Posted by Aditya Gupta, Software Engineer and Shyam Upadhyay, Research Scientist, Google Assistant
A key challenge in natural language processing (NLP) is building conversational agents that can understand and reason about different language phenomena that are unique to realistic speech. For example, because people do not always premeditate exactly what they are going to say, a natural conversation often includes interruptions to speech, called disfluencies. Such disfluencies can be simple (like interjections, repetitions, restarts, or corrections), which simply break the continuity of a sentence, or more complex semantic disfluencies, in which the underlying meaning of a phrase changes. In addition, understanding a conversation also often requires knowledge of temporal relationships, like whether an event precedes or follows another. However, conversational agents built on today’s NLP models often struggle when confronted with temporal relationships or with disfluencies, and progress on improving their performance has been slow. This is due, in part, to a lack of datasets that involve such interesting conversational and speech phenomena.
To stir interest in this direction within the research community, we are excited to introduce TimeDial, for temporal commonsense reasoning in dialog, and Disfl-QA, which focuses on contextual disfluencies. TimeDial presents a new multiple choice span filling task targeted for temporal understanding, with an annotated test set of over ~1.1k dialogs. Disfl-QA is the first dataset containing contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages, with ~12k human annotated disfluent questions. These benchmark datasets are the first of their kind and show a significant gap between human performance and current state of the art NLP models.
TimeDial
While people can effortlessly reason about everyday temporal concepts, such as duration, frequency, or relative ordering of events in a dialog, such tasks can be challenging for conversational agents. For example, current NLP models often make a poor selection when tasked with filling in a blank (as shown below) that assumes a basic level of world knowledge for reasoning, or that requires understanding explicit and implicit inter-dependencies between temporal concepts across conversational turns.
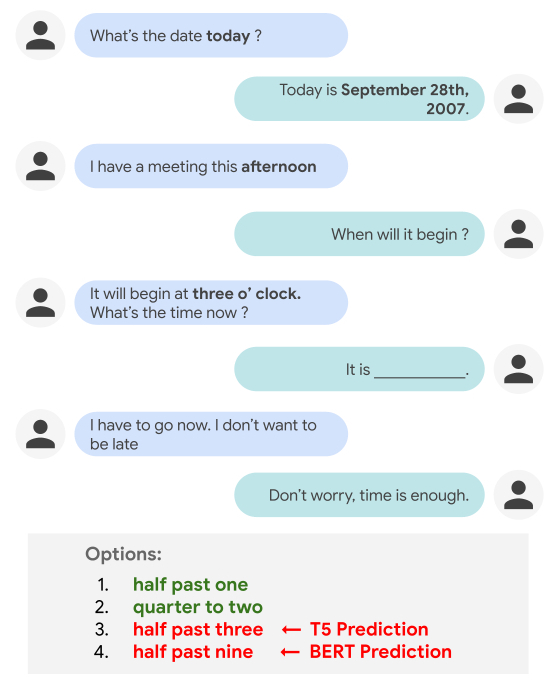
It is easy for a person to judge that “half past one” and “quarter to two” are more plausible options to fill in the blank than “half past three” and “half past nine”. However, performing such temporal reasoning in the context of a dialog is not trivial for NLP models, as it requires appealing to world knowledge (i.e., knowing that the participants are not yet late for the meeting) and understanding the temporal relationship between events (“half past one” is before “three o’clock”, while “half past three” is after it). Indeed, current state-of-the-art models like T5 and BERT end up picking the wrong answers — “half past three” (T5) and “half past nine” (BERT).
The TimeDial benchmark dataset (derived from the DailyDialog multi-turn dialog corpus) measures models’ temporal commonsense reasoning abilities within a dialog context. Each of the ~1.5k dialogs in the dataset is presented in a multiple choice setup, in which one temporal span is masked out and the model is asked to find all correct answers from a list of four options to fill in the blank.
In our experiments we found that while people can easily answer these multiple choice questions (at 97.8% accuracy), state-of-the-art pre-trained language models still struggle on this challenge set. We experiment across three different modeling paradigms: (i) classification over the provided 4 options using BERT, (ii) mask filling for the masked span in the dialog using BERT-MLM, (iii) generative methods using T5. We observe that all the models struggle on this challenge set, with the best variant only scoring 73%.
| Model |
|
2-best Accuracy |
| Human |
|
97.8% |
| BERT – Classification |
|
50.0% |
| BERT – Mask Filling |
|
68.5% |
| T5 – Generation |
|
73.0% |
Qualitative error analyses show that the pre-trained language models often rely on shallow, spurious features (particularly text matching), instead of truly doing reasoning over the context. It is likely that building NLP models capable of performing the kind of temporal commonsense reasoning needed for TimeDial requires rethinking how temporal objects are represented within general text representations.
Disfl-QA
As disfluency is inherently a speech phenomenon, it is most commonly found in text output from speech recognition systems. Understanding such disfluent text is key to building conversational agents that understand human speech. Unfortunately, research in the NLP and speech community has been impeded by the lack of curated datasets containing such disfluencies, and the datasets that are available, like Switchboard, are limited in scale and complexity. As a result, it’s difficult to stress test NLP models in the presence of disfluencies.
| Disfluency |
|
Example |
| Interjection |
|
“When is, uh, Easter this year?” |
| Repetition |
|
“When is Eas … Easter this year?” |
| Correction |
|
“When is Lent, I mean Easter, this year?” |
| Restart |
|
“How much, no wait, when is Easter this year?” |
| Different kinds of disfluencies. The reparandum (words intended to be corrected or ignored; in red), interregnum (optional discourse cues; in grey) and repair (the corrected words; in blue). |
Disfl-QA is the first dataset containing contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages from SQuAD. Disfl-QA is a targeted dataset for disfluencies, in which all questions (~12k) contain disfluencies, making for a much larger disfluent test set than prior datasets. Over 90% of the disfluencies in Disfl-QA are corrections or restarts, making it a much more difficult test set for disfluency correction. In addition, compared to earlier disfluency datasets, it contains a wider variety of semantic distractors, i.e., distractors that carry semantic meaning as opposed to simpler speech disfluencies.
| Passage: …The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (“Norman” comes from “Norseman”) raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, … |
|
| Q1: |
In what country is Normandy located? |
|
France ✓ |
| DQ1: |
In what country is Norse found no wait Normandy not Norse? |
|
Denmark X |
| Q2: |
When were the Normans in Normandy? |
|
10th and 11th centuries ✓ |
| DQ2: |
From which countries no tell me when were the Normans in Normandy? |
|
Denmark, Iceland and Norway X |
| A passage and questions (Qi) from SQuAD dataset, along with their disfluent versions (DQi), consisting of semantic distractors (like “Norse” and “from which countries”) and predictions from a T5 model. |
Here, the first question (Q1) is seeking an answer about the location of Normandy. In the disfluent version (DQ1) Norse is mentioned before the question is corrected. The presence of this correctional disfluency confuses the QA model, which tends to rely on shallow textual cues from the question for making predictions.
Disfl-QA also includes newer phenomena, such as coreference (expression referring to the same entity) between the reparandum and the repair.
| SQuAD |
|
Disfl-QA |
| Who does BSkyB have an operating license from? |
|
Who removed [BSkyB’s] operating license, no scratch that, who do [they] have [their] operating license from? |
Experiments show that the performance of existing state-of-the-art language model–based question answering systems degrades significantly when tested on Disfl-QA and heuristic disfluencies (presented in the paper) in a zero-shot setting.
| Dataset |
|
F1 |
| SQuAD |
|
89.59 |
| Heuristics |
|
65.27 (-24.32) |
| Disfl-QA |
|
61.64 (-27.95) |
We show that data augmentation methods partially recover the loss in performance and also demonstrate the efficacy of using human-annotated training data for fine-tuning. We argue that researchers need large-scale disfluency datasets in order for NLP models to be robust to disfluencies.
Conclusion
Understanding language phenomena that are unique to human speech, like disfluencies and temporal reasoning, among others, is a key ingredient for enabling more natural human–machine communication in the near future. With TimeDial and Disfl-QA, we aim to fill a major research gap by providing these datasets as testbeds for NLP models, in order to evaluate their robustness to ubiquitous phenomena across different tasks. It is our hope that the broader NLP community will devise generalized few-shot or zero-shot approaches to effectively handle these phenomena, without requiring task-specific human-annotated training datasets, constructed specifically for these challenges.
Acknowledgments
The TimeDial work has been a team effort involving Lianhui Qi, Luheng He, Yenjin Choi, Manaal Faruqui and the authors. The Disfl-QA work has been a collaboration involving Jiacheng Xu, Diyi Yang, Manaal Faruqui.


 New research creates a deployable AI framework for detecting gravitational waves within massive amounts of data at several magnitudes faster than real time.
New research creates a deployable AI framework for detecting gravitational waves within massive amounts of data at several magnitudes faster than real time. 


 Machine Learning (ML) is increasingly used to make decisions across many domains like healthcare, education, and financial services. Since ML models are being used in situations that have a real impact on people, it is critical to understand what features are being considered for the decisions to eliminate or minimize the impact of biases. Model …
Machine Learning (ML) is increasingly used to make decisions across many domains like healthcare, education, and financial services. Since ML models are being used in situations that have a real impact on people, it is critical to understand what features are being considered for the decisions to eliminate or minimize the impact of biases. Model … 
 Ray Tracing Games II is now available to download for free via Apress and Amazon. This Open Access book is a must-have for anyone interested in real-time rendering. Ray tracing is the holy grail of gaming graphics, simulating the physical behavior of light to bring real-time, cinematic-quality rendering to even the most visually intense games.
Ray Tracing Games II is now available to download for free via Apress and Amazon. This Open Access book is a must-have for anyone interested in real-time rendering. Ray tracing is the holy grail of gaming graphics, simulating the physical behavior of light to bring real-time, cinematic-quality rendering to even the most visually intense games. A new generation of AI applications at the edge is driving incredible operational efficiency and safety gains across a broad range of spaces. Read how the power of AI and edge computing is critical to building smarter and safer spaces.
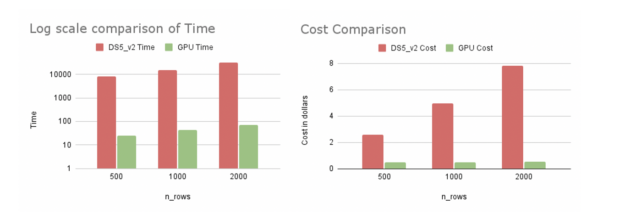
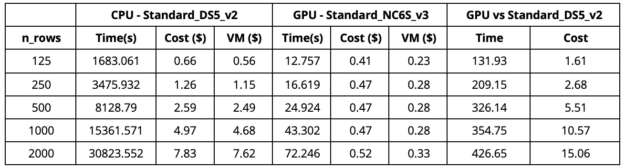
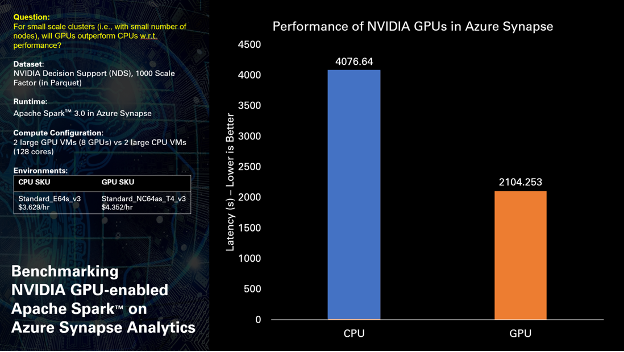
A new generation of AI applications at the edge is driving incredible operational efficiency and safety gains across a broad range of spaces. Read how the power of AI and edge computing is critical to building smarter and safer spaces. Azure recently announced support for NVIDIA’s T4 Tensor Core Graphics Processing Units (GPUs) which are optimized for deploying machine learning inferencing or analytical workloads in a cost-effective manner. With Apache Spark™ deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data …
Azure recently announced support for NVIDIA’s T4 Tensor Core Graphics Processing Units (GPUs) which are optimized for deploying machine learning inferencing or analytical workloads in a cost-effective manner. With Apache Spark™ deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data …  deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data processing and machine learning tasks. With built-in support for RAPIDS acceleration, the Azure Synapse version of GPU-accelerated Spark offers at least 2x performance gain on standard analytical benchmarks compared to running on CPUs, all without any code changes.
deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data processing and machine learning tasks. With built-in support for RAPIDS acceleration, the Azure Synapse version of GPU-accelerated Spark offers at least 2x performance gain on standard analytical benchmarks compared to running on CPUs, all without any code changes.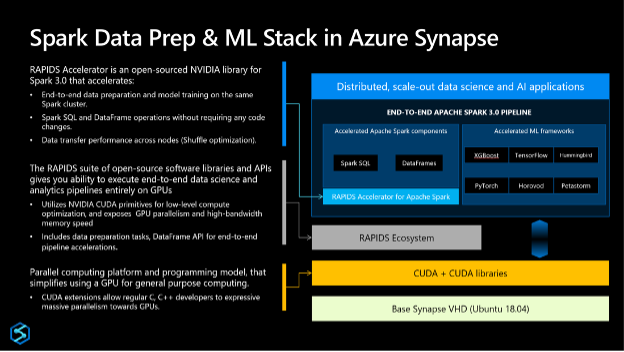
{kind=link}