Is there a way to calculate the inference speed using the TF2 object detection API?
submitted by /u/giakou4
[visit reddit] [comments]
 DataBloom
DataBloomIs there a way to calculate the inference speed using the TF2 object detection API?
submitted by /u/giakou4
[visit reddit] [comments]
The best site to show the difference between Tensorflow 1 codes and TensorFlow 2 codes
submitted by /u/numbers222ddd
[visit reddit] [comments]
NVIDIA GPUs will play a key role interpreting data streaming in from the James Webb Space Telescope, with NASA preparing to release next month the first full-color images from the $10 billion scientific instrument. The telescope’s iconic array of 18 interlocking hexagonal mirrors, which span a total of 21 feet 4 inches, will be able Read article >
The post Stunning Insights from James Webb Space Telescope Are Coming, Thanks to GPU-Powered Deep Learning appeared first on NVIDIA Blog.
submitted by /u/linus569
[visit reddit] [comments]
 The newly announced ARIA Zero Trust Gateway uses NVIDIA BlueField DPUs to provide a sophisticated cybersecurity solution.
The newly announced ARIA Zero Trust Gateway uses NVIDIA BlueField DPUs to provide a sophisticated cybersecurity solution.
Today’s cybersecurity landscape is changing in waves with threat and attack methods putting the business world on high alert. Modern attacks continue to gain sophistication, staying one step ahead of traditional cyber defense measures, by continuously altering attack techniques. With the increasing use of AI, ML, 5G, and IoT, network speeds readily run at 100G rates or more. Current methods of detection for dangerous threats and attacks are quickly becoming outdated and ineffective.
When operating at modern network speeds, it is no longer possible for security teams to monitor an entire network in real time. Organizations have tried to augment their Intrusion Prevention Systems (IPS) by relying on employees to perform the deep analysis of suspicious activity. This requires highly trained and paid security operations center personnel and comes with significant risks when teams are unable to keep pace with the deluge of data.
The litany of security issues has forced organizations to seek a next-generation solution that provides the ability to analyze all traffic within their 100G networks. To accomplish this requires a next generation IPS that is automated, more effective, and efficient that can stop attacks in real time at 100G and beyond.
ARIA Cybersecurity has developed a solution to solve these problems called the ARIA Zero Trust (AZT) Gateway. The gateway uses hardware acceleration from the NVIDIA BlueField-2 Data Processing Unit (DPU) for line-rate analysis. The solution is deployed as a compact, in-line, standalone network device to stop attacks with no impact to production traffic crossing the wire.
To accomplish this, the gateway operates by analyzing each packet in real time. Creating analytics for threat analysis enforces not only existing standalone protection policies, but also new dynamically generated policies, to ensure a more effective security posture.
To detect attacks, the packet analytics go to the central brain of the solution. The brain is ARIA’s Advanced Detection & Response product that uses ML and AI-driven threat models to analyze data for over 70 different types of attacks using the MITRE ATT&CK framework.
This is accomplished in a totally automated approach, removing the need for manual human involvement. In addition, copies of specific traffic conversations can be sent to an Intrusion Detection System for deeper analysis.
In both cases, the results are relayed back to the AZT Gateway as dynamically generated rules to eliminate the identified attack conversations in real time. Attacks can be identified, logged as new rules, and stopped in just seconds, automatically. Performing this process in real time is a major breakthrough.
Previously, you may have only been alerted to a problem and left to figure out the solution on your own. However, with the AZT Gateway, you can now take automated action on alerts and deploy new security rules to prevent unwanted activities on your network.
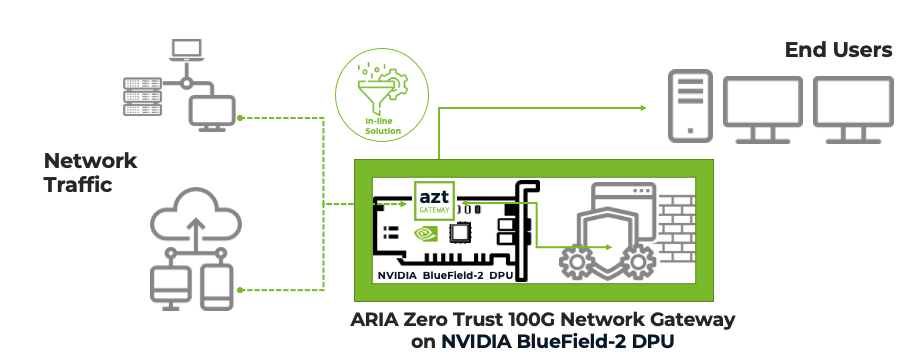
The BlueField-2 DPU is available in a compact PCIe OCP Card form factor. It provides the ability to monitor two 100G links at a time, without dropping any traffic or consuming critical CPU resources.
BlueField also provides hardware acceleration to handle packet analysis at demanding networking speeds in excess of 100G. To classify each packet at a conversation level, the AZT system software leverages the highly efficient BlueField Arm cores to apply preset and dynamically generated security rulesets.
The compact footprint and low-power draw make BlueField ideal for deployment in network provider and Cloud data center environments. Using BlueField, the AZT Gateway can also look into encrypted data stream payloads for deeper analysis.
This solution has proven to lower the cost per protected packet by up to 10X, decrease power compared to alternatives, and reduce the rack footprint by 10X.
For upcoming enhancements, the NVIDIA Morpheus application framework will provide ARIA with evolving cybersecurity analysis using advanced ML and AI algorithms to find and stop sophisticated attacks in real time.
Watch the ARIA Zero Trust Security Gateway webinar. >>
Learn how to accelerate your network with the BlueField DPU. >>
 On June 21, learn how OneCup AI leveraged the NVIDIA TAO toolkit and DeepStream SDK to create automated vision AI that helps ranchers track and monitor livestock.
On June 21, learn how OneCup AI leveraged the NVIDIA TAO toolkit and DeepStream SDK to create automated vision AI that helps ranchers track and monitor livestock.
Multimodal video captioning systems utilize both the video frames and speech to generate natural language descriptions (captions) of videos. Such systems are stepping stones towards the longstanding goal of building multimodal conversational systems that effortlessly communicate with users while perceiving environments through multimodal input streams.
Unlike video understanding tasks (e.g., video classification and retrieval) where the key challenge lies in processing and understanding multimodal input videos, the task of multimodal video captioning includes the additional challenge of generating grounded captions. The most widely adopted approach for this task is to train an encoder-decoder network jointly using manually annotated data. However, due to a lack of large-scale, manually annotated data, the task of annotating grounded captions for videos is labor intensive and, in many cases, impractical. Previous research such as VideoBERT and CoMVT pre-train their models on unlabelled videos by leveraging automatic speech recognition (ASR). However, such models often cannot generate natural language sentences because they lack a decoder, and thus only the video encoder is transferred to the downstream tasks.
In “End-to-End Generative Pre-training for Multimodal Video Captioning”, published at CVPR 2022, we introduce a novel pre-training framework for multimodal video captioning. This framework, which we call multimodal video generative pre-training or MV-GPT, jointly trains a multimodal video encoder and a sentence decoder from unlabelled videos by leveraging a future utterance as the target text and formulating a novel bi-directional generation task. We demonstrate that MV-GPT effectively transfers to multimodal video captioning, achieving state-of-the-art results on various benchmarks. Additionally, the multimodal video encoder is competitive for multiple video understanding tasks, such as VideoQA, text-video retrieval, and action recognition.
Future Utterance as an Additional Text Signal
Typically, each training video clip for multimodal video captioning is associated with two different texts: (1) a speech transcript that is aligned with the clip as a part of the multimodal input stream, and (2) a target caption, which is often manually annotated. The encoder learns to fuse information from the transcript with visual contents, and the target caption is used to train the decoder for generation. However, in the case of unlabelled videos, each video clip comes only with a transcript from ASR, without a manually annotated target caption. Moreover, we cannot use the same text (the ASR transcript) for the encoder input and decoder target, since the generation of the target would then be trivial.
MV-GPT circumvents this challenge by leveraging a future utterance as an additional text signal and enabling joint pre-training of the encoder and decoder. However, training a model to generate future utterances that are often not grounded in the input content is not ideal. So we apply a novel bi-directional generation loss to reinforce the connection to the input.
Bi-directional Generation Loss
The issue of non-grounded text generation is mitigated by formulating a bi-directional generation loss that includes forward and backward generation. Forward generation produces future utterances given visual frames and their corresponding transcripts and allows the model to learn to fuse the visual content with its corresponding transcript. Backward generation takes the visual frames and future utterances to train the model to generate a transcript that contains more grounded text of the video clip. Bi-directional generation loss in MV-GPT allows the encoder and the decoder to be trained to handle visually grounded texts.
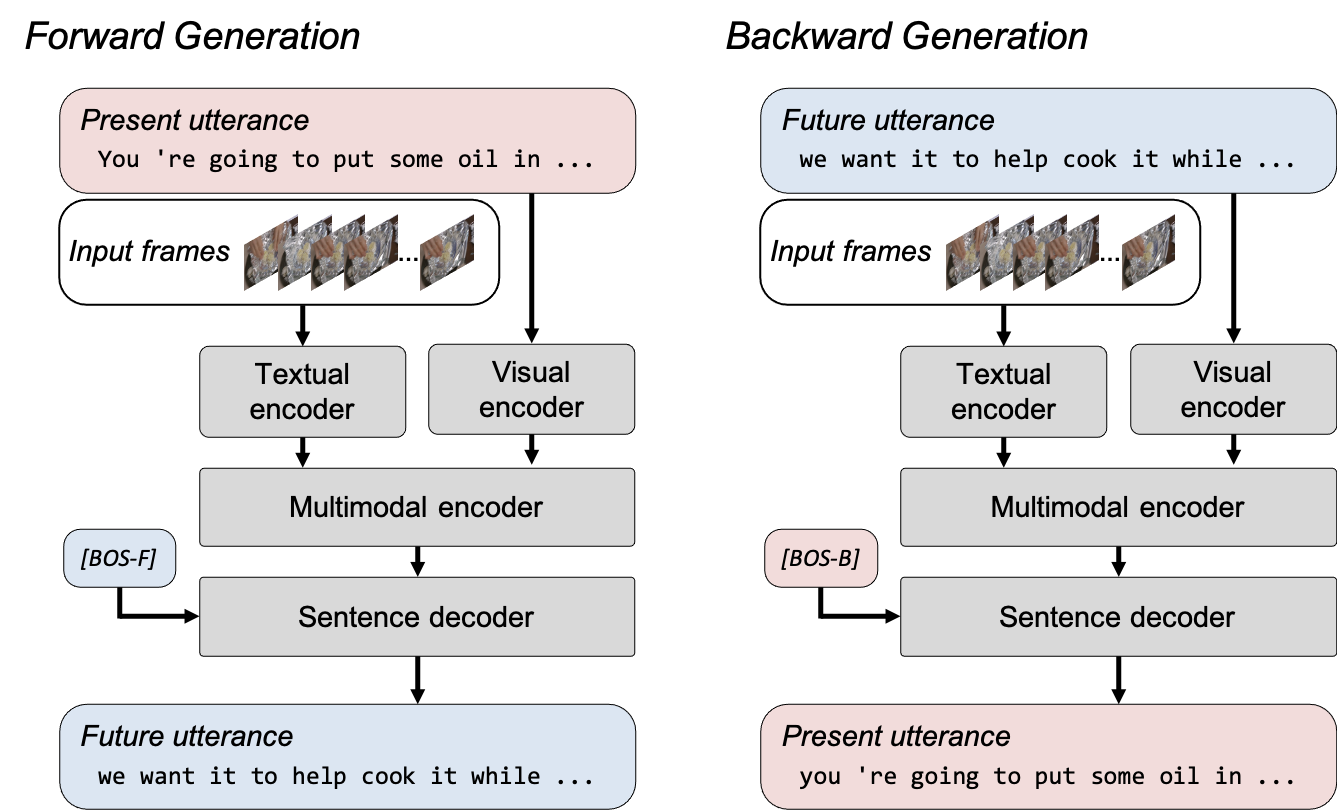 |
| Bi-directional generation in MV-GPT. A model is trained with two generation losses. In forward generation, the model generates a future utterance (blue boxes) given the frames and the present utterance (red boxes), whereas the present is generated from the future utterance in backward generation. Two special beginning-of-sentence tokens ([BOS-F] and [BOS-B]) initiate forward and backward generation for the decoder. |
Results on Multimodal Video Captioning
We compare MV-GPT to existing pre-training losses using the same model architecture, on YouCook2 with standard evaluation metrics (Bleu-4, Cider, Meteor and Rouge-L). While all pre-training techniques improve captioning performances, it is critical to pre-train the decoder jointly to improve model performance. We demonstrate that MV-GPT outperforms the previous state-of-the-art joint pre-training method by over 3.5% with relative gains across all four metrics.
| Pre-training Loss | Pre-trained Parts | Bleu-4 | Cider | Meteor | Rouge-L |
| No Pre-training | N/A | 13.25 | 1.03 | 17.56 | 35.48 |
| CoMVT | Encoder | 14.46 | 1.24 | 18.46 | 37.17 |
| UniVL | Encoder + Decoder | 19.95 | 1.98 | 25.27 | 46.81 |
| MV-GPT (ours) | Encoder + Decoder | 21.26 | 2.14 | 26.36 | 48.58 |
| MV-GPT performance across four metrics (Bleu-4, Cider, Meteor and Rouge-L) of different pre-training losses on YouCook2. “Pre-trained parts” indicates which parts of the model are pre-trained — only the encoder or both the encoder and decoder. We reimplement the loss functions of existing methods but use our model and training strategies for a fair comparison. | ||||
We transfer a model pre-trained by MV-GPT to four different captioning benchmarks: YouCook2, MSR-VTT, ViTT and ActivityNet-Captions. Our model achieves state-of-the-art performance on all four benchmarks by significant margins. For instance on the Meteor metric, MV-GPT shows over 12% relative improvements in all four benchmarks.
| YouCook2 | MSR-VTT | ViTT | ActivityNet-Captions | |
| Best Baseline | 22.35 | 29.90 | 11.00 | 10.90 |
| MV-GPT (ours) | 27.09 | 38.66 | 26.75 | 12.31 |
| Meteor metric scores of the best baseline methods and MV-GPT on four benchmarks. | ||||
Results on Non-generative Video Understanding Tasks
Although MV-GPT is designed to train a generative model for multimodal video captioning, we also find that our pre-training technique learns a powerful multimodal video encoder that can be applied to multiple video understanding tasks, including VideoQA, text-video retrieval and action classification. When compared to the best comparable baseline models, the model transferred from MV-GPT shows superior performance in five video understanding benchmarks on their primary metrics — i.e., top-1 accuracy for VideoQA and action classification benchmarks, and recall at 1 for the retrieval benchmark.
| Task | Benchmark | Best Comparable Baseline | MV-GPT |
| VideoQA | MSRVTT-QA | 41.5 | 41.7 |
| ActivityNet-QA | 38.9 | 39.1 | |
| Text-Video Retrieval | MSR-VTT | 33.7 | 37.3 |
| Action Recognition | Kinetics-400 | 78.9 | 80.4 |
| Kinetics-600 | 80.6 | 82.4 |
| Comparisons of MV-GPT to best comparable baseline models on five video understanding benchmarks. For each dataset we report the widely used primary metric, i.e., MSRVTT-QA and ActivityNet-QA: Top-1 answer accuracy; MSR-VTT: Recall at 1; and Kinetics: Top-1 classification accuracy. | ||||
Summary
We introduce MV-GPT, a new generative pre-training framework for multimodal video captioning. Our bi-directional generative objective jointly pre-trains a multimodal encoder and a caption decoder by using utterances sampled at different times in unlabelled videos. Our pre-trained model achieves state-of-the-art results on multiple video captioning benchmarks and other video understanding tasks, namely VideoQA, video retrieval and action classification.
Acknowledgements
This research was conducted by Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab and Cordelia Schmid.

For all its sophistication, the Internet age has brought on a digital plague of security breaches. The steady drumbeat of data and identity thefts spawned a new movement and a modern mantra that’s even been the subject of a U.S. presidential mandate — zero trust. So, What Is Zero Trust? Zero trust is a cybersecurity Read article >
The post What Is Zero Trust? appeared first on NVIDIA Blog.
Dionysios Satikidis was playing FIFA 19 when he realized the simulated soccer game’s realism offered a glimpse into the future for training robots. An expert in AI and autonomous systems at Festo, a German industrial control and automation company, he believed the worlds of gaming and robotics would intersect. “I’ve always been passionate about technology Read article >
The post Festo Develops With Isaac Sim to Drive Its Industrial Automation appeared first on NVIDIA Blog.
This week In the NVIDIA Studio takes off with the debut of Top Goose, a short animation created with Omniverse Machinima and inspired by one of the greatest fictional pilots to ever grace the big screen. The project was powered by PCs using the same breed of GPU that has produced every Best Visual Effects nominee at the Academy Awards for 14 years: multiple systems with NVIDIA RTX A6000 GPUs and an NVIDIA Studio laptop — the Razer Blade 15 with a GeForce RTX 3070 Laptop GPU.
The post Feel the Need … for Speed as ‘Top Goose’ Debuts In the NVIDIA Studio appeared first on NVIDIA Blog.