I’m currently developing and image classificator and for that i started watching the tutorial on tensorflow.org .
I’m trying to see how to train a CNN, but as i use model.fit i receive an OOM. I’ve searched on internet but no ones of the answer that i’ve found helped me.
For give you a bit of context i’m using a mobile gtx 1050 and i suspect that the problem is that it hasn’t enough memory, so i ask you some advice on how to succesfully train my models.
Posted by Harsh Mehta, Software Engineer, Google Research
Matrix factorization is one of the oldest, yet still widely used, techniques for learning how to recommend items such as songs or movies from user ratings. In its basic form, it approximates a large, sparse (i.e., mostly empty) matrix of user-item interactions with a product of two smaller, denser matrices representing learned item and user features. These dense matrices, in turn, can be used to recommend items to a user with which they haven’t interacted before.
Despite its algorithmic simplicity, matrix factorization can still achieve competitiveperformance in recommender benchmarks. Alternating least squares (ALS), and especially its implicit variation, is a fundamental algorithm to learn the parameters of matrix factorization. ALS is known for its high efficiency because it scales linearly in the number of rows, columns and non-zeros. Hence, this algorithm is very well suited for large-scale challenges. But, for very large real-world matrix factorization datasets, a single machine implementation would not suffice, and so, it would require a large distributed system. Most of the distributed implementations of matrix factorization that employ ALS leverage off-the-shelf CPU devices, and rightfully so, due to the inherently sparse nature of the problem (the input matrix is mostly empty).
On the other hand, recent success of deep learning, which has exhibited growing computational capacity, has spurred a new wave of research and progress on hardware accelerators such as Tensor Processing Units (TPUs). TPUs afford domain specific hardware speedups, especially for use cases like deep learning, which involves a large number of dense matrix multiplications. In particular, they allow significant speedups for traditional data-parallel workloads, such as training models with Stochastic Gradient Descent (SGD) in SPMD (single program multiple data) fashion. The SPMD approach has gained popularity in computations like training neural networks with gradient descent algorithms, and can be used for both data-parallel and model-parallel computations, where we distribute parameters of the model across available devices. Nevertheless, while TPUs have been enormously attractive for methods based on SGD, it is not immediately clear if a high performance implementation of ALS, which requires a large number of distributed sparse matrix multiplies, can be developed for a large-scale cluster of TPU devices.
In “ALX: Large Scale Matrix Factorization on TPUs”, we explore a distributed ALS design that makes efficient use of the TPU architecture and can scale well to matrix factorization problems of the order of billions of rows and columns by scaling the number of available TPU cores. The approach we propose leverages a combination of model and data parallelism, where each TPU core both stores a portion of the embedding table and trains over a unique slice of data, grouped in mini-batches. In order to spur future research on large-scale matrix factorization methods and to illustrate the scalability properties of our own implementation, we also built and released a real world web link prediction dataset called WebGraph.
The figure shows the flow of data and computation through the ALX framework on TPU devices. Similar to SGD-based training procedures, each TPU core performs identical computation for its own batch of data in SPMD fashion, which allows for synchronous computation in parallel on multiple TPU cores. Each TPU starts with gathering all the relevant item embeddings in the Sharded Gather stage. These materialized embeddings are used to solve for user embeddings which are scattered to the relevant shard of the embedding table in the Sharded Scatter stage.
Dense Batching for Improved Efficiency We designed ALX specifically for TPUs, exploiting unique properties of TPU architecture while overcoming a few interesting limitations. For instance, each TPU core has limited memory and restricts all tensors to have a static shape, but each example in a mini-batch can have a wildly varying number of items (i.e., inputs can be long and sparse). To resolve this, we break exceedingly long examples into multiple smaller examples of the same shape, a process called dense batching. More details about dense batching can be found in our paper.
Illustrating example of how sparse batches are densified to increase efficiency on TPUs.
Uniform Sharding of Embedding Tables With the batching problem solved, we next want to factorize a sparse matrix into two dense embedding matrices (e.g., user and item embeddings) such that the resulting dot product of embeddings approximate the original sparse matrix — this helps us infer predictions for all the positions from the original matrix, including those that were empty, which can be used to recommend items with which users haven’t interacted. Both the resulting embedding tables (W and H in the figure below) can potentially be too large to fit in a single TPU core, thus requiring a distributed training setup for most large-scale use cases.
Most previous attempts of distributed matrix factorization use a parameter server architecture where the model parameters are stored on highly available servers, and the training data is processed in parallel by workers that are solely responsible for the learning task. In our case, since each TPU core has identical compute and memory, it’s wasteful to only use either memory for storing model parameters or compute for training. Thus, we designed our system such that each core is used to do both.
Illustrative example of factorizing a sparse matrix Y into two dense embedding matrices W and H.
In ALX, we uniformly divide both embedding tables, thus fully exploiting both the size of distributed memory available and the dedicated low-latency interconnects between TPUs. This is highly efficient for very large embedding tables and results in good performance for distributed gather and scatter operations.
Uniform sharding of both embedding tables (W and H) across TPU cores (in blue).
WebGraph Since potential applications may involve very large data sets, scalability is potentially an important opportunity for advancement in matrix factorization. To that end, we also release a large real-world web link prediction dataset called WebGraph. This dataset can be easily modeled as a matrix factorization problem where rows and columns are source and destination links, respectively, and the task is to predict destination links from each source link. We use WebGraph to illustrate the scaling properties of ALX.
The WebGraph dataset was generated from a single crawl performed by CommonCrawl in 2021 where we strip everything and keep only the link->outlinks data. Since the performance of a factorization method depends on the properties of the underlying graph, we created six versions of WebGraph, each varying in the sparsity pattern and locale, to study how well ALS performs on each.
To study locale-specific graphs, we filter based on two top level domains: ‘de’ and ‘in’, each producing a graph with an order of magnitude fewer nodes.
These graphs can still have arbitrary sparsity patterns and dangling links. Thus we further filter the nodes in each graph to have a minimum of either 10 or 50 inlinks and outlinks.
For easy access, we have made these available as a Tensorflow Dataset package. For reference, the biggest version, WebGraph-sparse, has more than 365M nodes and 30B edges. We create and publish both training and testing splits for evaluation purposes.
Results We carefully tune the system and quality parameters of ALX. Based on our observations related to precision and choice of linear solvers. We observed that by carefully selecting the precision for storage of the embedding tables (bfloat16) and for the input to the linear solvers (float32), we were able to halve the memory required for the embeddings while still avoiding problems arising from lower precision values during the solve stage. For our linear solvers, we selected conjugate gradients, which we found to be the fastest across the board on TPUs. We use embeddings of dimension 128 and train the model for 16 epochs. In our experience, hyperparameter tuning over both norm penalty (λ) and unobserved weight (α) has been indispensable for good recall metrics as shown in the table below.
Results obtained by running ALX on all versions of WebGraph dataset. Recall values of 1.0 denote perfect recall.
Scaling Analysis Since the input data are processed in parallel across TPU cores, increasing the number of cores decreases training time, ideally in a linear fashion. But at the same time, a larger number of cores requires more network communication (due to the sharded embedding tables). Thanks to high-speed interconnects, this overhead can be negligible for a small number of cores, but as the number of cores increases, the overhead eventually slows down the ideal linear scaling.
In order to confirm our hypothesis, we analyze scaling properties of the four biggest WebGraph variants in terms of training time as we increase the number of available TPU cores. As shown below, even empirically, we do observe the predicted linear decrease in training time up to a sweet spot, after which the network overhead slows the decline.
Scaling analysis of running time as the number of TPU cores are increased. Each figure plots the time taken to train for one epoch in seconds.
Conclusion For easy access and reproducibility, the ALX code is open-sourced and can be easily run on Google Cloud. In fact, we illustrate that a sparse matrix like WebGraph-dense of size 135M x 135M (with 22B edges) can be factorized in a colab connected to 8 TPU cores in less than a day. We have designed the ALX framework with scalability in mind. With 256 TPU cores, one epoch of the largest WebGraph variant, WebGraph-sparse (365M x 365M sparse matrix) takes around 20 minutes to finish (5.5 hours for the whole training run). The final model has around 100B parameters. We hope that the ALX and WebGraph will be useful to both researchers and practitioners working in these fields. The code for ALX can be found here on github!
Acknowledgements The core team includes Steffen Rendle, Walid Krichene and Li Zhang. We thank many Google colleagues for helping at various stages of this project. In particular, we are grateful to the JAX team for numerous discussions, especially James Bradbury and Skye Wanderman-Milne; Blake Hechtman for help with XLA and Rasmus Larsen for useful discussions about performance of linear solvers on TPUs. Finally, we’re also grateful to Nicolas Mayoraz and John Anderson for providing useful feedback.
We present a new generation of neural operators, named U-FNO, that empowers a novel technology for solving multiphase flow problems with superior accuracy, speed, and data efficiency.
Climate change mitigation is about reducing greenhouse gas (GHG) emissions. The worldwide goal is to reach net zero, which means balancing the amount of GHG emissions produced and the amount removed from the atmosphere.
On the one hand, this implies reducing emissions by using low-carbon technologies and energy efficiency. On the other hand, it implies deploying negative emission technologies such as carbon storage, which is the subject of this post.
Carbon capture and storage (CCS) refers to a group of technologies that contribute to directly reducing emissions at their source in key power sectors such as coal and gas power plants and industrial plants. For emissions that cannot be reduced directly either because they are technically difficult or prohibitively expensive to eliminate, CCS underpins an important net-negative technological approach for removing carbon from the atmosphere.
If not being used on site, CO2 can be compressed and transported by pipeline, ship, rail, or truck. It can be used in a range of applications or injected into deep geological formations (including depleted oil and gas reservoirs or saline formations) that trap the CO2 for permanent storage. This unique dual ability of CCS makes it an essential solution among the energy transition technologies that mitigate climate change.
In addition to the role CCS plays in the energy transition, it is a solution for challenging emissions in heavy industries and addresses deep emissions reductions from hard-to-abate sectors like steel, fertilizer, and cement production. It can also support a cost-effective pathway for low-carbon blue hydrogen production.
In numbers, CCS facilities currently in operation can capture and permanently store around 40 Mt of CO2 every year. According to the International Energy Agency (IEA), to achieve a climate outcome consistent with the Paris Agreement, 1150 MtCO2 must be stored before 2030. So, there is a factor of 30 to achieve in storage capacity by 2030 to reduce the emissions of power and industrial sectors.
Global macro-trends such as the rise of environment social governance (ESG) criteria are stimulating the implementation of the broadest portfolio of technologies, including CCS to achieve net-zero emissions at the lowest possible risk and cost. Investment incentives are therefore building unprecedented momentum behind CCS with plans for more than 100 new facilities already announced in 2021.
CO2 injection problem
Carbon must be stored somewhere. It is most often stored underground in a process called geological sequestration. A geological formation is only selected as a storage site under certain conditions to make sure there’s no significant risk of leakage and no significant environmental or health risk.
This involves injecting carbon dioxide into underground rock formations. It is stored as a supercritical fluid, meaning that it has properties between those of a gas and a liquid.
When CO2 is injected at depth into a reservoir, it remains in this supercritical condition as long as it stays in excess of 31.1° C and at a pressure in excess of 73.86 bar. This is true whether the reservoir is a saline formation or depleted oil and gas fields.
CO2 must be sealed under a capillary barrier so that carbon remains stored for hundreds of years or even indefinitely in a safe way. Otherwise, if CO2 leaks out in large quantities, it could potentially contaminate a nearby aquifer. If it leaks to ground surface, it can cause safety hazards to nearby humans or animals.
The overall performance of such storage can be predicted numerically by solving a multiphase flow problem. However, this requires solving highly nonlinear PDEs due to multiscale heterogeneities and complex thermodynamics.
The numerical simulation methodology to achieve this usually consists in several steps:
Collecting data and information about the subsurface geology and properties.
Building a geological model of the storage formation and its surroundings.
Building a dynamic model of the reservoir, which is used to simulate CO2 injection and CO2 evolution inside the reservoir. These dynamic simulations are used to evaluate and optimize key performance indicators related to reservoir conditions.
Traditional simulators can accurately simulate this complex problem but are expensive at sufficiently refined grid resolution. Machine learning models trained with numerical simulation data can provide a faster alternative to traditional simulators.
In this post, we highlight the results using the newly developed U-FNO machine learning model and show its superiority for CO2-water multiphase flow problems required for understanding and scaling CCS applications.
Simulation setup
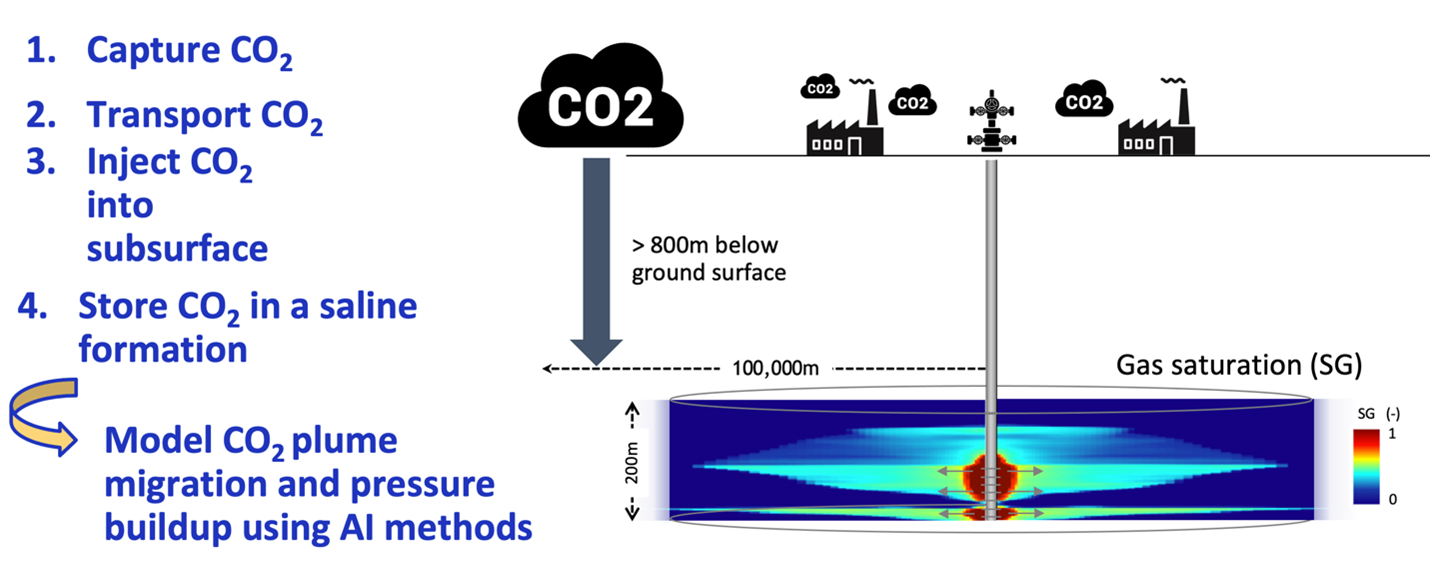
We consider modeling gas saturation and pressure over 30 years in deep saline formation at a constant rate ranging from 0.2 to 2 Mt/year. The x-axis and y-axis are the reservoir thickness and reservoir radius in meters, respectively.
The setup is a realistic reservoir located at least 800 m below ground surface (Figure 2). The setup enables reservoir simulation at various realistic depths, temperature, formation thickness, injection pattern, rock properties, and formation geology.
The numerical simulator Schlumberger ECLIPSE (e300) is used to develop the multiphase flow dataset for CO2 geological storage. Super-critical CO2 can be injected through a vertical injection, well with various perforation interval designs into a radially symmetrical system x (r, z).
Figure 2. Steps in typical carbon dioxide removal cycles, leading to the modeling stage
A novel Fourier neural operator
In a recent paper published in Advances in Water Resources, four types of machine learning model architectures are studied:
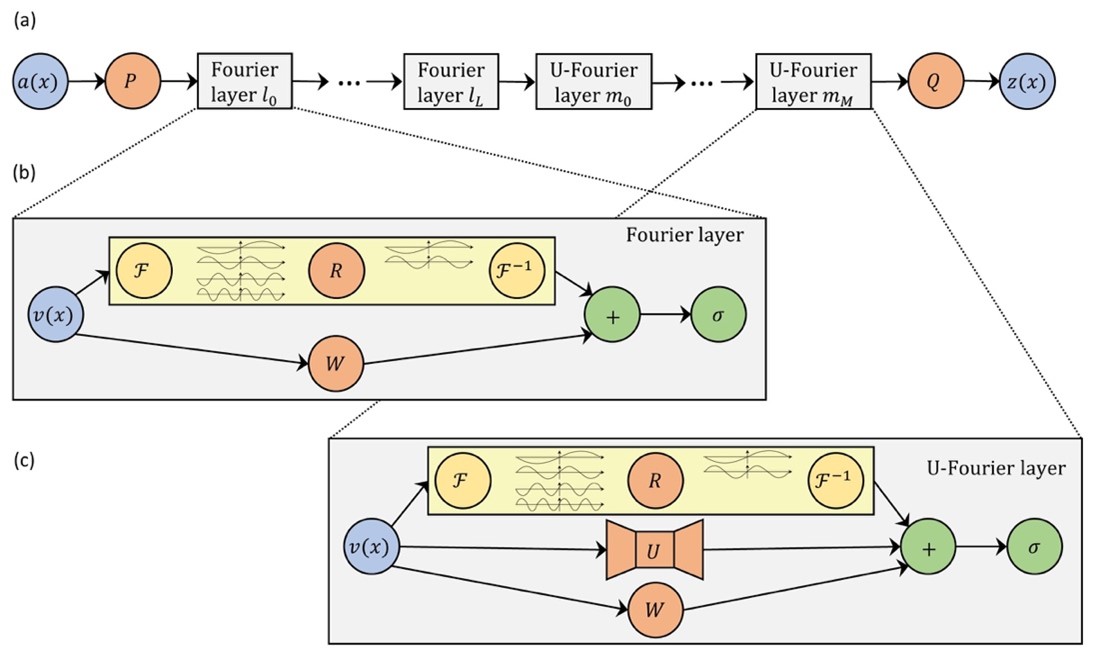
The goal of a neural operator is to learn an infinite-dimensional-space mapping from a finite collection of input-output observations. In contrast to the original Fourier layer in FNO, the U-FNO architecture proposed here appends a U-Net path in each U-Fourier layer. The U-Net processes local convolution to enrich the representation power of the U-FNO in higher frequencies information.
The newly proposed U-FNO model architecture uses both Fourier and U-Fourier layers (Figure 3).
Figure 3. U-FNO model architecture
In the Fourier and U-Fourier layers (a):
is the input.
and are fully connected neural networks.
is the output.
Inside the Fourier layer (b):
denotes the Fourier transform.
is the parameterization in Fourier space.
$latex F−1$ is the inverse Fourier transform.
is a linear bias term.
is the activation function.
Inside the U-FNO layer (c):
denotes a two-step U-Net.
The other notations have identical meaning as in the Fourier layer.
The number of Fourier and U-Fourier layers, and , are hyperparameters, optimized for the specific problem.
Comparisons with the original FNO architecture and a state-of-the-art CNN benchmark shows that the newly proposed U-FNO architecture provides the best performance for both gas saturation and pressure buildup predictions.
The results of CO2 storage predictions using NVIDIA GPUs show the following:
U-FNO predictions are accurate, with only 1.6% plume error on gas saturation and 0.68% relative error on pressure buildup.
U-FNO has superior performance on both training and testing sets compared to CNNs and the original FNO.
Gas saturation and pressure buildup prediction using U-FNO is 46% and 24% more accurate than state-of-the-art CNNs.
U-FNO requires only 33% of the training data to achieve the equivalent accuracy as CNNs.
Running a 30-year case on GPUs using U-FNO takes 0.01 s compared to 600 s using traditional finite-difference methods (FDM).
U-FNO is 6 x 104x faster than the “ground truth” conventional FDM solver; FNO is 105 x faster.
The training and testing times are both evaluated on an NVIDIA A100-SXM GPU and compared to Schlumberger ECLIPSE simulations on an Intel Xeon Processor E5-2670 CPU.
For the CO2-water multiphase flow application described here, the goal was to optimize for the accuracy of gas saturation and pressure fields, for which the U-FNO provides the highest performance. The trained U-FNO model can therefore serve as an alternative to traditional numerical simulators in probabilistic assessment, inversion, and CCS site selection.
Web application
The trained U-FNO models are hosted on an openly accessible web application, CCSNet: a deep learning modeling suite for CO2 storage. The web application provides real-time predictions and lowers the technical barriers for governments, companies, and researchers to obtain reliable simulation results for CO2 storage projects.
Scaling FNO to 3D problem sizes using NVIDIA Tensor Core GPUs
Due to the high dimensionality of input data in CO2 storage problems, machine learning application has been limited to two-dimensional or small to medium-scale three-dimensional sized problems.
Performing domain decomposition methods with minimum communication amount for parallelization of multidimensional fast Fourier transforms (FFT)s has been extensively looked at in literature, for many applications.
It is well-known that you can efficiently compute a multidimensional FFT with a sequence of lower-dimensional FFTs. The main idea is to use an iterative repartition pattern. The full mathematical derivation of the required components of distributed FNOs and its implementation is provided in the previously mentioned paper.
The following figure shows this concept, showing the distributed FFT using pencil decompositions acting on an input initially distributed over a 2×2 partition. Repartition operators are used to ensure that each worker has the full data it needs for calculating the sequential FFT in each dimension.
Figure 4. Distributed FFT using pencil decompositions acting on an input initially distributed over a 2×2 partition
The authors demonstrated that this implementation offers a different set of features when solving the 3D time-varying two-phase flow equations. In this case, the model-parallel FNO can predict time-varying PDE solutions of over 3.2 billion variables using up to 768 GPUs (128 nodes) on Summit.
Looking ahead towards next steps, we can train larger 3D models following the Grady approach based on domain-decomposition, and drastically increase our capability on data size. With this technique, it is possible for us to scale up FNO type models to solve 3D basin/reservoir CO2 storage problems.
Summary
Simulations are required to optimize the CO2 injection location and verify that CO2 does not leak from the storage site. We have shown that U-FNO, an enhanced deep Fourier neural operator, is 2x more accurate, 3x more data efficient than state-of-the-art CNN, and four orders of magnitude faster than a numerical simulator.
Using NVIDIA GPUs, the trained U-FNO models generate gas saturation and pressure buildup predictions 6 × 104x faster than a traditional numerical solver. Distributed operator learning and the ability to scale FNOs with domain decomposition to large problem sizes opens up new possibilities to scale our studies to realistically sized data.
To avoid the worst outcomes from climate change, Working Group III published the 2022 mitigation pathways in its contribution to the sixth assessment report (AR6) of the Intergovernmental Panel on Climate Change (IPCC). Experts highlighted the need for and potential of carbon capture and storage (CCS) to limit global warming to 1.5° C or 2° C.
Admittedly, there are current limitations to this set of technologies, especially related to economic and sociocultural barriers. But its deployment to counterbalance hard-to-abate residual emissions is considered unavoidable if net zero CO2 or greenhouse gas emissions are to be achieved.
We believe that building powerful AI tools for climate action and resilience can curb emissions at scale. In this work, we deployed novel artificial intelligence techniques to accelerate the CO2 flow in porous media, which play an important role for CCS applications and the path forward towards mitigating climate change.
Posted by Tal Remez, Software Engineer, Google Research and Micheal Hassid, Software Engineer Intern, Google Research
Recent years have seen a tremendous increase in the creation and serving of video content to users across the world in a variety of languages and over numerous platforms. The process of creating high quality content can include several stages from video capturing and captioning to video and audio editing. In some cases dialogue is re-recorded (referred to as dialog replacement, post-sync or dubbing) in a studio in order to achieve high quality and replace original audio that might have been recorded in noisy conditions. However, the dialog replacement process can be difficult and tedious because the newly recorded audio needs to be well synced with the video, requiring several edits to match the exact timing of mouth movements.
In “More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech”, we present a proof-of-concept visually-driven text-to-speech model, called VDTTS, that automates the dialog replacement process. Given a text and the original video frames of the speaker, VDTTS is trained to generate the corresponding speech. As opposed to standard visual speech recognition models, which focus on the mouth region, we detect and crop full faces using MediaPipe to avoid potentially excluding information pertinent to the speaker’s delivery. This gives the VDTTS model enough information to generate speech that matches the video while also recovering aspects of prosody, such as timing and emotion. Despite not being explicitly trained to generate speech that is synchronized to the input video, the learned model still does so.
Given a text and video frames of a speaker, VDTTS generates speech with prosody that matches the video signal.
VDTTS Model The VDTTS model resembles Tacotron at its core and has four main components: (1) text and video encoders that process the inputs; (2) a multi-source attention mechanism that connects encoders to a decoder; (3) a spectrogram decoder that incorporates the speaker embedding (similarly to VoiceFilter), and produces mel-spectrograms (which are a form of compressed representation in the frequency domain); and (4) a frozen, pretrained neural vocoder that produces waveforms from the mel-spectrograms.
The overall architecture of VDTTS. Text and video encoders process the inputs and then a multisource attention mechanism connects these to a decoder that produces mel-spectrograms. A vocoder then produces waveforms from the mel-spectrograms to generate speech as an output.
We train VDTTS using video and text pairs from LSVSR in which the text corresponds to the exact words spoken by a person in a video. Throughout our testing, we have determined that VDTTS cannot generate arbitrary text, thus making it less prevalent for misuse (e.g., the generation of fake content).
Quality To showcase the unique strength of VDTTS in this post, we have selected two inference examples from the VoxCeleb2 test dataset and compare the performance of VDTTS to a standard text-to-speech (TTS) model. In both examples, the video frames provide prosody and word timing clues, visual information that is not available to the TTS model.
In the first example, the speaker talks at a particular pace that can be seen as periodic gaps in the ground-truth mel-spectrogram (shown below). VDTTS preserves this characteristic and generates audio that is much closer to the ground-truth than the audio generated by standard TTS without access to the video.
Similarly, in the second example, the speaker takes long pauses between some of the words. These pauses are captured by VDTTS and are reflected in the video below, whereas the TTS does not capture this aspect of the speaker’s rhythm.
We also plot fundamental frequency (F0) charts to compare the pitch generated by each model to the ground-truth pitch. In both examples, the F0 curve of VDTTS fits the ground-truth much better than the TTS curve, both in the alignment of speech and silence, and also in how the pitch changes over time. See more original videos and VDTTS generated videos.
We present two examples, (a) and (b), from the VoxCeleb2 test set. From top to bottom: input face images, ground-truth (GT) mel-spectrogram, mel-spectrogram output of VDTTS, mel-spectrogram output of a standard TTS model, and two plots showing the normalized F0 (normalized by mean non-zero pitch, i.e., mean is only over voiced periods) of VDTTS and TTS compared to the ground-truth signal.
Video Samples
Original
VDTTS
VDTTS video-only
TTS
Original displays the original video clip. VDTTS, displays the audio predicted using both the video frames and the text as input. VDTTS video-only displays audio predictions using video frames only. TTS displays audio predictions using text only. Top transcript: “of space for people to make their own judgments and to come to their own”. Bottom transcript: “absolutely love dancing I have no dance experience whatsoever but as that”.
Model Performance We’ve measured the VDTTS model’s performance using the VoxCeleb2 dataset and compared it to TTS and the TTS with length hint (a TTS that receives the scene length) models. We demonstrate that VDTTS outperforms both models by large margins in most of the aspects we measured: higher sync-to-video quality (measured by SyncNet Distance) and better speech quality as measured by mel cepstral distance (MCD), and lower Gross Pitch Error (GPE), which measures the percentage of frames where pitch differed by more than 20% on frames for which voice was present on both the predicted and reference audio.
SyncNet distance comparison between VDTTS, TTS and the TTS with Length hint (a lower metric is better).
Mel cepstral distance comparison between VDTTS, TTS and the TTS with Length hint (a lower metric is better).
Gross Pitch Error comparison between VDTTS, TTS and the TTS with Length hint (a lower metric is better).
Discussion and Future Work One thing to note is that, intriguingly, VDTTS can produce video synchronized speech without any explicit losses or constraints to promote this, suggesting complexities such as synchronization losses or explicit modeling are unnecessary.
While this is a proof-of-concept demonstration, we believe that in the future, VDTTS can be upgraded to be used in scenarios where the input text differs from the original video signal. This kind of a model would be a valuable tool for tasks such as translation dubbing.
Acknowledgements We would like to thank the co-authors of this research: Michelle Tadmor Ramanovich, Ye Jia, Brendan Shillingford, and Miaosen Wang. We are also grateful to the valued contributions, discussions, and feedback from Nadav Bar, Jay Tenenbaum, Zach Gleicher, Paul McCartney, Marco Tagliasacchi, and Yoni Tzafir.
The recent DOCA Hackathon in Europe revealed streamlined innovation in video processing, storage solutions, and switching protocols using the BlueField DPU and DOCA SDK.
The third in a series of global NVIDIA DOCA Hackathons took place on March 21, during NVIDIA 2022 GTC. Competing in the event were 10 teams from a variety of universities, enterprises, and technology partners from across Europe and the Middle East. As part of GTC, NVIDIA CEO, Jensen Huang, gave a powerful keynote highlighting efforts in AI to supercharge industries including DPU and switching.
The recent Hackathon in Europe focused on BlueField DPU innovations that leverage the DOCA software framework to streamline the development process. Participants continue to find new ways to utilize the DPU for offloading, accelerating, and isolating a broad range of services. With DOCA, NVIDIA brings together APIs, drivers, libraries, sample code, documentation, services, and prepackaged containers for developers to speed up application development and deployment.
“The NVIDIA Hackathon series enables participants to take a giant leap forward in their DPU application development. With direct access to DOCA training, mentors, preconfigured setups, documentation, and access to a working environment. These Hackathons help to accelerate application development that would have otherwise taken months for many organizations and play a significant role in establishing a strong DOCA developer community,” said Dror Goldenberg, SVP of Software Architecture at NVIDIA. “We continue to be very impressed with the creativity and ingenuity of all of our hackathon contestants and this competition was no exception!”
First Place
Team Thales from Theresis Utilization of DPU for Storage Security
Figure 1. Members of the first-place team celebrate their win.
The Team Thales solution successfully used the BlueField DPU to create cyberdefense for files transmitted over the network. They used a combination of networking and storage security rules that delivered an overall performance improvement. The goal was to build upon the DPI acceleration to enable Yara rules, which are used for inspection of files downloaded from the network to identify malware and potential threats. To implement this, Team Thales used a Yara Parser to transform public Yara rules into DPI rules in a Suricata community-based format supported by the DOCA DPI lib. This solution leveraged DOCA DPI functionality to scan the files on the fly as the packets flow through the device.
Second Place
Team RARE/FreeRTR from GÉANT Router for Academia Research and Education Hardware accelerated MPLS
FreeRTR Router is a Swiss army knife meant to be used as a primary router but can also be used as a specific appliance. The team evaluated accelerated DPDK and DOCA FLOW and enabled the routing functionality with multiple routing protocols on the DPU leveraging the large and programmable flow tables. As part of their planned innovation, the team also evaluated added services by linking DOCA libraries to provide additional functionality including Firewall, RegEx scanning, MACsec encryption, and DPI engine at line rate. This allowed Team Rare to create one control plane to rule all dataplanes.
Third Place
Team DOCA Seville from the University of Seville Video processing at the edge
Team DOCA Seville used the BlueField DPU to filter out voided frames of CCTV streams, reducing the load on a CPU/GPU and improving physical security by providing detection of firearms. The intention is to prevent mass shootings by detecting the weapon. Removing images with no people significantly improves the overall system performance. Team DOCA Seville leveraged the DPU to offload the image processing and used DOCA gRPC infrastructure to stream filtered data for further analysis.
Congratulations to the winners and thanks to all of the teams that participated, making this round of NVIDIA DOCA Hackathon such a wonderful success!
NVIDIA is building a broad community of DOCA developers to create innovative applications and services on top of BlueField DPUs to secure and accelerate modern, efficient data centers. To learn more about joining the community, visit the DOCA developer web page or register to download DOCA today.
Up next is the NVIDIA DPU Hackathon in China. Check out our corporate calendar to stay informed of future events, and take part in our journey to reshape the data center of tomorrow.
I went around my area and took a bunch of pictures of litter. And it caused my model to go to shit
I can’t think why??
I took decent photos, converted to jpg, and label everything appropriately. The photos are larger in dimensions and memory wise so it caused training to be slower, which is understandable 🙃
GeForce NOW is about bringing new experiences to gamers. This GFN Thursday introduces game demos to GeForce NOW. Members can now try out some of the hit games streaming on the service before purchasing the full PC version — including some finalists from the 2021 Epic MegaJam. Plus, look for six games ready to stream Read article >
NVIDIA delivered leading results for MLPerf Inference 2.0, including 5x more performance for NVIDIA Jetson AGX Orin, an SoC platform built for edge devices and robotics.
Models like Megatron 530B are expanding the range of problems AI can address. However, as models continue to grow complexity, they pose a twofold challenge for AI compute platforms:
These models must be trained in a reasonable amount of time.
They must be able to do inference work in real time.
What’s needed is a versatile AI platform that can deliver the needed performance on a wide variety of models for both training and inference.
To evaluate that performance, MLPerf is the only industry-standard AI benchmark that tests data center and edge platforms across a half-dozen applications, measuring throughput, latency, and energy efficiency.
In MLPerf Inference 2.0, NVIDIA delivered leading results across all workloads and scenarios with both data center GPUs and the newest entrant, the NVIDIA Jetson AGX Orin SoC platform built for edge devices and robotics.
Beyond the hardware, it takes great software and optimization work to get the most out of these platforms. The results of MLPerf Inference 2.0 demonstrate how to get the kind of performance needed to tackle today’s increasingly large and complex AI models.
Here’s a look at the performance seen on MLPerf Inference 2.0, as well as some of those optimizations and how they got built.
Do the numbers
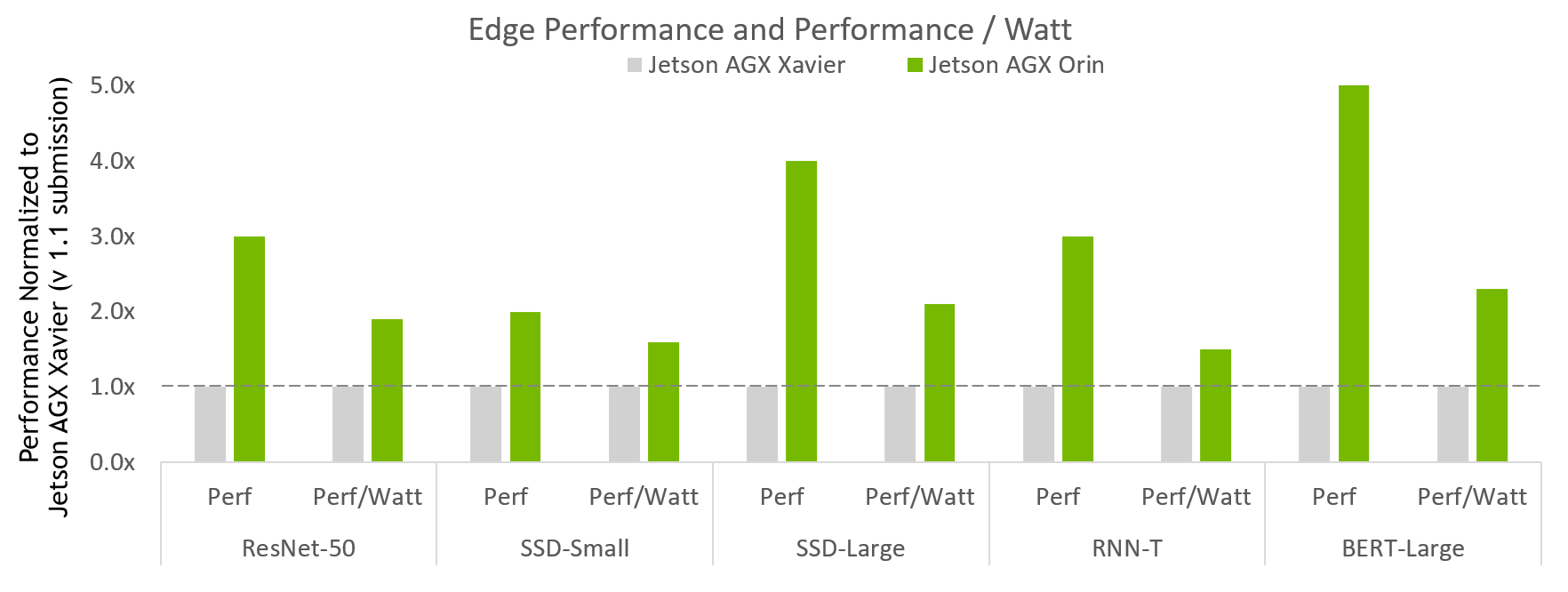
Figure 1 shows the latest entrant, NVIDIA Jetson AGX Orin.
Figure 1. NVIDIA Jetson AGX Orin performance improvement
MLPerf v2.0 Inference Edge Closed and Edge Closed Power; Performance/Watt from MLPerf results for respective submissions for Data Center and Edge, Offline Throughput, and Power. NVIDIA Xavier AGX Xavier: 1.1-110 and 1.1-111 | Jetson AGX Orin: 2.0-140 and 2.0-141. MLPerf name and logo are trademarks. Source: http://www.mlcommons.org/en.
Figure 1 shows that Jetson AGX Orin delivers up to 5x more performance compared to previous generation. It brings on average about 3.4x more performance across the full breadth of usages tested. In addition, Jetson AGX Orin delivers up to 2.3x more energy efficiency.
Jetson Orin AGX is an SoC that brings up to 275 TOPS of AI compute for multiple concurrent AI inference pipelines, plus high-speed interface support for multiple sensors. The NVIDIA Jetson AGX Orin Developer Kit enables you to create advanced robotics and edge AI applications for manufacturing, logistics, retail, service, agriculture, smart city, healthcare, and life sciences.
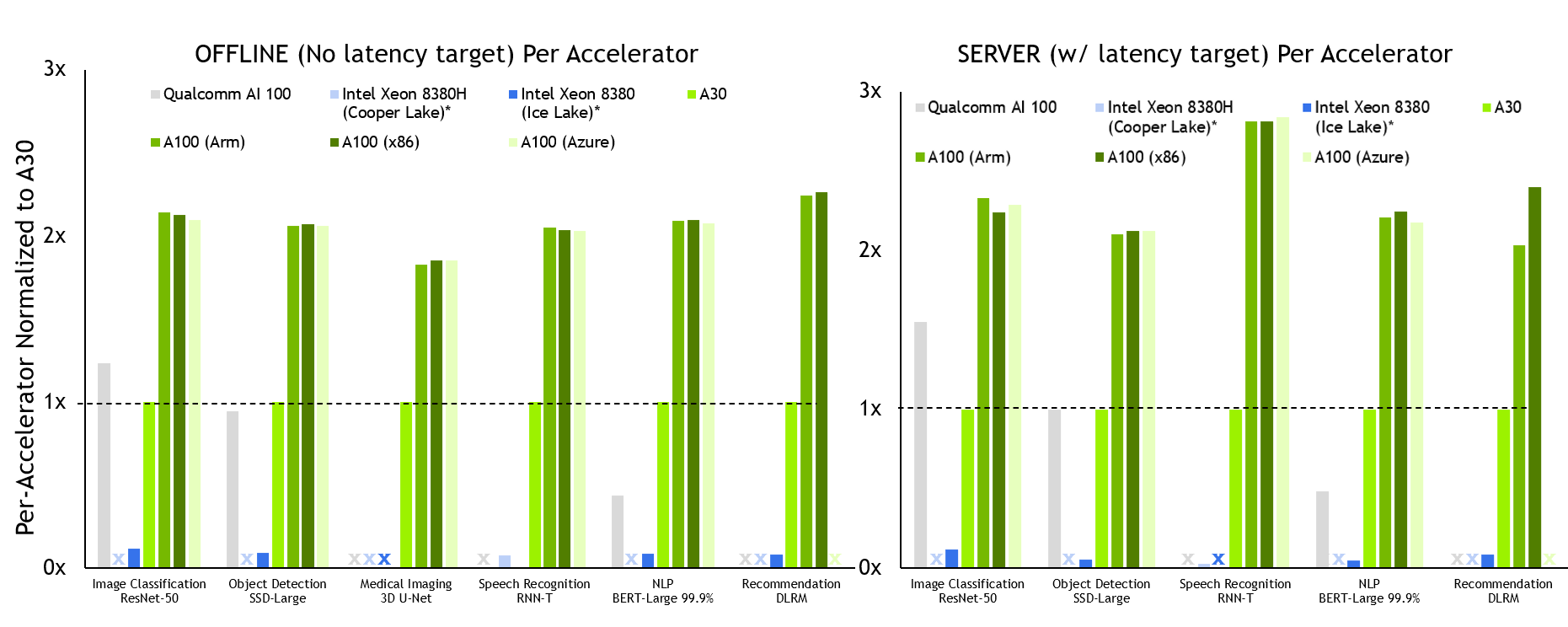
In the Data Center category, NVIDIA continues to deliver across-the-board AI inference performance leadership across all usages.
Figure 2. NVIDIA A100 per-accelerator performance
MLPerf v2.0 Inference Closed; Per-accelerator performance derived from the best MLPerf results for respective submissions using reported accelerator count in Data Center Offline and Server. Qualcomm AI 100: 2.0-130, Intel Xeon 8380 from MLPerf v.1.1 submission: 1.1-023 and 1.1-024, Intel Xeon 8380H 1.1-026, NVIDIA A30: 2.0-090, NVIDIA A100 (Arm): 2.0-077, NVIDIA A100 (x86): 2.0-094. MLPerf name and logo are trademarks. Source: http://www.mlcommons.org/en.
NVIDIA A100 delivers the best per-accelerator performance across all tests in both the Offline and Server scenarios.
We submitted the A100 in the following configurations:
A100 SXM paired with x86 CPUs (AMD Epyc 7742)
A100 PCIe paired with x86 CPUs (AMD Epyc 7742)
A100 SXM paired with an Arm CPU (NVIDIA Ampere Architecture Altra Q80-30)
Microsoft Azure also submitted using its A100 instance, which we also show in this data.
All configurations deliver about the same inference performance, which is a testament to the readiness of our Arm software stack, as well as the overall performance of A100 on-premises and in the cloud.
A100 also delivers up to 105x more performance than a CPU-only submission (RNN-T, Server scenario). A30 also delivered leadership-level performance on all but one workload. Like the A100, it ran every Data Center category test.
Key optimizations
Delivering great inference performance requires a full stack approach, where great hardware is combined with optimized and versatile software. NVIDIA TensorRT and NVIDIA Triton Inference Server both play pivotal roles in delivering great inference performance across the diverse set of workloads.
Jetson AGX Orin optimizations
The NVIDIA Orin new NVIDIA Ampere Architecture iGPU is supported by NVIDIA TensorRT 8.4. It is the most important component of the SoC for MLPerf performance. The extensive TensorRT library of optimized GPU kernels was extended to support the new architecture. The TensorRT builder picks up these kernels automatically.
Furthermore, the plug-ins used in MLPerf networks have all been ported to NVIDIA Orin and added to TensorRT 8.4, including the res2 plug-in (resnet50) and qkv to context plug-in (BERT). Unlike systems with discrete GPU accelerators, inputs are not copied from host memory to device memory, because the SoC DRAM is shared by the CPU and iGPU.
In addition to the iGPU, NVIDIA uses two deep learning accelerators (DLAs) for maximum system performance on CV networks (resnet50, ssd-mobilenet, ssd-resnet34) in the offline scenario.
NVIDIA Orin incorporates a new generation of DLA HW. To take advantage of these hardware improvements, the DLA compiler added the following NVIDIA Orin features, which are available automatically when you upgrade to a future release of TensorRT, without modifying any application source code.
SRAM chaining: Keeps intermediate tensors in local SRAM to avoid reads from/writes to DRAM, which reduces latency as well as platform DRAM usage. It also reduces interference with GPU inference.
Convolution + pooling fusion: INT8 convolution + bias + scale + ReLU can be fused with a subsequent pooling node.
Convolution + element-wise fusion: INT8 convolution + element-wise sum can be fused with a subsequent ReLU node.
The batch size of the two DLA accelerators were finely tuned to obtain the right balance of GPU+DLA aggregated performance. The tuning balanced the need to minimize scheduling conflicts for DLA engine’s GPU fallback kernels while reducing overall potential starvation out of the SoC’s shared DRAM bandwidth.
3D-UNet medical imaging
While most of the workloads were largely unchanged from MLPerf Inference v1.1, the 3D-UNet medical imaging workload was enhanced with the KITS19 data set. This new data set of kidney tumor images has much larger images of varying sizes and requires a lot more processing per sample.
The KiTS19 data set introduces new challenges in achieving performant, energy-efficient inference. More specifically:
Input tensors used in KiTS19 vary in shape from 128x192x320 to 320x448x448; the biggest input tensor is 8.17x larger than the smallest input tensor.
Tensors larger than 2 GB are needed during inference.
There is a sliding window on the specific region of interest (ROI) shape (128x128x128), with a large overlap factor (50%).
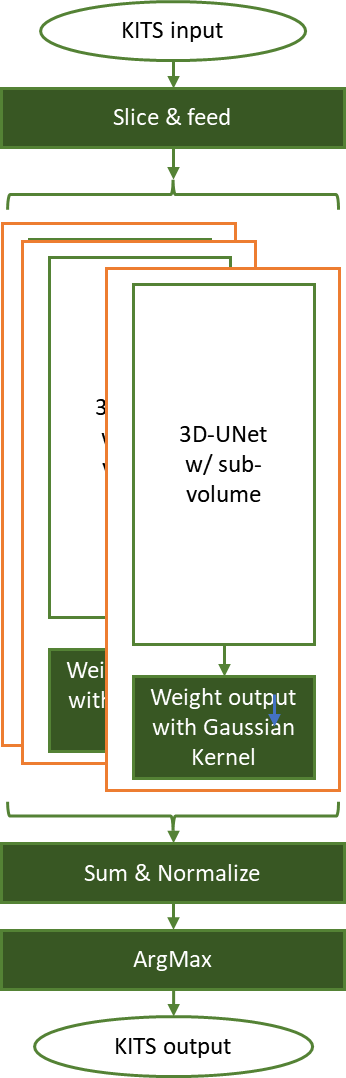
To address this, we developed a sliding window method to process these images:
Slice each input tensor into ROI shape, abiding by the overlap factor.
Use a loop to process all the sliding window slices for a given input tensor.
Weight and normalize the inference result of each sliding window.
Get the final segmentation output by the ArgMax of the aggregated results of sliding window inferences.
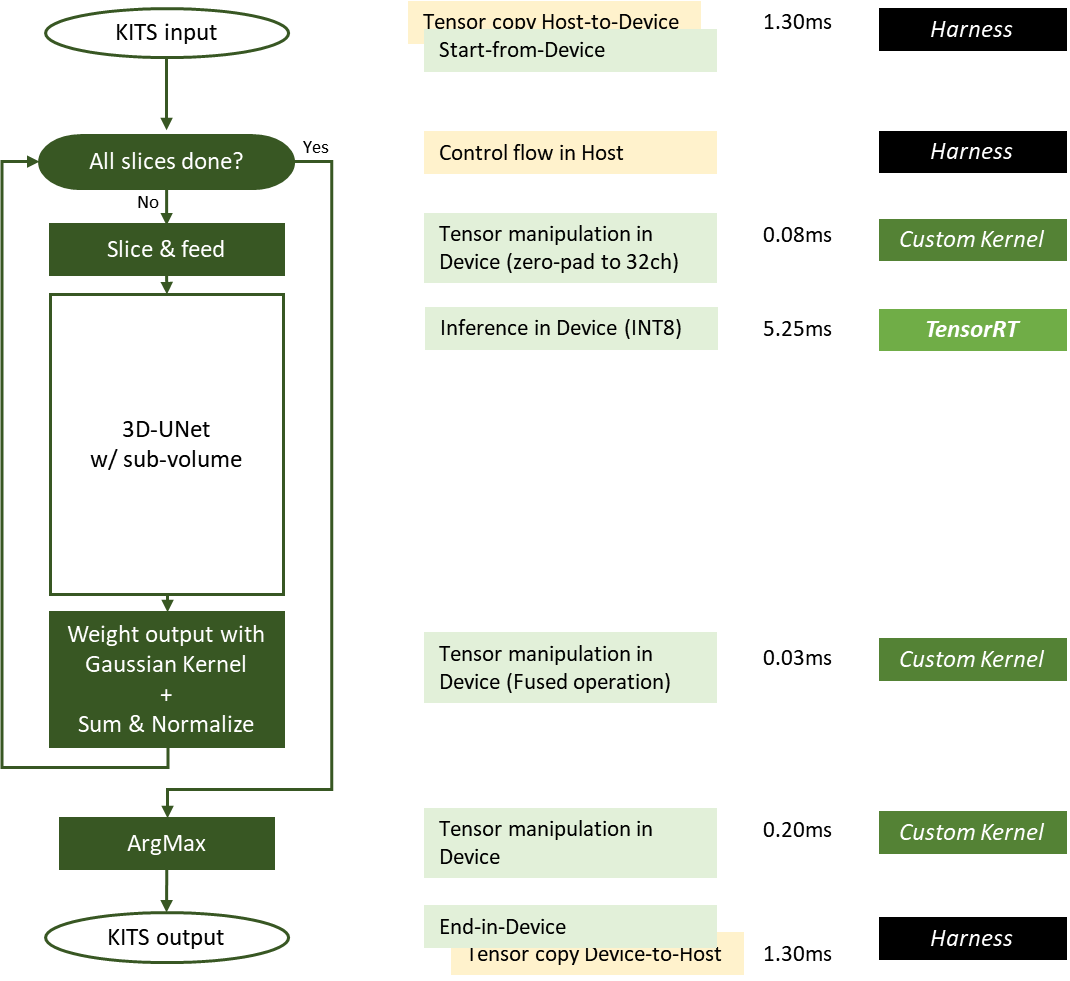
Figure 3. 3D-UNet performing KiTS19 kidney tumor segmentation inference task, using a sliding window approach
In Figure 3, each input tensor is sliced to the ROI-shape (128x128x128) with overlap-factor (50%) and fed into the pretrained network. Each sliding window output is then optimally weighted for capturing features with a Gaussian kernel of normalized sigma = 0.125.
The inference results are aggregated according to original input tensor shape and normalized, for those weighting factors. An ArgMax operation then carves the segmentation information, marking the background, normal kidney cells, and tumors.
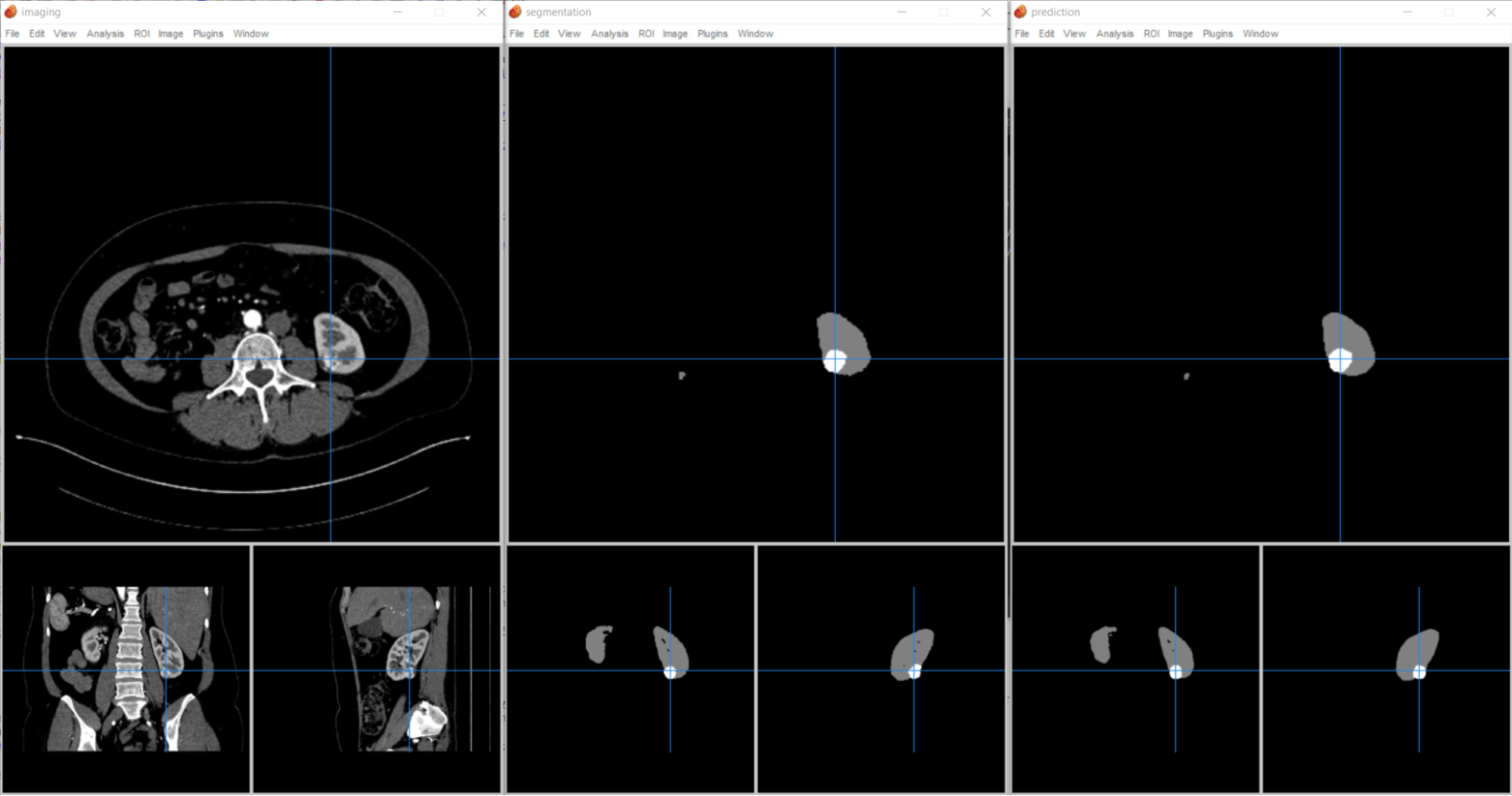
This implementation compares the segmentation against the ground truth and calculates a DICE score to determine benchmarking accuracy. You can also check the outcome visually (Figure 4).
Figure 4. (left) 3D CT image, which is an input to the inference task. (middle) Ground truth segmentation result showing normal kidney cells (gray) and tumors (highlighted white). (right) Inference result from 3D-UNet KiTS19.
We’ve supported INT8 precision in our data center GPUs for over 5 years, and this precision brings significant speedups on many models with near-zero loss in accuracy compared to FP16 and FP32 precision levels.
For 3D-UNet, we used INT8 by calibrating the images from the calibration set using the TensorRT IInt8MinMaxCalibrator. This implementation achieves 100% accuracy in the FP32 reference model, thus enabling both high and low accuracy modes of the benchmark.
Figure 5. NVIDIA 3D-UNet KiTS19 implementation used in MLPerf-Inference v2.0 submission
In Figure 5, green boxes are executed on the device (GPU) and yellow boxes are executed on the host (CPU). Some operations required for sliding window inference are optimized as fused operations.
Exploiting the GPUDirect RDMA and storage, host-to-device, or device-to-host data movement can be minimized or eliminated. The latency of each work is measured from the DGX-A100 system for one input sample whose size is close to the average input size. The latency for the slicing kernel and ArgMax kernel varies proportionally to the input image size.
Here are some of the specific optimizations implemented:
The Gaussian kernel patches used for weighting are now precalculated and stored on disk and are loaded into GPU memory before the timed portion of the benchmark starts.
Weighting and normalizing are optimized as a fused operation, using 27 precomputed patches required for the sliding window of 50% overlap on the 3D input tensor.
Custom CUDA kernels handling the slicing, weighting, and ArgMax are written so that all these operations are done in the GPU, eliminating the need of H2D/D2H data transfer.
Input tensor in INT8 LINEAR memory layout enables a minimal amount of data in H2D transfer as KiTS19 input set is a single channel.
TensorRT requires INT8 input in the NC/32DHW32 format. We use a custom CUDA kernel that performs slicing to zero-pad and reformat the INT8 LINEAR input tensor slice to INT8 NC/32DHW32 format in a contiguous memory region in GPU global memory.
Zero-padding and reformatting the tensor within the GPU is much faster than otherwise expensive H2D transfer of 32x more data. This optimization improves overall performance significantly and frees up the precious system resource.
The TensorRT engine is built for running inference on each of the sliding window slices. Because 3D-UNet is dense, we found that increasing batch size proportionally increases the runtime of the engine.
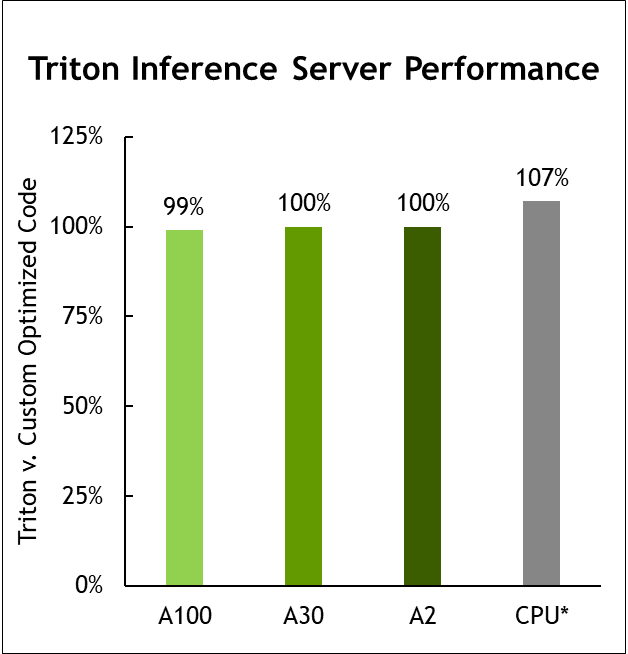
NVIDIA Triton optimizations
The NVIDIA submission continues to show the versatility of Triton Inference Server. This round, the Triton Inference Server also supports running NVIDIA Triton on AWS Inferentia. NVIDIA Triton uses the Python backend to run Inferentia-optimized PyTorch and TensorFlow models.
Using NVIDIA Triton and torch-neuron, the NVIDIA submissions achieved 85% to 100% of the native inference performance on Inferentia.
Figure 6. Triton Inference Server performance
MLPerf v1.1 Inference Closed; Per-accelerator performance derived from the best MLPerf results for respective submissions using reported accelerator count in Data Center Offline. Geomean of all submitted workloads shown. CPU comparison based on Intel submission data from MLPerf Inference 1.1 to compare configurations with same CPU, submissions 1.0-16, 1.0-17, 1.0-19. NVIDIA Triton on CPU: 2.0-100 and 2.0-101. A2: 2.0-060 and 2.0-061. A30: 2.0-091 and 2.0-092. A100: 2.0-094 and 2.0-096. MLPerf name and logo are trademarks. Source: http://www.mlcommons.org/en.
NVIDIA Triton now supports the AWS Inferentia inference processor and delivers nearly equal performance to running on the AWS Neuron SDK alone.
It takes a platform
NVIDIA inference leadership comes from building the most performant AI accelerators, both for training and inference. But great hardware is just the beginning.
NVIDIA TensorRT and Triton Inference Server software play pivotal roles in delivering our great inference performance across this diverse set of workloads. They are available at NGC, the NVIDIA hub, along with other GPU-optimized software for deep learning, machine learning, and HPC.
The NGC containerized software makes it much easier to get accelerated platforms up and running so you can focus on building real applications, and speeding time-to-value. NGC is freely available through the marketplace of your preferred cloud provider.
For more information, see Inference Technical Overview. This paper covers the trends in AI inference, challenges around deploying AI applications, and details of inference development tools and application frameworks.








 We present a new generation of neural operators, named U-FNO, that empowers a novel technology for solving multiphase flow problems with superior accuracy, speed, and data efficiency.
We present a new generation of neural operators, named U-FNO, that empowers a novel technology for solving multiphase flow problems with superior accuracy, speed, and data efficiency. 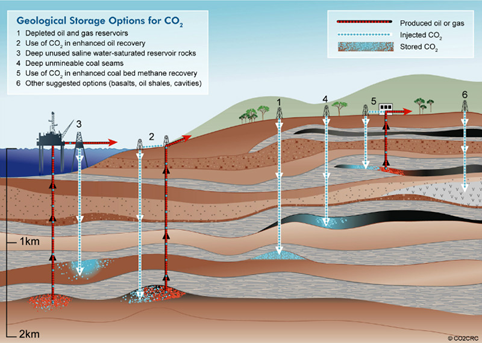
 is the input.
is the input. and
and  are fully connected neural networks.
are fully connected neural networks. is the output.
is the output. denotes the Fourier transform.
denotes the Fourier transform. is the parameterization in Fourier space.
is the parameterization in Fourier space. is a linear bias term.
is a linear bias term. is the activation function.
is the activation function. denotes a two-step U-Net.
denotes a two-step U-Net. and
and  , are hyperparameters, optimized for the specific problem.
, are hyperparameters, optimized for the specific problem.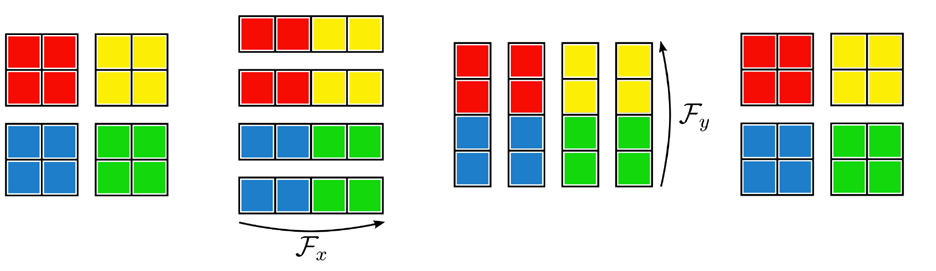






 The recent DOCA Hackathon in Europe revealed streamlined innovation in video processing, storage solutions, and switching protocols using the BlueField DPU and DOCA SDK.
The recent DOCA Hackathon in Europe revealed streamlined innovation in video processing, storage solutions, and switching protocols using the BlueField DPU and DOCA SDK.
 NVIDIA delivered leading results for MLPerf Inference 2.0, including 5x more performance for NVIDIA Jetson AGX Orin, an SoC platform built for edge devices and robotics.
NVIDIA delivered leading results for MLPerf Inference 2.0, including 5x more performance for NVIDIA Jetson AGX Orin, an SoC platform built for edge devices and robotics.