate this.
Availability and scalability requirements cannot be limited to servers. For example, a network may meet the specs for required throughput and latency, but the reality is that burst network traffic may cause sufficient network congestion such that fraud detection is either skipped, unacceptably delayed, or timed out. For this reason, network robustness and redundancy can’t be ignored when building an advanced anti-fraud solution.
Building AI-friendly infrastructure for fraud solutions
Will your AI-driven solution receive the performance, availability, and scale that is needed for success over time? Assuming the right AI-based fraud prevention software, IT must also ensure the right infrastructure. As I discussed earlier, this means infrastructure for accelerated performance, non-stop operation, and the flexibility to scale out seamlessly the infrastructure investment as fraud prevention data and workloads increase over time.
It is also challenging to deliver enterprise-class IT infrastructure that supports both fraud prevention and AI-driven enterprise solutions. The right mix of products addresses the performance, availability, and scale-out requirements for enterprise fraud prevention while supporting other AI frameworks and tools. This can range from mobile and desktop workstations for model development to servers and software for data center inference and training at scale.
The June NVIDIA Studio Driver is available for download today, optimizing the latest creative app updates, all with the stability and reliability that users count on. Creators with NVIDIA RTX GPUs will benefit from faster performance and new features within Blender version 3.2, BorisFX Sapphire release 2022.5 and Topaz Denoise AI 3.7.0.
I have been working on a project which uses open-cv, ssdmobnet, cocoapi and tensorflow to detect objects. I have given names of objects in label_map in hindi language and trained the model, but when it comes to detection it shows boxes instead of text.What is the possible solution.The detections are correct because i have also used display_name in label_map which is in english to check whether the detection are correct.
In an image segmentation task the background can be up to 99% of the whole image, and as a result the accuracy metrics really suck when training because the model goes to 99% quickly. Is there a way to train (or just output) without this included in the metric?
In collaboration with the United Nations, DLI is offering a new free online course focused on applying deep learning methods to generate accurate flood detection models.
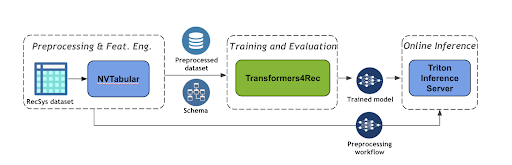
Transformers4Rec makes it easy to use SOTA NLP architectures for sequential and session-based recommendation by leveraging HuggingFace Transformers.
Recommender systems help you discover new products and make informed decisions. Yet, in many recommendation-dependent domains such as e-commerce, news, and streaming media services, users may be untrackable or have rapidly changing tastes depending on their needs at that moment.
Session-based recommendation systems, a sub-area of sequential recommendation, have recently gained popularity because they can recommend items relative to a user’s situation and preferences at any given point in time. Capturing short-term or contextual user preferences towards items is helpful in these domains.
Figure 1. Distinct interests for different user sessions
In this post, we introduce the session-based recommendation task, which is supported by Transformers4Rec, a library from the NVIDIA Merlin platform. We then showcase how easy it is to create a session-based recommendation model in a few lines of code using Transformers4Rec and finally conclude with demonstrating an end-to-end session-based recommendation pipeline with NVIDIA Merlin libraries.
Transformers4Rec library features
Released at ACM RecSys’21, the NVIDIA Merlin team designed and open-sourced the NVIDIA Merlin Transformers4Rec library for sequential and session-based recommendation tasks by leveraging state-of-the-art Transformers architectures. The library is extensible by researchers, simple for practitioners, and fast and robust in industrial deployments.
It leverages the SOTA NLP architectures from the Hugging Face (HF) Transformers library, making it possible to quickly experiment with many different Transformer architectures and pretraining approaches in the RecSys domain.
Transformers4Rec also helps data scientists, industry practitioners, and academicians build recommender systems that can leverage the short sequence of past user interactions within the same session and then dynamically suggest the next item that the user may be interested in.
Figure 2. Next-item prediction with Transformers4Rec
Here are some highlights of the Transformers4Rec library:
Flexibility and efficiency: Building blocks are modularized and compatible with vanilla PyTorch modules and TF Keras layers. You can create custom architectures, for example, with multiple towers, multiple heads/tasks, and losses. Transformers4Rec supports multiple input features and provides configurable building blocks that can easily be combined for custom architectures.
Integration with HuggingFace Transformers: Uses cutting-edge NLP research and makes state-of-the-art Transformer architectures available for the RecSys community for sequential and session-based recommendation tasks.
Support for multiple input features: Transformers4Rec enables the usage of HF Transformers with any type of sequential tabular data.
Seamless integration with NVTabular for preprocessing and feature engineering.
Production-ready: Exports trained models to serve on NVIDIA Triton Inference Server in a single pipeline with online features preprocessing and model inference.
Develop your own session-based recommendation model
With only a few lines of code, you can build a session-based model based on a SOTA Transformer architecture. The following example shows how the powerful XLNet Transformer architecture can be used for a next-item prediction task.
As you may notice, the code in building a session-based model with PyTorch and TensorFlow is very similar, with only a couple of differences. The following code example builds an XLNET-based recommendation model with PyTorch and TensorFlow using the Transformers4Rec API:
#from transformers4rec import torch as tr
from transformers4rec import tf as tr
from merlin_standard_lib import Schema
schema = Schema().from_proto_text("schema path>")
max_sequence_length, d_model = 20, 320
# Define input module to process tabular input-features and to prepare masked inputs
input_module = tr.TabularSequenceFeatures.from_schema(
schema,
max_sequence_length=max_sequence_length,
continuous_projection=64,
aggregation="concat",
d_output=d_model,
masking="clm",
)
# Define Next item prediction-task
prediction_task = tr.NextItemPredictionTask(hf_format=True,weight_tying=True)
# Define the config of the XLNet architecture
transformer_config = tr.XLNetConfig.build(
d_model=d_model, n_head=8, n_layer=2,total_seq_length=max_sequence_length
)
# Get the PyT model
model = transformer_config.to_torch_model(input_module, prediction_task)
# Get the TF model
#model = transformer_config.to_tf_model(input_module, prediction_task)
To demonstrate the utility of the library and applicability of Transformer architectures in next-click prediction for user sessions, where sequence lengths are much shorter than those commonly found in NLP, the NVIDIA Merlin team used Transformers4Rec to win two session-based recommendation competitions:
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate the terabyte-scale datasets used to train large-scale recommender systems. It provides a high-level abstraction to simplify code and accelerates computation on the GPU using the RAPIDS cuDF library.
NVTabular supports different feature engineering transformations required by deep learning (DL) models such as categorical encoding and numerical feature normalization. It also supports feature engineering and generating sequential features. For more information about the supported features, see here.
In the following code example, you can easily see how to can create an NVTabular preprocessing workflow to group interactions at the session level, sorting the interactions by time. At the end, you obtain a processed dataset where each row represents a user session and corresponding sequential features for that session.
import nvtabular as nvt
# Define Groupby Operator
features = ['session_id', 'item_id', 'timestamp', 'category']
groupby_features = features >> nvt.ops.Groupby(
groupby_cols=["session_id"],
sort_cols=["timestamp"],
aggs={
'item_id': ["list", "count"],
'category': ["list"],
'timestamp': ["first"],
},
name_sep="-")
# create dataset object
dataset = nvt.Dataset(interactions_df)
workflow = nvt.Workflow(groupby_features)
# Apply the preprocessing workflow on the dataset
sessions_gdf = workflow.transform(dataset).compute()
Use Triton Inference Server to simplify the deployment of AI models at scale in production. Triton Inference Server enables you to deploy and serve your model for inference. It supports a number of different machine learning frameworks, such as TensorFlow and PyTorch.
The last step of the machine learning (ML) pipeline is to deploy the ETL workflow and trained model to production for inference. In the production setting, you want to transform the input data as done during training (ETL). For example, you should use the same normalization statistics for continuous features and the same mapping to encode the categories into contiguous IDs before you use the ML/DL model for a prediction.
Fortunately, the NVIDIA Merlin framework has an integrated mechanism to deploy both the preprocessing workflow (modeled with NVTabular) with a PyTorch or TensorFlow model as an ensemble model to NVIDIA Triton Inference. The ensemble model guarantees that the same transformation is applied to the raw inputs.
The following code example showcases how easy it is to create ensemble configuration files using the NVIDIA Merlin Inference API functions, and then serve the model to TIS.
import tritonhttpclient
import nvtabular as nvt
workflow = nvt.Workflow.load("")
from nvtabular.inference.triton import export_tensorflow_ensemble as export_ensemble
#from nvtabular.inference.triton import export_pytorch_ensemble as export_ensemble
export_ensemble(
model,
workflow,
name="ensemble model name>",
model_path="model path>",
label_columns=["label column names>"],
sparse_max=dict or None>
)
tritonhttpclient.InferenceServerClient(url="ip:port>")
triton_client.load_model(model_name="ensemble model name>")
With a few lines of code, you can serve the NVTabular workflow, a trained PyTorch or TensorFlow model, and an ensemble model to NVIDIA Triton Inference Server, in order to execute end-to-end model deployment.Using the NVIDIA Merlin Inference API, you can send a raw dataset as a request (query) to the server and then obtain the prediction results from the server.
In essence, NVIDIA Merlin Inference API creates model pipelines using the NVIDIA Triton ensembling feature. An NVIDIA Triton ensemble represents a pipeline of one or more models and the connection of input and output tensors between those models.
Conclusion
In this post, we introduced you to NVIDIA Merlin Transformers4Rec, a library for sequential and session-based recommendation tasks that seamlessly integrates with NVIDIA NVTabular and NVIDIA Triton Inference Server to build end-to-end ML pipelines for such tasks.
For more information, see the following resources:

 Learn about the full-stack optimizations that enabled the NVIDIA platform to deliver even more performance in MLPerf Training v2.0.
Learn about the full-stack optimizations that enabled the NVIDIA platform to deliver even more performance in MLPerf Training v2.0. 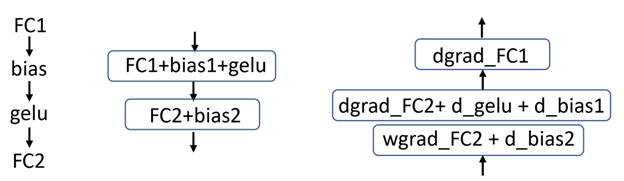

 This post discusses infrastructure factors to consider, such as performance, hardware, and types of AI software for implementing a fraud prevention strategy.
This post discusses infrastructure factors to consider, such as performance, hardware, and types of AI software for implementing a fraud prevention strategy.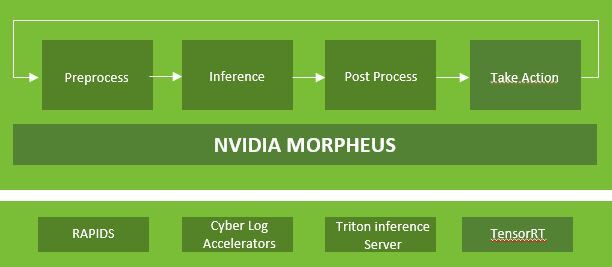
") In collaboration with the United Nations, DLI is offering a new free online course focused on applying deep learning methods to generate accurate flood detection models.
In collaboration with the United Nations, DLI is offering a new free online course focused on applying deep learning methods to generate accurate flood detection models.  Transformers4Rec makes it easy to use SOTA NLP architectures for sequential and session-based recommendation by leveraging HuggingFace Transformers.
Transformers4Rec makes it easy to use SOTA NLP architectures for sequential and session-based recommendation by leveraging HuggingFace Transformers.