Sionna is a GPU-accelerated open-source library for link-level simulations.
Sionna is a GPU-accelerated open-source library for link-level simulations.
Even while 5G wireless networks are being installed and used worldwide, researchers in academia and industry have already started defining visions and critical technologies for 6G. Although nobody knows what 6G will be, a recurring vision is that 6G must enable the creation of digital twins and distributed machine learning (ML) applications at an unprecedented scale. 6G research requires new tools.

Some of the key technologies underpinning the 6G vision are communications at the high frequencies known as the Terahertz band. In this band, more spectrum is available by orders of magnitude. Technology examples include the following:
- Reconfigurable intelligent surfaces (RIS) to control how electromagnetic waves are reflected and achieve the best coverage.
- Integrated sensing and communications (ISAC) to turn 6G networks into sensors, which offers many exciting applications for autonomous vehicles, road safety, robotics, and logistics.
Machine learning is expected to play a defining role for the entire 6G protocol stack, which may revolutionize how we design and standardize communication systems.
Addressing the research challenges of these revolutionary technologies requires a new generation of tools to achieve the breakthroughs that will define communications in the 6G era. Here is why:
- Many 6G technologies require the simulation of a specific environment, such as a factory or cell site, with a spatially consistent correspondence between physical location, wireless channel impulse response, and visual input. This can currently only be achieved by either costly measurement campaigns, or by efficient simulation based on a combination of scene rendering and ray tracing.
- As machine learning and neural networks become increasingly important, researchers would benefit tremendously from a link-level simulator with native ML integration and automatic gradient computation.
- 6G simulations need unprecedented modeling accuracy and scale. The full potential of ML-enhanced algorithms will only be realized through physically-based simulations that account for reality in a level of detail that has been impossible in the past.
Introducing NVIDIA Sionna
To address these needs, NVIDIA developed Sionna, a GPU-accelerated open-source library for link-level simulations.
Sionna enables rapid prototyping of complex communication system architectures. It’s the world’s first framework that natively enables the use of neural networks in the physical layer and eliminates the need for separate toolchains for data generation, training, and performance evaluation.
Sionna implements a wide range of carefully tested, state-of-the-art algorithms that can be used for benchmarking and end-to-end performance evaluation. This lets you focus on your research, making it more impactful and reproducible while you spend less time implementing components outside your area of expertise.
Sionna is written in Python and based on TensorFlow and Keras. All components are implemented as Keras layers, which lets you build sophisticated system architectures by connecting the desired layers in the same way you would build a neural network.
Apart from a few exceptions, all components are differentiable so that gradients can be back-propagated through an entire system. This is the key enabler for system optimization and machine learning, especially the integration of neural networks.
NVIDIA GPU acceleration provides orders-of-magnitude faster simulations and scaling to large multi-GPU setups, enabling the interactive exploration of such systems. If no GPU is available, Sionna even runs on the CPU, though more slowly.
Sionna comes with rich documentation and a wide range of tutorials that make it easy to get started.
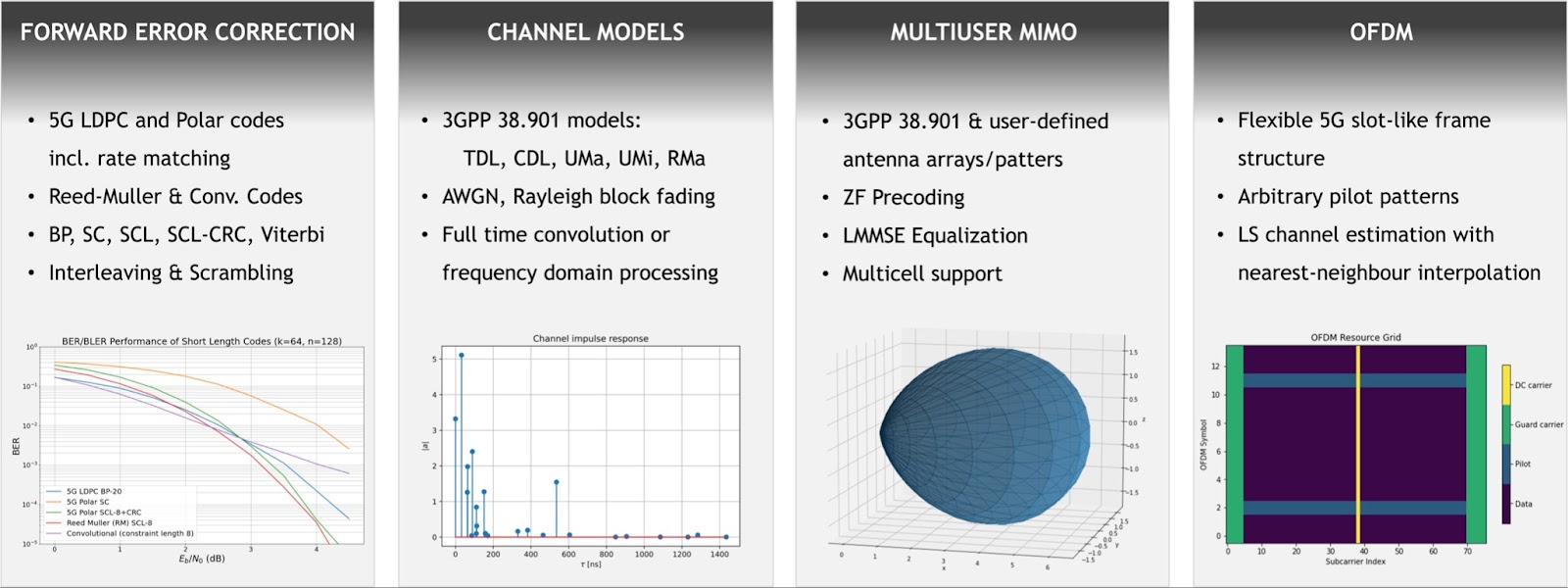
The first release of Sionna has the following major features:
- 5G LDPC, 5G polar, and convolutional codes, rate-matching, CRC, interleaver, scrambler
- Various decoders: BP variants, SC, SCL, SCL-CRC, Viterbi
- QAM and custom modulation schemes
- 3GPP 38.901 Channel Models (TDL, CDL, RMa, UMa, Umi), Rayleigh, AWGN
- OFDM
- MIMO channel estimation, equalization, and precoding
Sionna is released under the Apache 2.0 license, and we welcome contributions from external parties.
Hello, Sionna!
The following code example shows a Sionna “Hello, World!” example in which the transmission of a batch of LDPC codewords over an AWGN channel using 16QAM modulation is simulated. This example shows how Sionna layers are instantiated and applied to a previously defined tensor. The coding style follows the functional API of Keras. You can open this example directly in a Jupyter notebook on Google Collaboratory.
batch_size = 1024
n = 1000 # codeword length
k = 500 # information bits per codeword
m = 4 # bits per symbol
snr = 10 # signal-to-noise ratio
c = Constellation("qam",m,trainable=True)
b = BinarySource()([batch_size, k])
u = LDPC5GEncoder (k,n)(b)
x = Mapper (constellation=c)(u)
y = AWGN()([x,1/snr])
11r = Demapper("app", constellation=c)([y,1/snr])
b_hat = LDPC5GDecoder(LDPC5GEncoder (k, n))(11r)
One of the key advantages of Sionna is that components can be made trainable or replaced by neural networks. NVIDIA made Constellation trainable and replaced Demapper with a NeuralDemapper, which is just a neural network defined through Keras.
c = Constellation("qam",m,trainable=True)
b = BinarySource()([batch_size, k])
u = LDPC5GEncoder (k,n)(b)
x = Mapper (constellation=c)(u)
y = AWGN()([x,1/snr])
11r = NeuralDemapper()([y,1/snr])
b_hat = LDPC5GDecoder(LDPC5GEncoder (k, n))(11r)
What happens under the hood is that the tensor defining the constellation points has now become a trainable TensorFlow variable and can be tracked together with the weights of NeuralDemapper by the TensorFlow automatic differentiation feature. For these reasons, Sionna can be seen as a differentiable link-level simulator.
Looking ahead
Soon, Sionna will allow for integrated ray tracing to replace stochastic channel models, enabling many new fields of research. Ultra-fast ray tracing is a crucial technology for digital twins of communication systems. For example, this enables the co-design of a building’s architecture and the communication infrastructure to achieve unprecedented levels of throughput and reliability.
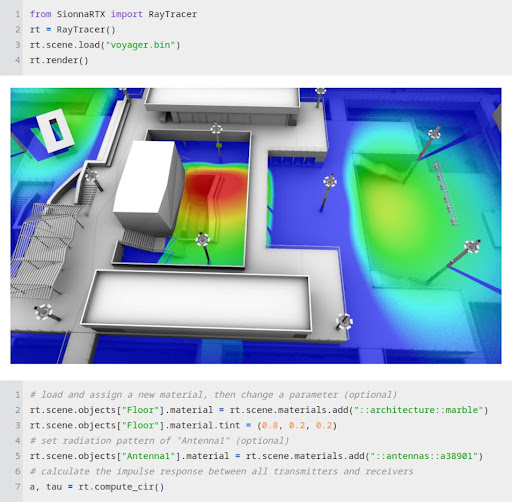
Sionna takes advantage of computing (NVIDIA CUDA cores), AI (NVIDIA Tensor Cores), and ray tracing cores of NVIDIA GPUs for lightning-fast simulations of 6G systems.
We hope you share our excitement about Sionna, and we look forward to hearing about your success stories!
For more information, see the following resources:
- Sionna product page
- Sionna documentation
- nvlabs/sionna GitHub repo
 NVIDIA Clara Holoscan offers an expanded selection of third-party interface options for video capture, ultrasound research, data acquisition, and connection to legacy medical devices.
NVIDIA Clara Holoscan offers an expanded selection of third-party interface options for video capture, ultrasound research, data acquisition, and connection to legacy medical devices. At GTC 2022, NVIDIA announced Riva 2.0, Merlin 1.0, new features to NVIDIA Triton, and more.
At GTC 2022, NVIDIA announced Riva 2.0, Merlin 1.0, new features to NVIDIA Triton, and more. The Jetson AGX Orin Developer Kit offers 8X the performance of the last generation, offering the most powerful AI supercomputer for advanced robotics, and embedded and edge computing.
The Jetson AGX Orin Developer Kit offers 8X the performance of the last generation, offering the most powerful AI supercomputer for advanced robotics, and embedded and edge computing. Learn about all of the new applications, features, and functions released for developers to build, extend, and connect 3D tools and platforms to the Omniverse ecosystem seamlessly.
Learn about all of the new applications, features, and functions released for developers to build, extend, and connect 3D tools and platforms to the Omniverse ecosystem seamlessly.



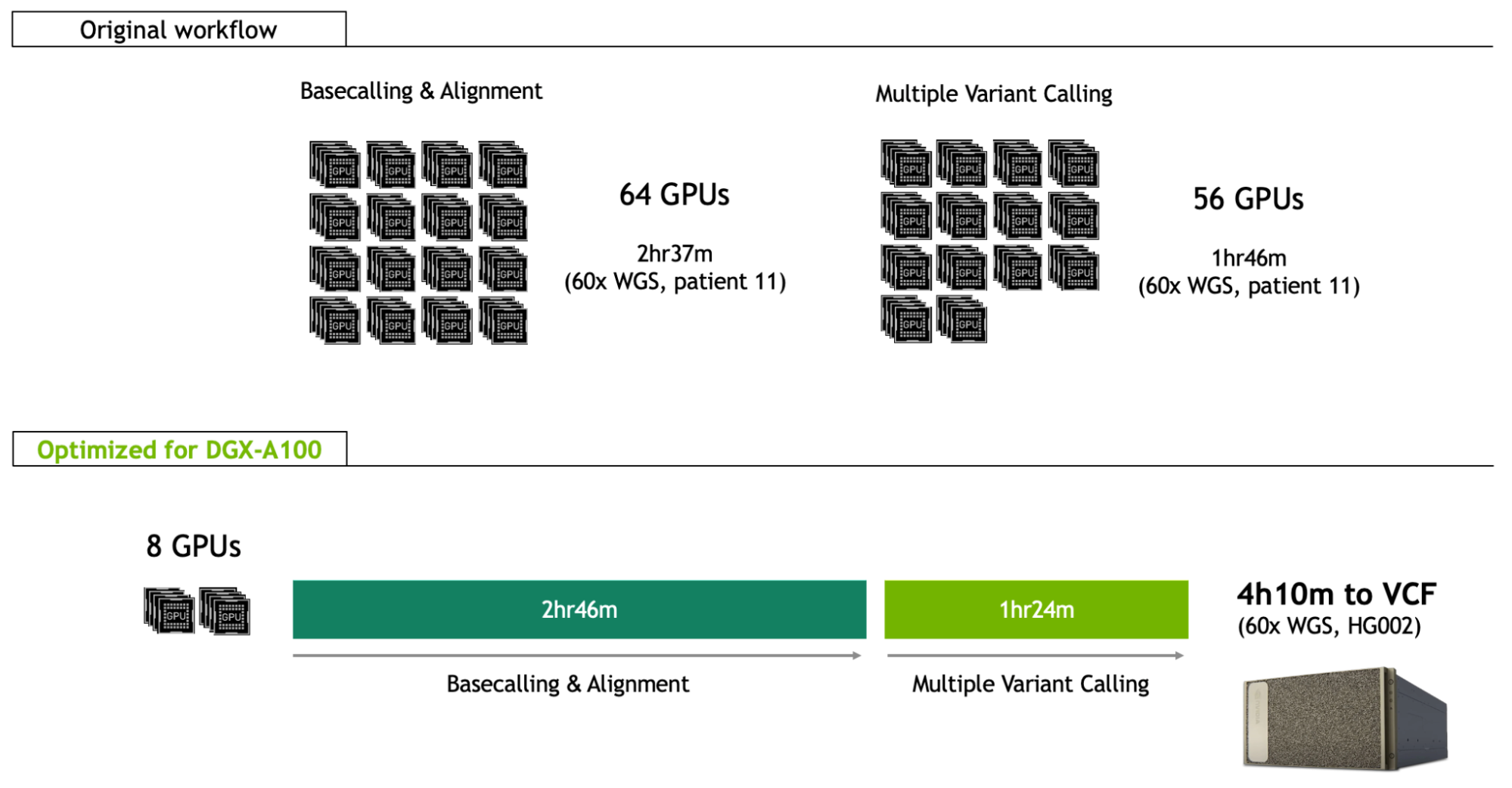
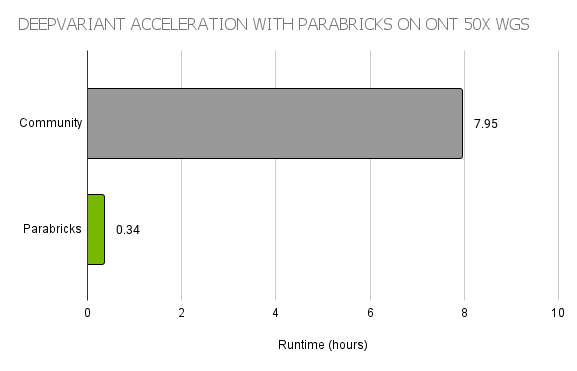
 Ultra rapid nanopore sequencing is bringing us one step closer to same-day whole genome genetic diagnosis.
Ultra rapid nanopore sequencing is bringing us one step closer to same-day whole genome genetic diagnosis.