
 NVIDIA Decision Support (NDS) is our adaptation of an industry-standard data science benchmark often used in the Apache Spark community. NDS consists of the same 105 SQL queries as the industry standard benchmark TPC-DS, but has modified parts for dataset generation and execution scripts.
NVIDIA Decision Support (NDS) is our adaptation of an industry-standard data science benchmark often used in the Apache Spark community. NDS consists of the same 105 SQL queries as the industry standard benchmark TPC-DS, but has modified parts for dataset generation and execution scripts.
Introduction
The August release (21.08) of RAPIDS Accelerator for Apache Spark is now available. It has been a little over a year since the first release at NVIDIA GTC 2020. We have improved in so many ways, particularly in terms of ease-of-use with minimal to no-code change for Apache Spark applications. This last year, the team has been focused on adding both functionality and continuously improving performance. As a testament to that, we periodically measure performance and functionality over time with the NVIDIA Data Science (NDS) benchmark at a scale factor of 3,000 (3 TB uncompressed). In this release, apart from adding new features, we are extremely proud to make progress on improving end-to-end speed for all passing queries and lowering the total cost of ownership for NVIDIA EGX servers.
Benchmark updates
NVIDIA Decision Support (NDS) is our adaptation of an industry-standard data science benchmark often used in the Apache Spark community. NDS consists of the same 105 SQL queries as the industry standard benchmark TPC-DS, but has modified parts for dataset generation and execution scripts. In our GTC 2021 update, we had 95 queries passing. With the 21.08 release, with new features such as out-of-core group by, window rank, and dense_rank, we have enabled all of the 105 queries to run on the GPU.
Benchmark setup
- Scale Factor — 3K (3TB Dataset with floats)
- Systems: 4x NVIDIA Certified EGX Server
- EGX Server Hardware Spec: 4-node Dell R740xd, each with (2) 24-core CPUs, 512GB RAM, HDFS on NVMe, (1) CX-6 Dx 25/100Gb NIC, 2x NVIDIA A30 GPU
- CPU Hardware Spec: 4-node Dell R740xd, each with (2) 24-core CPUs, 512GB RAM, HDFS on NVMe, (1) CX-6 Dx 25/100Gb NIC
- Software: RAPIDS Accelerator v21.08.0, cuDF 21.08.0, Apache Spark 3.1.1, UCX 1.10.1
Results summary
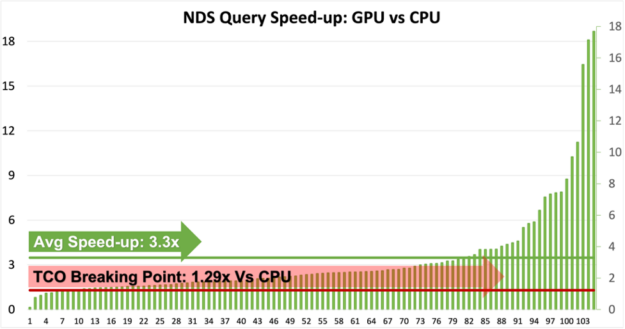
Based on this release, we are excited to show that all the 105 queries can now run without any code change on the GPU.
- The benchmark servers used for these benchmarks cost little under $170,000 for four servers without GPUs and $220,000 to include one NVIDIA A100 GPU in each server.
- In simple terms, benchmark GPU servers would cost 1.29 times CPU servers.
- As shown by the chart above (figure 1), more than 95 queries are now 1.29x faster and thereby cheaper to run on GPU.
- Some of the queries that are slower on GPU are currently being addressed and we are relentlessly working to improve those queries as well as improve the overall speed-ups.
- Users can easily deduce that GPU speed-up varies from 1x to 18x and therefore it’s suggested that users qualify the right use cases for GPUs.
- The Qualification Tool would be a handy asset if users are unsure about the right use case for GPU. For more information about the Qualification Tool, refer to the section below.
Profiling & qualification tool
The Profiling & Qualification tool, released in 21.06, saw positive feedback from the user community as well as requests for new features. In 21.08 the qualification tool now has the ability to handle event logs generated by Apache Spark 2.x versions. The tool will also support event logs generated by AWS EMR 6.3.0, Google Dataproc 2.0, Microsoft Azure Synapse, and the Databricks 7.3 and 8.2 runtimes. The qualification tool will no longer require a Spark runtime. Users can now use the qualification tool with just Apache Spark 3.x jars on their machine. The latest version also has new filtering capabilities to choose event logs. The tool also looks for read data formats and types that the plugin doesn’t support and removes these from the score (based on the total task time in SQL Dataframe operations). The output will be reported in a concise format on the terminal and a detailed analysis of each of the processed event logs will be stored as a csv output.
New functionality
This release adds more functionality for arrays and structs. We can now do a union on multi-level struct data types and can also write array data types in Parquet format. We have added rank and dense_rank window functions to the existing lead, lag and row_number functionality. With this added functionality, the RAPIDS Accelerator can now support the most commonly used window operators in SQL. For the timestamp operators, we have added support for LEGACY timestamps. With this functionality, users can read legacy timestamp formats supported in Spark 2.0. For Databricks users, we have added the ability to cache data in GPU (this was already supported for all other platforms).
We continue to make the user experience better with the ability to handle datasets that spill out of GPU memory for group by and windowing operations. This improvement will save users time creating partitions to avoid out-of-memory errors on the GPU. Similarly, the adoption of UCX 1.11 has improved error handling for RAPIDS Spark Accelerated Shuffle Manager.
Growing community
Join us for “Accelerate Data Pipelines with NVIDIA RAPIDS Accelerator for Spark” to learn how Informatica is removing the barrier to using GPUs, unlocking dramatic performance improvements in operationalizing machine learning projects at scale. You can read more about this online seminar and register here.
Coming Soon
As we noted in the last release, we moved to CalVer and a bi-monthly release cadence since the last release (21.06). The upcoming versions will add expanded support for additional decimal types and continue to add more nested data type support for multi-level struct and maps. In addition, lookout for micro-benchmarks with code-samples and notebooks that will highlight operations best suited for GPUs. We want to hear from you, the users. Reach out to us on GitHub and let us know how we can continue to improve your experience using RAPIDS Spark.