Posted by Pete Florence, Research Scientist and Corey Lynch, Research Engineer, Robotics at Google
Despite considerable progress in robot learning over the past several years, some policies for robotic agents can still struggle to decisively choose actions when trying to imitate precise or complex behaviors. Consider a task in which a robot tries to slide a block across a table to precisely position it into a slot. There are many possible ways to solve this task, each requiring precise movements and corrections. The robot must commit to just one of these options, but must also be capable of changing plans each time the block ends up sliding farther than expected. Although one might expect such a task to be easy, that is often not the case for modern learning-based robots, which often learn behavior that expert observers describe as indecisive or imprecise.
Example of a baseline explicit behavior cloning model struggling on a task where the robot needs to slide a block across a table and then precisely insert it into a fixture.
To encourage robots to be more decisive, researchers often utilize a discretized action space, which forces the robot to choose option A or option B, without oscillating between options. For example, discretization was a key element of our recent Transporter Networks architecture, and is also inherent in many notable achievements by game-playing agents, such as AlphaGo, AlphaStar, and OpenAI’s Dota bot. But discretization brings its own limitations — for robots that operate in the spatially continuous real world, there are at least two downsides to discretization: (i) it limits precision, and (ii) it triggers the curse of dimensionality, since considering discretizations along many different dimensions can dramatically increase memory and compute requirements. Related to this, in 3D computer vision much recent progress has been powered by continuous, rather than discretized, representations.
With the goal of learning decisive policies without the drawbacks of discretization, today we announce our open source implementation of Implicit Behavioral Cloning (Implicit BC), which is a new, simple approach to imitation learning and was presented last week at CoRL 2021. We found that Implicit BC achieves strong results on both simulated benchmark tasks and on real-world robotic tasks that demand precise and decisive behavior. This includes achieving state-of-the-art (SOTA) results on human-expert tasks from our team’s recent benchmark for offline reinforcement learning, D4RL. On six out of seven of these tasks, Implicit BC outperforms the best previous method for offline RL, Conservative Q Learning. Interestingly, Implicit BC achieves these results without requiring any reward information, i.e., it can use relatively simple supervised learning rather than more-complex reinforcement learning.
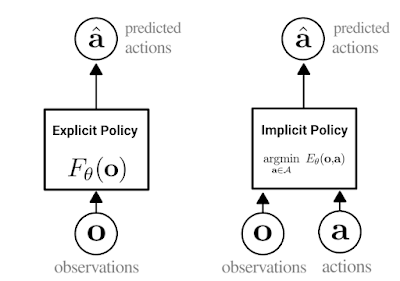
Implicit Behavioral Cloning Our approach is a type of behavior cloning, which is arguably the simplest way for robots to learn new skills from demonstrations. In behavior cloning, an agent learns how to mimic an expert’s behavior using standard supervised learning. Traditionally, behavior cloning involves training an explicit neural network (shown below, left), which takes in observations and outputs expert actions.
The key idea behind Implicit BC is to instead train a neural network to take in both observations and actions, and output a single number that is low for expert actions and high for non-expert actions (below, right), turning behavioral cloning into an energy-based modeling problem. After training, the Implicit BC policy generates actions by finding the action input that has the lowest score for a given observation.
Depiction of the difference between explicit (left) and implicit (right) policies. In the implicit policy, the “argmin” means the action that, when paired with a particular observation, minimizes the value of the energy function.
To train Implicit BC models, we use an InfoNCE loss, which trains the network to output low energy for expert actions in the dataset, and high energy for all others (see below). It is interesting to note that this idea of using models that take in both observations and actions is common in reinforcement learning, but not so in supervised policy learning.
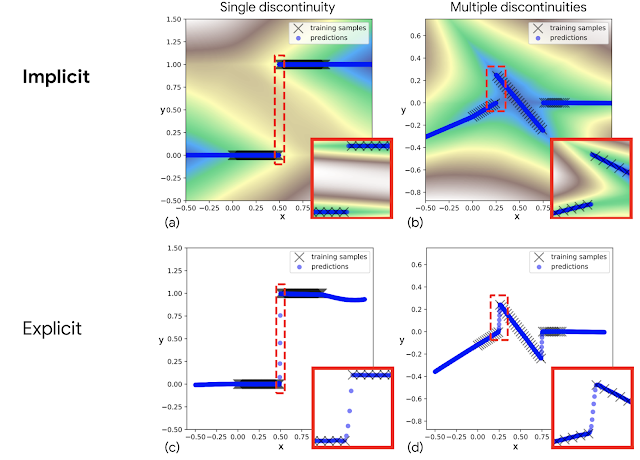
Animation of how implicit models can fit discontinuities — in this case, training an implicit model to fit a step (Heaviside) function. Left: 2D plot fitting the black (X) training points — the colors represent the values of the energies (blue is low, brown is high). Middle: 3D plot of the energy model during training. Right: Training loss curve.
Once trained, we find that implicit models are particularly good at precisely modeling discontinuities (above) on which prior explicit models struggle (as in the first figure of this post), resulting in policies that are newly capable of switching decisively between different behaviors.
But why do conventional explicit models struggle? Modern neural networks almost always use continuous activation functions — for example, Tensorflow, Jax, and PyTorch all only ship with continuous activation functions. In attempting to fit discontinuous data, explicit networks built with these activation functions cannot represent discontinuities, so must draw continuous curves between data points. A key aspect of implicit models is that they gain the ability to represent sharp discontinuities, even though the network itself is composed only of continuous layers.
We also establish theoretical foundations for this aspect, specifically a notion of universal approximation. This proves the class of functions that implicit neural networks can represent, which can help justify and guide future research.
Examples of fitting discontinuous functions, for implicit models (top) compared to explicit models (bottom). The red highlighted insets show that implicit models represent discontinuities (a) and (b) while the explicit models must draw continuous lines (c) and (d) in between the discontinuities.
One challenge faced by our initial attempts at this approach was “high action dimensionality”, which means that a robot must decide how to coordinate many motors all at the same time. To scale to high action dimensionality, we use either autoregressive models or Langevin dynamics.
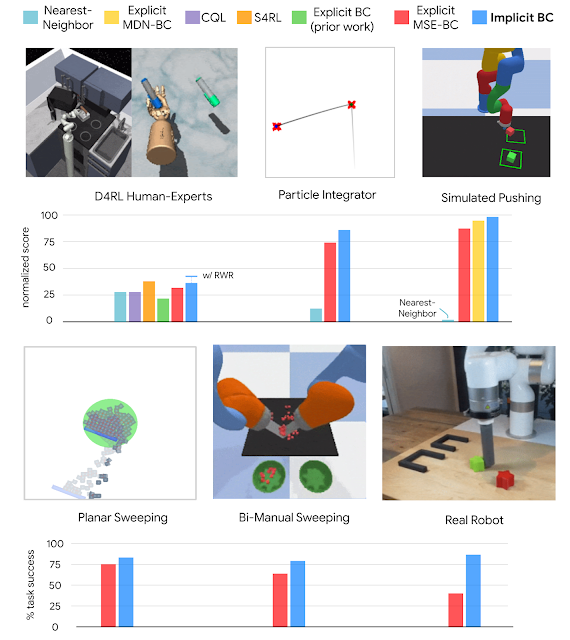
Highlights In our experiments, we found Implicit BC does particularly well in the real world, including an order of magnitude (10x) better on the 1mm-precision slide-then-insert task compared to a baseline explicit BC model. On this task the implicit model does several consecutive precise adjustments (below) before sliding the block into place. This task demands multiple elements of decisiveness: there are many different possible solutions due to the symmetry of the block and the arbitrary ordering of push maneuvers, and the robot needs to discontinuously decide when the block has been pushed far “enough” before switching to slide it in a different direction. This is in contrast to the indecisiveness that is often associated with continuous-controlled robots.
Example task of sliding a block across a table and precisely inserting it into a slot. These are autonomous behaviors of our Implicit BC policies, using only images (from the shown camera) as input.
A diverse set of different strategies for accomplishing this task. These are autonomous behaviors from our Implicit BC policies, using only images as input.
In another challenging task, the robot needs to sort blocks by color, which presents a large number of possible solutions due to the arbitrary ordering of sorting. On this task the explicit models are customarily indecisive, while implicit models perform considerably better.
Comparison of implicit (left) and explicit (right) BC models on a challenging continuous multi-item sorting task. (4x speed)
In our testing, implicit BC models can also exhibit robust reactive behavior, even when we try to interfere with the robot, despite the model never seeing human hands.
Robust behavior of the implicit BC model despite interfering with the robot.
Overall, we find that Implicit BC policies can achieve strong results compared to state of the art offline reinforcement learning methods across several different task domains. These results include tasks that, challengingly, have either a low number of demonstrations (as few as 19), high observation dimensionality with image-based observations, and/or high action dimensionality up to 30 — which is a large number of actuators to have on a robot.
Policy learning results of Implicit BC compared to baselines across several domains.
Conclusion Despite its limitations, behavioral cloning with supervised learning remains one of the simplest ways for robots to learn from examples of human behaviors. As we showed here, replacing explicit policies with implicit policies when doing behavioral cloning allows robots to overcome the “struggle of decisiveness”, enabling them to imitate much more complex and precise behaviors. While the focus of our results here was on robot learning, the ability of implicit functions to model sharp discontinuities and multimodal labels may have broader interest in other application domains of machine learning as well.
Acknowledgements Pete and Corey summarized research performed together with other co-authors: Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. The authors would also like to thank Vikas Sindwhani for project direction advice; Steve Xu, Robert Baruch, Arnab Bose for robot software infrastructure; Jake Varley, Alexa Greenberg for ML infrastructure; and Kamyar Ghasemipour, Jon Barron, Eric Jang, Stephen Tu, Sumeet Singh, Jean-Jacques Slotine, Anirudha Majumdar, Vincent Vanhoucke for helpful feedback and discussions.
When Julien Trombini and Guillaume Cazenave founded video-analytics startup Two-i four years ago, they had an ambitious goal: improving the quality of urban life by one day being able to monitor a city’s roads, garbage collection and other public services. Along the way, the pair found a wholly different niche. Today, the company’s technology — Read article >
How to integrate the NVIDIA GPU and Network Operators
NVIDIA Operators simplify GPU and SmartNIC management on Kubernetes. This post shows how to integrate NVIDIA Operators into new edge AI platforms using preinstalled drivers. This is the first post in a two-part series. The next post describes how to integrate NVIDIA Operators using custom driver containers.
AI makes sensor data actionable. Trained AI models recognize patterns and trigger responses. A trained AI model represents a company’s business intelligence. Just as crude oil becomes valuable when refined into petroleum, AI transforms sensor data into insight.
That is why edge AI needs acceleration. NVIDIA GPUs and SmartNICs future-proof an edge AI platform against exponential data growth.
Edge AI is Cloud Native
This post describes how to integrate NVIDIA accelerators with Kubernetes. Why focus on Kubernetes? Because edge AI is cloud native. Most AI applications are container-based microservices. Kubernetes is the unofficial standard for container orchestration.
Edge AI platforms build on Kubernetes due to its flexibility. The Kubernetes API supports declarative automation and is extensible through custom resource definitions. A robust software ecosystem supports Kubernetes day one and day two operations.
NVIDIA Fleet Command is one example of a Kubernetes-based Edge AI platform. Fleet Command is a hybrid cloud service designed for security and performance. It manages AI application lifecycle on bare metal edge nodes. Fleet Command also integrates with NGC, NVIDIA’s curated registry of more than 700 GPU-optimized applications.
While Fleet Command supports NVIDIA GPUs and SmartNICs, many edge platforms do not. For those, NVIDIA provides open-source Kubernetes operators to enable GPU and SmartNIC acceleration. There are two operators: the NVIDIA GPU Operator and the NVIDIA Network Operator.
The NVIDIA GPU Operator automates GPU deployment and management on Kubernetes. The GPU Operator Helm Chart is available on NGC. It includes several components:
Figure 1. These components make up the NVIDIA GPU Operator
The NVIDIA Network Operator automates CONNECTX SmartNIC configuration for Kubernetes pods that need fast networking. It is also delivered as a Helm chart. The Network Operator adds a second network interface to a pod using the Multus CNI plug-in. It supports both Remote Direct Memory Access (RDMA) and Shared Root I/O Virtualization (SRIOV).
The NVIDIA Network Operator includes the following components:
The SRIOV device plug-in attaches SRIOV Virtual Functions (VFs) to pods.
The Containernetworking CNI plug-in is a standard interface for extending Kubernetes networking capabilities.
The Whereabouts CNI plug-in manages cluster-wide automatic IP addresses creation and assignment.
The MACVLAN CNI functions as a virtual switch to connect pods to network functions.
The Multus CNI plug-in enables attaching multiple network devices to a Kubernetes pod.
The Host-device CNI plug-in moves an existing device (such as an SRIOV VF) from the host to network namespace the pod’s.
Figure 2. These components make up the NVIDIA Network Operator components
Both operators use Node Feature Discovery. This service identifies which cluster nodes have GPUs and SmartNICs.
The operators work together or separately. Deploying them together enables GPUDirect RDMA. This feature bypasses host buffering to increase throughput between the NIC and GPU.
The NVIDIA operators are open source software. They already support popular Kubernetes distributions running on NVIDIA Certified servers. But many edge platforms run customized Linux distributions the operators do not support. This post explains how to integrate NVIDIA operators with those platforms.
Two Paths, One Way
Figure 3. This image represents the are two methods for integrating NVIDIA Operators: preinstalled drivers or custom driver containers
Portability is one of the main benefits of cloud native software. Containers bundle applications with their dependencies. This lets them run, scale, and migrate across different platforms without friction.
NVIDIA operators are container-based, cloud native applications. Most of the operator services do not need any integration to run on a new platform. But both operators include driver containers, and drivers are the exception. Drivers are kernel-dependent. Integrating NVIDIA operators with a new platform involves rebuilding the driver containers for the target kernel. The platform may be running an unsupported Linux distribution or a custom-compiled kernel.
There are two approaches to delivering custom drivers:
First, by installing the drivers onto the host before installing the operators. Many edge platforms deliver signed drivers in their base operating system image to support secure and measured boot. Platforms requiring signed drivers cannot use the driver containers deployed by the operators. NVIDIA Fleet Command follows this pattern. Both the Network and GPU operators support preinstalled drivers by disabling their own driver containers.
The second approach is to replace the operator’s driver containers with custom containers. Edge platforms with immutable file systems prefer this method. Edge servers often run as appliances. They use read-only file systems to increase security and prevent configuration drift. Running driver and application containers in memory instead of adding them to the immutable image reduces its size and complexity. This also allows the same image to run on nodes with different hardware profiles.
This post explains how to set up both patterns. The first section of the post describes driver preinstallation. The second section describes how to build and install custom driver containers.
Apart from the driver containers, the remaining operator services generally run on new platforms without modification. NVIDIA tests both operators on leading container runtimes such as Docker Engine, CRI-O, and Containerd. The GPU Operator also supports the runtime class resource for per-pod runtime selection.
Preinstalled driver integration
The rest of this post shows how to integrate NVIDIA operators with custom edge platforms. It includes step-by-step procedures for both the driver preinstallation and driver container methods.
Table 1 describes the test system used to demonstrate these procedures.
TABLE 1: Test System Description
Linux Distribution
Centos 7.9.2009
GPU Operator
v1.8.2
Kernel version
3.10.0-1160.45.1.el7.custom
GPU Driver (operator)
470.74
Container runtime
Crio-21.3
Network Operator
v1.0.0
Kubernetes
1.21.3-0
MOFED (operator)
5.4-1.0.3.0
Helm
v3.3.3
CUDA
11.4
Cluster network
Calico v3.20.2
GPU Driver (local)
470.57.02
Compiler
GCC 4.8.5 2015062
MOFED (local)
5.4-1.0.3.0
Developer tools
Elfutils 0.176-5
Node Feature Discovery
v0.8.0
Server
NVIDIA DRIVE Constellation
GPU
A100-PCIE-40GB
Server BIOS
v5.12
SmartNIC
ConnectX-6 Dx MT2892
CPU
(2) Intel Xeon Gold 6148
SmartNIC Firmware
22.31.1014
The operating system, Linux kernel, and container runtime combination on the test system is not supported by either operator. The Linux kernel is custom compiled, so precompiled drivers are not available. The test system also uses the Cri-o container runtime, which is less common than alternatives like Containerd and Docker Engine.
Prepare the System
First, verify that the CONNECTX SmartNIC and NVIDIA GPU are visible on the test system.
$ lspci | egrep 'nox|NVI'
23:00.0 3D controller: NVIDIA Corporation Device 20f1 (rev a1)
49:00.0 Ethernet controller: Mellanox Technologies MT2892 Family [ConnectX-6 Dx]
49:00.1 Ethernet controller: Mellanox Technologies MT2892 Family [ConnectX-6 Dx]
5e:00.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx]
e3:00.0 Ethernet controller: Mellanox Technologies MT2892 Family [ConnectX-6 Dx]
e3:00.1 Ethernet controller: Mellanox Technologies MT2892 Family [ConnectX-6 Dx]
e6:00.0 3D controller: NVIDIA Corporation Device 20f1 (rev a1)
2. View the operating system and Linux kernel versions. In this example, the Centos 7 3.10.0-1160.45.1 kernel was recompiled to 3.10.0-1160.45.1.el7.custom.x86_64.
3. View the Kubernetes version, network configuration, and cluster nodes. This output shows a single node cluster, which is a typical pattern for edge AI deployments. The node is running Kubernetes version 1.21.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
cgx-20 Ready control-plane 23d v1.21.3
4. View the installed container runtime. This example shows the cri-o container runtime.
5. NVIDIA delivers operators through Helm charts. View the installed Helm version.
$ helm version
version.BuildInfo{Version:"v3.3.3", GitCommit:"55e3ca022e40fe200fbc855938995f40b2a68ce0", GitTreeState:"clean", GoVersion:"go1.14.9"}
Install the Network Operator with preinstalled Drivers
The Mellanox OpenFabrics Enterprise Distribution for Linux installs open source drivers and libraries for high-performance networking. The NVIDIA Network Operator optionally installs a MOFED container to load these drivers and libraries on Kubernetes. This section describes the process for preinstalling MOFED drivers on the host in the event that the included driver container cannot be used.
5. After reboot, make sure that the drivers are loaded.
$ /etc/init.d/openibd status
HCA driver loaded
Configured Mellanox EN devices:
enp94s0
ens13f0
ens13f1
ens22f0
ens22f1
Currently active Mellanox devices:
enp94s0
ens13f0
ens13f1
ens22f0
ens22f1
The following OFED modules are loaded:
rdma_ucm
rdma_cm
ib_ipoib
mlx5_core
mlx5_ib
ib_uverbs
ib_umad
ib_cm
ib_core
mlxfw
Once MOFED is successfully installed and the drivers are loaded, proceed to installing the NVIDIA Network Operator.
6. Identify the secondary network device name. This will be the device or devices plumbed into the pod as a secondary network interface.
$ ibdev2netdev
mlx5_0 port 1 ==> ens13f0 (Up)
mlx5_1 port 1 ==> ens13f1 (Down)
mlx5_2 port 1 ==> enp94s0 (Up)
mlx5_3 port 1 ==> ens22f0 (Up)
mlx5_4 port 1 ==> ens22f1 (Down)
7. By default the Network Operator does not deploy to a Kubernetes master. Remove the master label from the node to accommodate the all-in-one cluster deployment.
Note this is a temporary workaround to allow Network Operator to schedule pods to the master node in a single node cluster. Future versions of the Network Operator will add toleration and nodeAffinity to avoid this workaround.
8. Add the Mellanox Helm chart repository.
$ helm repo add mellanox https://mellanox.github.io/network-operator
$ helm repo update
$ helm repo ls
NAME URL
mellanox https://mellanox.github.io/network-operator
9. Create a values.yaml to specify Network Operator configuration. This example deploys the RDMA shared device plug-in and specifies ens13f0 as the RDMA-capable interface.
11. Verify that all Network Operator pods are in Running status.
$ kubectl get pods -n nvidia-network-operator-resources
NAME READY STATUS RESTARTS AGE
cni-plugins-ds-fcrsq 1/1 Running 0 3m44s
kube-multus-ds-4n526 1/1 Running 0 3m44s
rdma-shared-dp-ds-5rq4x 1/1 Running 0 3m44s
whereabouts-9njxm 1/1 Running 0 3m44s
Note that some versions of Calico are incompatible with certain Multus CNI versions. Change the Multus API version after the Multus daemonset starts.
$ sed -i 's/0.4.0/0.3.1/' /etc/cni/net.d/00-multus.conf
12. The Helm chart creates a configMap that is used to label the node with the selectors defined in the values.yaml file. Verify that the node is correctly labeled by NFD and that the RDMA shared devices are created.
7. Install the GPU Operator Helm chart repository.
$ helm repo add nvidia https://nvidia.github.io/gpu-operator
$ helm repo update
# helm repo ls
NAME URL
nvidia https://nvidia.github.io/gpu-operator
mellanox https://mellanox.github.io/network-operator
8. Install the GPU Operator Helm chart. Overriding the driver.enabled parameter to false disables driver container installation. Also specify crio as the container runtime.
$ helm install --generate-name nvidia/gpu-operator --set driver.enabled=false --set toolkit.version=1.7.1-centos7 --set operator.defaultRuntime=crio
$ helm ls
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gpu-operator-1635194696 default 1 2021-10-25 16:44:57.237363636 -0400 EDT deployed gpu-operator-v1.8.2 v1.8.2
9. View the GPU Operator resources. All pods should be in status Running or Completed.
10. View the validation pod logs to verify validation tests completed.
$ kubectl logs -n gpu-operator-resources nvidia-device-plugin-validator-845pw
device-plugin workload validation is successful
$ kubectl logs -n gpu-operator-resources nvidia-cuda-validator-ndc78
cuda workload validation is successful
11. Run nvidia-smi from within the validator container to display the GPU, driver, and CUDA versions. This also validates that the container runtime prestart hook works as expected.
$ kubectl exec -n gpu-operator-resources -i -t nvidia-operator-validator-5ngbk --container nvidia-operator-validator -- nvidia-smi
Mon Oct 25 20:57:28 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-PCI... Off | 00000000:23:00.0 Off | 0 |
| N/A 26C P0 32W / 250W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-PCI... Off | 00000000:E6:00.0 Off | 0 |
| N/A 26C P0 32W / 250W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Test the Preinstalled Driver Integration
Test the preinstalled driver integration by creating test pods.
1. Create a network attachment definition. A network attachment definition is a custom resource that allows pods to connect to one or more networks. This network attachment definition defines a MAC VLAN Network that bridges multiple pods across a secondary interface. The Whereabouts CNI automates IP address assignments for pods connected to the secondary network.
7. The GPU Operator creates pods to validate the driver, container runtime, and Kubernetes device plug-in. Create an additional GPU test pod.
$ cat
8. View the results.
$ kubectl get pod cuda-vectoradd
NAME READY STATUS RESTARTS AGE
cuda-vectoradd 0/1 Completed 0 34s
$ kubectl logs cuda-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
9. Load the nvidia-peermem driver. It provides GPUDirect RDMA for CONNECTX SmartNICs. This driver is included in NVIDIA Linux GPU driver version 470 and greater. It is compiled automatically during Linux driver installation if both the ib_core and NVIDIA GPU driver sources are present on the system. This means the MOFED driver should be installed before the GPU driver so the MOFED source is available to build the nvidia-peermem driver.
Part 2 of this series will be published on 11/22. It will describe how to integrate the NVIDIA GPU and Network Operators with custom driver containers.
By the time the night was over, it felt like Jensen Huang had given everyone in the ballroom a good laugh and a few things to think about. The annual dinner of the Semiconductor Industry Association—a group of companies that together employ a quarter-million workers in the U.S. and racked up U.S. sales over $200 Read article >
I am newbie to keras and tensorflow. Please i need help to convert feature maps generated by a conv layer to numpy to do some computation and then convert them back to tensor to be fed to next layer in the model.
i believe this is easy to you. here is a dummy sample of code to show the problem :
def convert_to_numpy(tensor): grab_the_new_feature_maps = [] #to grab every feature map feature_maps_arry = tensor.numpy() # convert tensor to array for i in range(feature_maps_arry.shape[2]): single_fm = feature_maps_arry[i] max_value= np.max(single_fm) #find the maximum pixel value in fm min_value= np.min(single_fm) #find the minimum pixel value in fm ########### do the rest of conputations ########## grab_the_new_feature_maps.append(single_fm) back_to_tensor = tf.convert_to_tensor(grab_the_new_feature_maps) return back_to_tensor
Note the custom layer should not create new layer but use the weights and bias of the received tensor and convert it to numpy, do the computation, and then return the tensor with updated feature maps to the model: My custom layer is as the following
Posted by David Ha, Staff Research Scientist and Yujin Tang, Research Software Engineer, Google Research, Tokyo
“The brain is able to use information coming from the skin as if it were coming from the eyes. We don’t see with the eyes or hear with the ears, these are just the receptors, seeing and hearing in fact goes on in the brain.”
People have the amazing ability to use one sensory modality (e.g., touch) to supply environmental information normally gathered by another sense (e.g., vision). This adaptive ability, called sensory substitution, is a phenomenon well-known to neuroscience. While difficult adaptations — such as adjusting to seeing things upside-down, learning to ride a “backwards” bicycle, or learning to “see” by interpreting visual information emitted from a grid of electrodes placed on one’s tongue — require anywhere from weeks, months or even years to attain mastery, people are able to eventually adjust to sensory substitutions.
In contrast, most neural networks are not able to adapt to sensory substitutions at all. For instance, most reinforcement learning (RL) agents require their inputs to be in a pre-specified format, or else they will fail. They expect fixed-size inputs and assume that each element of the input carries a precise meaning, such as the pixel intensity at a specified location, or state information, like position or velocity. In popular RL benchmark tasks (e.g., Ant or Cart-pole), an agent trained using current RL algorithms will fail if its sensory inputs are changed or if the agent is fed additional noisy inputs that are unrelated to the task at hand.
In “The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning”, a spotlight paper at NeurIPS 2021, we explore permutation invariant neural network agents, which require each of their sensory neurons (receptors that receive sensory inputs from the environment) to figure out the meaning and context of its input signal, rather than explicitly assuming a fixed meaning. Our experiments show that such agents are robust to observations that contain additional redundant or noisy information, and to observations that are corrupt and incomplete.
Permutation invariant reinforcement learning agents adapting to sensory substitutions. Left: The ordering of the ant’s 28 observations are randomly shuffled every 200 time-steps. Unlike the standard policy, our policy is not affected by the suddenly permuted inputs. Right: Cart-pole agent given many redundant noisy inputs (Interactive web-demo).
In addition to adapting to sensory substitutions in state-observation environments (like the ant and cart-pole examples), we show that these agents can also adapt to sensory substitutions in complex visual-observation environments (such as a CarRacing game that uses only pixel observations) and can perform when the stream of input images is constantly being reshuffled:
We partition the visual input from CarRacing into a 2D grid of small patches, and shuffled their ordering. Without any additional training, our agent still performs even when the original training background (left) is replaced with new images (right).
Method Our approach takes observations from the environment at each time-step and feeds each element of the observation into distinct, but identical neural networks (called “sensory neurons”), each with no fixed relationship with one another. Each sensory neuron integrates over time information from only their particular sensory input channel. Because each sensory neuron receives only a small part of the full picture, they need to self-organize through communication in order for a global coherent behavior to emerge.
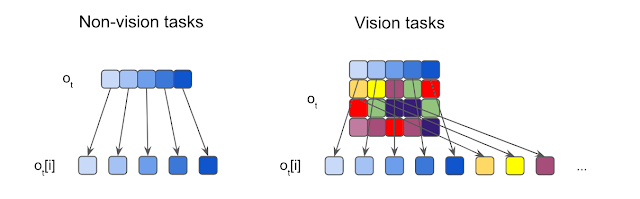
Illustration of observation segmentation.We segment each input into elements, which are then fed to independent sensory neurons. For non-vision tasks where the inputs are usually 1D vectors, each element is a scalar. For vision tasks, we crop each input image into non-overlapping patches.
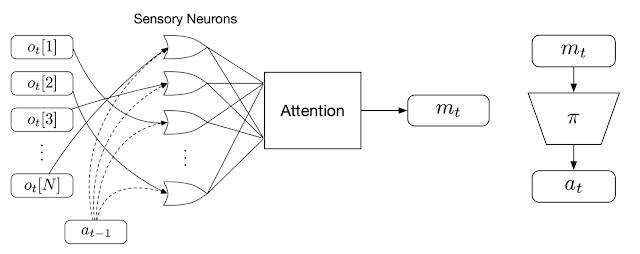
We encourage neurons to communicate with each other by training them to broadcast messages. While receiving information locally, each individual sensory neuron also continually broadcasts an output message at each time-step. These messages are consolidated and combined into an output vector, called the global latent code, using an attention mechanism similar to that applied in the Transformer architecture. A policy network then uses the global latent code to produce the action that the agent will use to interact with the environment. This action is also fed back into each sensory neuron in the next time-step, closing the communication loop.
Overview of the permutation-invariant RL method. We first feed each individual observation (ot) into a particular sensory neuron (along with the agent’s previous action, at-1). Each neuron then produces and broadcasts a message independently, and an attention mechanism summarizes them into a global latent code (mt) that is given to the agent’s downstream policy network (𝜋) to produce the agent’s action at.
Why is this system permutation invariant? Each sensory neuron is an identical neural network that is not confined to only process information from one particular sensory input. In fact, in our setup, the inputs to each sensory neuron are not defined. Instead, each neuron must figure out the meaning of its input signal by paying attention to the inputs received by the other sensory neurons, rather than explicitly assuming a fixed meaning. This encourages the agent to process the entire input as an unordered set, making the system to be permutation invariant to its input. Furthermore, in principle, the agent can use as many sensory neurons as required, thus enabling it to process observations of arbitrary length. Both of these properties will help the agent adapt to sensory substitutions.
Results We demonstrate the robustness and flexibility of this approach in simpler, state-observation environments, where the observations the agent receives as inputs are low-dimensional vectors holding information about the agent’s states, such as the position or velocity of its components. The agent in the popular Ant locomotion task has a total of 28 inputs with information that includes positions and velocities. We shuffle the order of the input vector several times during a trial and show that the agent is rapidly able to adapt and is still able to walk forward.
In cart-pole, the agent’s goal is to swing up a cart-pole mounted at the center of the cart and balance it upright. Normally the agent sees only five inputs, but we modify the cartpole environment to provide 15 shuffled input signals, 10 of which are pure noise, and the remainder of which are the actual observations from the environment. The agent is still able to perform the task, demonstrating the system’s capacity to work with a large number of inputs and attend only to channels it deems useful. Such flexibility may find useful applications for processing a large unspecified number of signals, most of which are noise, from ill-defined systems.
We also apply this approach to high-dimensional vision-based environments where the observation is a stream of pixel images. Here, we investigate screen-shuffled versions of vision-based RL environments, where each observation frame is divided into a grid of patches, and like a puzzle, the agent must process the patches in a shuffled order to determine a course of action to take. To demonstrate our approach on vision-based tasks, we created a shuffled version of Atari Pong.
Shuffled Pong results. Left: Pong agent trained to play using only 30% of the patches matches performance of Atari opponent. Right: Without extra training, when we give the agent more puzzle pieces, its performance increases.
Here the agent’s input is a variable-length list of patches, so unlike typical RL agents, the agent only gets to “see” a subset of patches from the screen. In the puzzle pong experiment, we pass to the agent a random sample of patches across the screen, which are then fixed through the remainder of the game. We find that we can discard 70% of the patches (at these fixed-random locations) and still train the agent to perform well against the built-in Atari opponent. Interestingly, if we then reveal additional information to the agent (e.g., allowing it access to more image patches), its performance increases, even without additional training. When the agent receives all the patches, in shuffled order, it wins 100% of the time, achieving the same result with agents that are trained while seeing the entire screen.
We find that imposing additional difficulty during training by using unordered observations has additional benefits, such as improving generalization to unseen variations of the task, like when the background of the CarRacing training environment is replaced with a novel image.
Shuffled CarRacing results. The agent has learned to focus its attention (indicated by the highlighted patches) on the road boundaries. Left: Training environment. Right: Test environment with new background.
Conclusion The permutation invariant neural network agents presented here can handle ill-defined, varying observation spaces. Our agents are robust to observations that contain redundant or noisy information, or observations that are corrupt and incomplete. We believe that permutation invariant systems open up numerous possibilities in reinforcement learning.
If you’re interested to learn more about this work, we invite readers to read our interactive article (pdf version) or watch our video. We also released code to reproduce our experiments.
Fewer than 4,000 tigers remain worldwide, according to Tigers United, a university consortium that recently began using AI to help save the species. Jeremy Dertien is a conservation biologist with Tigers United and a Ph.D. candidate in wildlife biology and conservation planning at Clemson University. He spoke with NVIDIA AI Podcast host Noah Kravitz about Read article >
Manufacturers are bringing product designs to life in a newly immersive world. Rendermedia, based in the U.K., specializes in immersive solutions for commerce and industries. The company provides clients with tools and applications for photorealistic virtual, augmented and extended reality (collectively known as XR) in areas like product design, training and collaboration. With NVIDIA RTX Read article >


 How to integrate the NVIDIA GPU and Network Operators
How to integrate the NVIDIA GPU and Network Operators