Deep machine learning (ML) systems have achieved considerable success in medical image analysis in recent years. One major contributing factor is access to abundant labeled datasets, which are used to train highly effective supervised deep learning models. However, in the real-world, these models may encounter samples exhibiting rare conditions that are individually too infrequent for per-condition classification. Nevertheless, such conditions can be collectively common because they follow a long-tail distribution and when taken together can represent a significant portion of cases — e.g., in a recent deep learning dermatological study, hundreds of rare conditions composed around 20% of cases encountered by the model at test time.
To prevent models from generating erroneous outputs on rare samples at test time, there remains a considerable need for deep learning systems with the ability to recognize when a sample is not a condition it can identify. Detecting previously unseen conditions can be thought of as an out-of-distribution (OOD) detection task. By successfully identifying OOD samples, preventive measures can be taken, like abstaining from prediction or deferring to a human expert.
Traditional computer vision OOD detection benchmarks work to detect dataset distribution shifts. For example, a model may be trained on CIFAR images but be presented with street view house numbers (SVHN) as OOD samples, two datasets with very different semantic meanings. Other benchmarks seek to detect slight differences in semantic information, e.g., between images of a truck and a pickup truck, or two different skin conditions. The semantic distribution shifts in such near-OOD detection problems are more subtle in comparison to dataset distribution shifts, and thus, are harder to detect.
In “Does Your Dermatology Classifier Know What it Doesn’t Know? Detecting the Long-Tail of Unseen Conditions”, published in Medical Image Analysis, we tackle this near-OOD detection task in the application of dermatology image classification. We propose a novel hierarchical outlier detection (HOD) loss, which leverages existing fine-grained labels of rare conditions from the long tail and modifies the loss function to group unseen conditions and improve identification of these near OOD categories. Coupled with various representation learning methods and the diverse ensemble strategy, this approach enables us to achieve better performance for detecting OOD inputs.
The Near-OOD Dermatology Dataset
We curated a near-OOD dermatology dataset that includes 26 inlier conditions, each of which are represented by at least 100 samples, and 199 rare conditions considered to be outliers. Outlier conditions can have as low as one sample per condition. The separation criteria between inlier and outlier conditions can be specified by the user. Here the cutoff sample size between inlier and outlier was 100, consistent with our previous study. The outliers are further split into training, validation, and test sets that are intentionally mutually exclusive to mimic real-world scenarios, where rare conditions shown during test time may have not been seen in training.
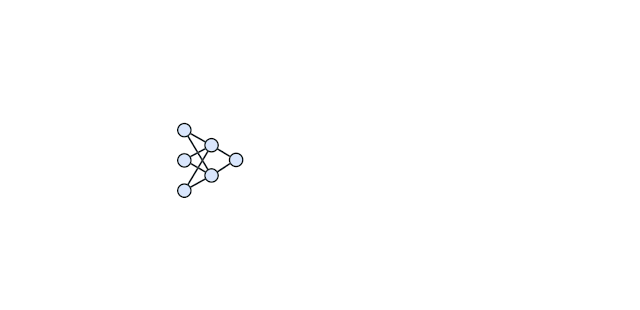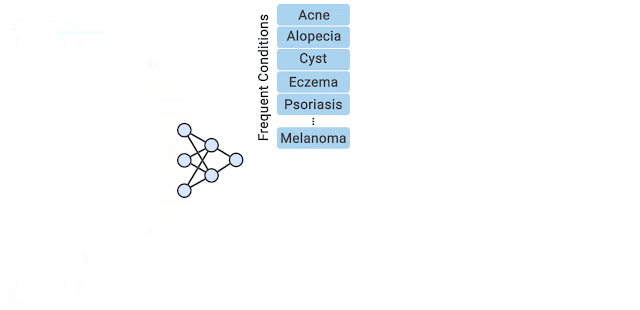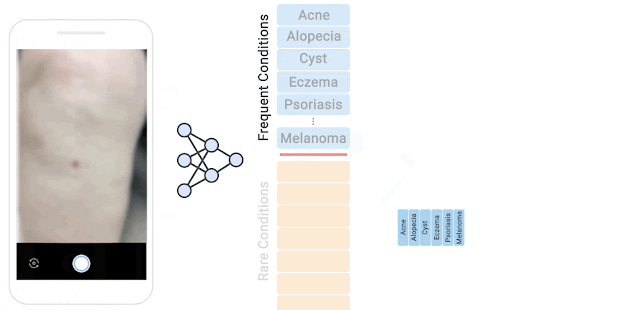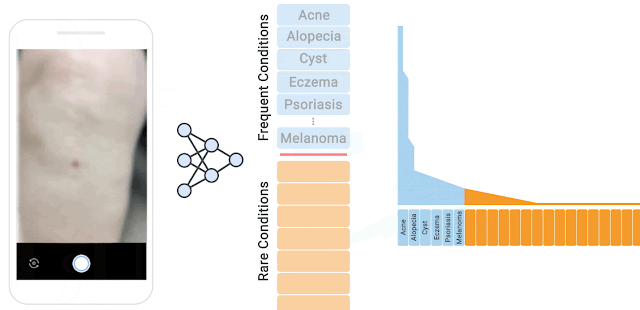 |
| Long tail distribution of different dermatological conditions in our dataset. The 26 inlier conditions, with at least 100 samples, (blue) and the remaining 199 rare outlier conditions (orange). Outlier conditions can have as low as one sample per condition. |
 |
| Train set | Validation set | Test set | ||||
| Inlier | Outlier | Inlier | Outlier | Inlier | Outlier | |
| Number of classes | 26 | 68 | 26 | 66 | 26 | 65 |
| Number of samples | 8854 | 1111 | 1251 | 1082 | 1192 | 937 |
| Inlier and outlier conditions in our benchmark dataset and detailed dataset split statistics. The outliers are further split into mutually exclusive train, validation, and test sets. |
Hierarchical Outlier Detection Loss
We propose to use “known outlier” samples during training that are leveraged to aid detection of “unknown outlier” samples during test time. Our novel hierarchical outlier detection (HOD) loss performs a fine-grained classification of individual classes for all inlier or outlier classes and, in parallel, a coarse-grained binary classification of inliers vs. outliers in a hierarchical setup (see the figure below). Our experiments confirmed that HOD is more effective than performing a coarse-grained classification followed by a fine-grained classification, as this could result in a bottleneck that impacted the performance of the fine-grained classifier.
We use the sum of the predictive probabilities of the outlier classes as the OOD score. As a primary OOD detection metric we use the area under receiver operating characteristics (AUROC) curve, which ranges between 0 and 1 and gives us a measure of separability between inliers and outliers. A perfect OOD detector, which separates all inliers from outliers, is assigned an AUROC score of 1. A popular baseline method, called reject bucket, separates each inlier individually from the outliers, which are grouped into a dedicated single abstention class. In addition to a fine-grained classification for each individual inlier and outlier classes, the HOD loss–based approach separates the inliers collectively from the outliers with a coarse-grained prediction loss, resulting in better generalization. While similar, we demonstrate that our HOD loss–based approach outperforms other baseline methods that leverage outlier data during training, achieving an AUROC score of 79.4% on the benchmark, a significant improvement over that of reject bucket, which achieves 75.6%.
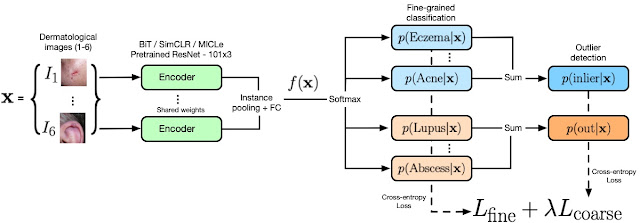 |
| Our model architecture and the HOD loss. The encoder (green) represents the wide ResNet 101×3 model pre-trained with different representation learning models (ImageNet, BiT, SimCLR, and MICLe; see below). The output of the encoder is sent to the HOD loss where fine-grained and coarse-grained predictions for inliers (blue) and outliers (orange) are obtained. The coarse predictions are obtained by summing over the fine-grained probabilities as indicated in the figure. The OOD score is defined as the sum of the probabilities of outlier classes. |
Representation Learning and the Diverse Ensemble Strategy
We also investigate how different types of representation learning help in OOD detection in conjunction with HOD by pretraining on ImageNet, BiT-L, SimCLR and MICLe models. We observe that including HOD loss improves OOD performance compared to the reject bucket baseline method for all four representation learning methods.
| Representation Learning Methods |
OOD detection metric (AUROC %) | |
| With reject bucket | With HOD loss | |
| ImageNet | 74.7% | 77% |
| BiT-L | 75.6% | 79.4% |
| SimCLR | 75.2% | 77.2% |
| MICLe | 76.7% | 78.8% |
| OOD detection performance for different representation learning models with reject bucket and with HOD loss. |
Another orthogonal approach for improving OOD detection performance and accuracy is deep ensemble, which aggregates outputs from multiple independently trained models to provide a final prediction. We build upon deep ensemble, but instead of using a fixed architecture with a fixed pre-training, we combine different representation learning architectures (ImageNet, BiT-L, SimCLR and MICLe) and introduce objective loss functions (HOD and reject bucket). We call this a diverse ensemble strategy, which we demonstrate outperforms the deep ensemble for OOD performance and inlier accuracy.
Downstream Clinical Trust Analysis
While we mainly focus on improving the performance for OOD detection, the ultimate goal for our dermatology model is to have high accuracy in predicting inlier and outlier conditions. We go beyond traditional performance metrics and introduce a “penalty” matrix that jointly evaluates inlier and outlier predictions for model trust analysis to approximate downstream impact. For a fixed confidence threshold, we count the following types of mistakes: (i) incorrect inlier predictions (i.e., mistaking inlier condition A as inlier condition B); (ii) incorrect abstention of inliers (i.e., abstaining from making a prediction for an inlier); and (iii) incorrect prediction for outliers as one of the inlier classes.
To account for the asymmetrical consequences of the different types of mistakes, penalties can be 0, 0.5, or 1. Both incorrect inlier and outlier-as-inlier predictions can potentially erode user trust in the model and were penalized with a score of 1. Incorrect abstention of an inlier as an outlier was penalized with a score of 0.5, indicating that potential model users should seek additional guidance given the model-expressed uncertainty or abstention. For correct decisions no cost is incurred, indicated by a score of 0.
| Action of the Model | ||||
| Prediction as Inlier | Abstain | |||
| Inlier | 0 (Correct)
1 (Incorrect, mistakes |
0.5 (Incorrect, abstains inliers) |
||
| Outlier | 1 (Incorrect, mistakes that may erode trust) |
0 (Correct) | ||
| The penalty matrix is designed to capture the potential impact of different types of model errors. |
Because real-world scenarios are more complex and contain a variety of unknown variables, the numbers used here represent simplifications to enable qualitative approximations for the downstream impact on user trust of outlier detection models, which we refer to as “cost”. We use the penalty matrix to estimate a downstream cost on the test set and compare our method against the baseline, thereby making a stronger case for its effectiveness in real-world scenarios. As shown in the plot below, our proposed solution incurs a much lower estimated cost in comparison to baseline over all possible operating points.
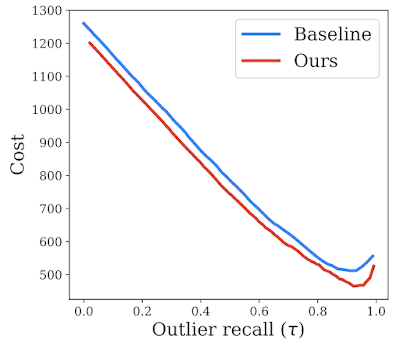 |
| Trust analysis comparing our proposed method to the baseline (reject bucket) for a range of outlier recall rates, indicated by 𝛕. We show that our method reduces downstream estimated cost, potentially reflecting improved downstream impact. |
Conclusion
In real-world deployment, medical ML models may encounter conditions that were not seen in training, and it’s important that they accurately identify when they do not know a specific condition. Detecting those OOD inputs is an important step to improving safety. We develop an HOD loss that leverages outlier data during training, and combine it with pre-trained representation learning models and a diverse ensemble to further boost performance, significantly outperforming the baseline approach on our new dermatology benchmark dataset. We believe that our approach, aligned with our AI Principles, can aid successful translation of ML algorithms into real-world scenarios. Although we have primarily focused on OOD detection for dermatology, most of our contributions are fairly generic and can be easily incorporated into OOD detection for other applications.
Acknowledgements
We would like to thank Shekoofeh Azizi, Aaron Loh, Vivek Natarajan, Basil Mustafa, Nick Pawlowski, Jan Freyberg, Yuan Liu, Zach Beaver, Nam Vo, Peggy Bui, Samantha Winter, Patricia MacWilliams, Greg S. Corrado, Umesh Telang, Yun Liu, Taylan Cemgil, Alan Karthikesalingam, Balaji Lakshminarayanan, and Jim Winkens for their contributions. We would also like to thank Tom Small for creating the post animation.

 Learn how edge computing is powering efficient energy operations, protecting worker health and safety, and improving power grid resiliency.
Learn how edge computing is powering efficient energy operations, protecting worker health and safety, and improving power grid resiliency.
 This month the NGC catalog added new containers, model resumes, container security scan reports, and more to help identify and deploy AI software faster.
This month the NGC catalog added new containers, model resumes, container security scan reports, and more to help identify and deploy AI software faster.