Computer vision and edge AI are looking beyond the pasture. Plainsight, a San Francisco-based startup and NVIDIA Metropolis partner, is helping the meat processing industry improve its operations — from farms to forks. By pairing Plainsight’s vision AI platform and NVIDIA GPUs to develop video analytics applications, the company’s system performs precision livestock counting and Read article >
As an undergraduate student excited about AI for healthcare applications, I was thrilled to be joining the NVIDIA Clara Deploy team for an internship. It was the perfect combination: the opportunity to work at a leading technology company enabling the acceleration and adoption of AI while contributing to a team building the future (and the … Continued
As an undergraduate student excited about AI for healthcare applications, I was thrilled to be joining the NVIDIA Clara Deploy team for an internship. It was the perfect combination: the opportunity to work at a leading technology company enabling the acceleration and adoption of AI while contributing to a team building the future (and the present!) of AI deployment for healthcare. The next few months were filled with learning from brilliant yet humble colleagues, picking up new skills like CUDA programming, and the opportunity to focus on unique technical challenges posed by histopathology data.
What is Clara Deploy?
The Clara Deploy SDK is a container-based, cloud-native development and deployment framework for multi-AI and multidomain workflows in smart hospitals. It enables you to define container-based pipelines consisting of multiple stages, each stage defined by an operator. A pipeline consists of multiple operators and is a directed acyclic graph (DAG) from the data source to the data sink. Each operator is a step of the pipeline, such as loading input, preprocessing, AI inference, and so on.
As I explored setting up the NVIDIA Clara Deploy platform and running AI inference pipelines, I gained firsthand experience in the challenges of deploying AI workflows, particularly in standardizing workflows and scaling up execution. While running digital pathology pipelines, I gained awareness of the performance bottleneck of I/O and preprocessing steps that are usually not GPU-accelerated. This influenced my choice to focus on accelerating preprocessing filters for digital pathology during my internship.
What is cuCIM?
cuCIM is a RAPIDS library for accelerated n-dimensional image processing and image I/O, with a focus on medical imaging applications. cuCIM consists of I/O, file system, and operation modules. Operations in cuCIM can be extended using a plug-in architecture. cuCIM is uniquely positioned to be a leading library for medical image-processing applications, and I am excited to have gained exposure to and contributed to it during my time at NVIDIA.
Project motivation
A significant challenge in the digitization of histopathology analysis is the stain variation observed in pathology images. These images can have large variations in staining caused by multiple factors, including stain vendors, storage conditions, staining protocols, digital scanners, and so on.
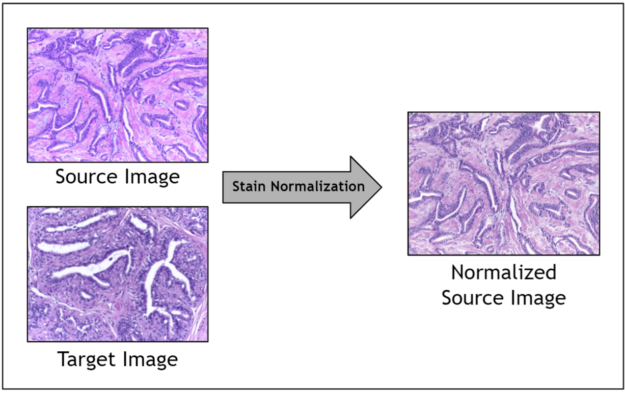
Given the range of factors, it is impractical to control for staining variation during image acquisition. Instead, an image preprocessing step called stain normalization is often used to algorithmically standardize image staining. A stain normalization filter accepts as input a source image and a target image. The source image is to be stain normalized, and the target image contains the ideal stain, to be transferred to the source image. Ultimately, a normalized source image is returned as output.
Figure 1. Stain normalization filter. Images from StainTools.
Prior work has shown that stain normalization used as a preprocessing step in digital pathology AI pipelines can shorten training time, improve accuracy, and enable data from different sources to be used together. Because you are operating in a relatively small data regime due to the scarcity of stained pathology images, stain normalization enables you to optimize the signal obtained amidst noisy stain variations.
However, prior implementations of stain normalization were relatively slow as they were not GPU-accelerated. There was an opportunity to implement a GPU-accelerated stain normalization algorithm and enable fast and effective preprocessing for digital pathology AI pipelines.
Accelerating stain normalization for digital pathology
Stain normalization methods fall into three broad categories:
I chose to focus on stain deconvolution-based methods, as prior literature showed greater performance compared to global color normalization and better theoretical guarantees regarding the maintenance of biological structure integrity compared to deep network-based methods.
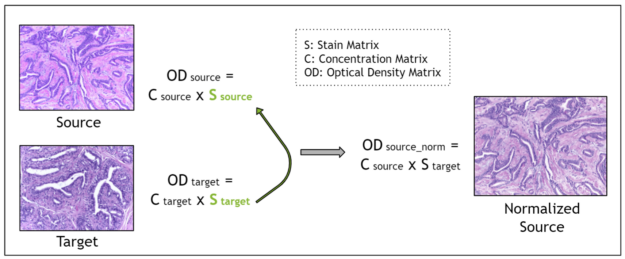
Stain deconvolution-based methods assume that each image is characterized by a stain matrix, which contains the red, green, blue (RGB) values for each of the two stains in H&E stained images: hematoxylin and eosin.
Using the Beer-Lambert law, an RGB image is transformed into an optical density image. Then, the optical density image may be related to the product of a pixel concentration matrix and the stain matrix for that image. The pixel concentration matrix indicates the concentration of each stain for each pixel. If the stain matrix is estimated, done here with the Macenko method, then the concentration matrix may be obtained.
Finally, for stain normalization, the stain matrix of a source image is replaced with the stain matrix of a target image. This serves the purpose of transferring the stain profile from the target image to the source image. Because the concentration matrix of the source image is unchanged, the morphology of the biological structures is maintained. The Macenko method for estimating the stain matrix is an unsupervised method using the singular value decomposition.
I designed and implemented a filter for the Macenko method for stain normalization in CuPy, after modifying an existing version in NumPy. Next, I compared the performance of the two.
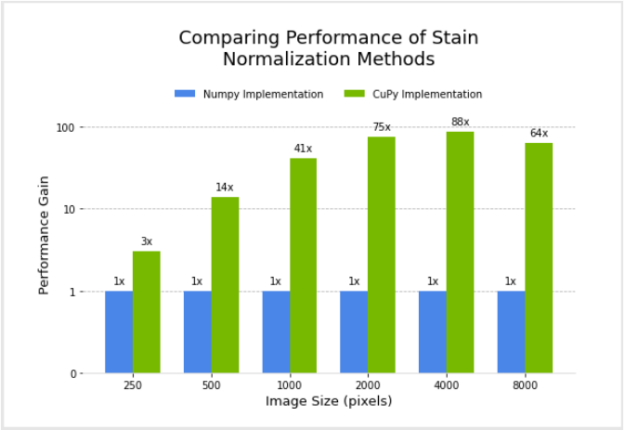
Figure 3 shows the relative performance of the NumPy and CuPy implementations of stain normalization for different image sizes, using an NVIDIA DGX-1. Performance for the CuPy implementation is plotted in terms of acceleration factor relative to the NumPy implementation.
Figure 3. Performance comparison of NumPy vs. CuPy implementations of stain normalization
Given the goal of enabling GPU-accelerated stain normalization to be used as a preprocessing step for digital pathology pipelines, I began the integration of this filter as a transform (array-based and dictionary-based) into MONAI. MONAI is an open-source, PyTorch-based framework for deep learning in medical imaging. After being fully integrated, the stain normalization transform can be added to pathology pipelines in Clara Train or MONAI.
Acceleration of color conversion filter
Next, I worked on implementing the color conversion rgb2hed function in CUDA C++, which is a commonly used function available in scikit-image and the cuCIM Python layer, among other libraries. Color space conversion from RGB to HED is closely related to stain normalization, as this function involves obtaining stain concentration values, assuming that the stain vectors are a constant, precalculated approximation. This ignores variations between the staining of different images. This function is to be integrated into cuCIM through a C++ based operator plugin mechanism.
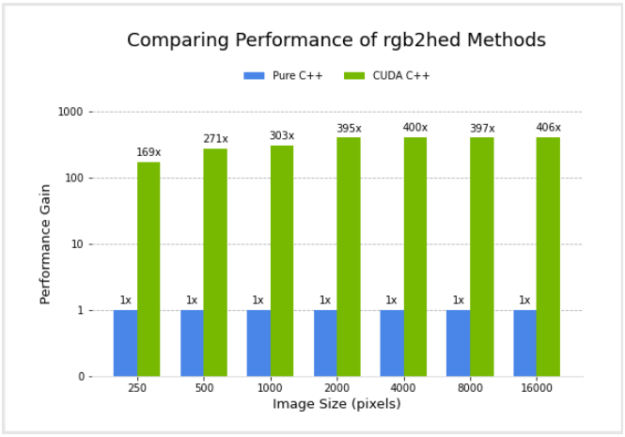
I compared the performance of a pure C++ implementation and the CUDA C++ implementation. Figure 4 shows the relative performance of the two versions, for different image sizes, using an NVIDIA GV100 GPU and Intel(R) Core(TM) i7-7800X CPU. Performance for the CUDA C++ implementation is plotted in terms of acceleration factor relative to the pure C++ implementation.
It’s important to note that the performance gains do not account for any transfer of data to and from the GPU. I did this because I am considering the common scenario where data transfers are minimized by remaining on the GPU for several subsequent operations in an image processing workflow, with transfer back to the host occurring only at the end.
Figure 4. Performance comparison of pure C++ vs. CUDA C++ implementations of the rgb2hed color conversion function
Conclusion
In summary, my internship project was focused on accelerating color conversion filters for digital pathology. Specifically, I worked on designing and implementing the Macenko stain normalization method, using CuPy for GPU-acceleration. I began the integration of this into MONAI as a transform, for future use as a preprocessing step for digital pathology pipelines. Next, I worked on implementing the color conversion rgb2hed function in CUDA C++, to be integrated into cuCIM through a C++ based operator plugin mechanism.
Both the CuPy implementation of Macenko stain normalization and the CUDA C++ implementation of the rgb2hed function showed significant performance gains compared to the NumPy version and pure C++ version, respectively. The stain normalization preprocessing time for training a pipeline over 500 epochs with a dataset of 250 images and image size of 4000 by 4000 pixels is roughly estimated at 13 days with the NumPy-based filter. It decreases to 3.5 hours for the CuPy-based filter.
Ultimately, accelerating pre– and post-processing filters for digital pathology can improve the performance of deep learning pipelines in digital pathology, expedite the adoption of digital pathology, and enable AI to revolutionize pathology.
I am using a jupyter notebook to load data and train a CNN. I have about 80,000 images and each time I try to load the data, the VS code instance crashes. I was wondering if I could load the first 20,000 images (since I know that will work) and train the network, then delete those images and load the next 20,000 and start training again and so on until I use all my images. From my understanding, as long as I do not reset the kernel (of the notebook) I should be fine. Please help/give suggestions on how to avoid/fix this issue.
Archaeologist Daria Dabal is bringing the past to life, with an assist from NVIDIA technology. Dabal works on various archaeological sites in the U.K., conducting field and post-excavation work. Over the last five years, photogrammetry — the use of photographs to create fully textured 3D models — has become increasingly popular in archaeology. Dabal has Read article >
Your Amazon Prime delivery just got smarter. Autonomous trucking company Plus recently signed a deal with Amazon to provide at least 1,000 self-driving systems to retrofit on the e-commerce giant’s delivery fleet. These systems are powered by NVIDIA DRIVE Xavier for high-performance, energy-efficient and centralized AI compute. The agreement follows Plus’ announcement of going public Read article >
Posted by Yossi Matias, Vice President and Ehud Rivlin, Research Scientist, Google Research
With the increasing ability to consistently and accurately process large amounts of data, particularly visual data, computer-aided diagnostic systems are more frequently being used to assist physicians in their work. This, in turn, can lead to meaningful improvements in health care. An example of where this could be especially useful is in the diagnosis and treatment of colorectal cancer (CRC), which is especially deadly and results in over 900K deaths per year, globally. CRC originates in small pre-cancerous lesions in the colon, called polyps, the identification and removal of which is very successful in preventing CRC-related deaths.
The standard procedure used by gastroenterologists (GIs) to detect and remove polyps is the colonoscopy, and about 19 million such procedures are performed annually in the US alone. During a colonoscopy, the gastroenterologist uses a camera-containing probe to check the intestine for pre-cancerous polyps and early signs of cancer, and removes tissue that looks worrisome. However, complicating factors, such as incomplete detection (in which the polyp appears within the field of view, but is missed by the GI, perhaps due to its size or shape) and incomplete exploration (in which the polyp does not appear in the camera’s field of view), can lead to a high fraction of missed polyps. In fact, studies suggest that 22%–28% of polyps are missed during colonoscopies, of which 20%–24% have the potential to become cancerous (adenomas).
Today, we are sharing progress made in using machine learning (ML) to help GIs fight colorectal cancer by making colonoscopies more effective. In “Detection of Elusive Polyps via a Large Scale AI System”, we present an ML model designed to combat the problem of incomplete detection by helping the GI detect polyps that are within the field of view. This work adds to our previously published work that maximizes the coverage of the colon during the colonoscopy by flagging for GI follow-up areas that may have been missed. Using clinical studies, we show that these systems significantly improve polyp detection rates.
Incomplete Exploration To help the GI detect polyps that are outside the field of view, we previously developed an ML system that reduces the rate of incomplete exploration by estimating the fractions of covered and non-covered regions of a colon during a colonoscopy. This earlier work uses computer vision and geometry in a technique we call colonoscopy coverage deficiency via depth, to compute segment-by-segment coverage for the colon. It does so in two phases: first computing depth maps for each frame of the colonoscopy video, and then using these depth maps to compute the coverage in real time.
The ML system computes a depth image (middle) from a single RGB image (left). Then, based on the computation of depth images for a video sequence, it calculates local coverage (right), and detects where the coverage has been deficient and a second look is required (blue color indicates observed segments where red indicates uncovered ones). You can learn more about this work in our previous blog post.
This segment-by-segment work yields the ability to estimate what fraction of the current segment has been covered. The helpfulness of such functionality is clear: during the procedure itself, a physician may be alerted to segments with deficient coverage, and can immediately return to review these areas, potentially reducing the rates of missed polyps due to incomplete exploration.
Incomplete Detection In our most recent paper, we look into the problem of incomplete detection. We describe an ML model that aids a GI in detecting polyps that are within the field of view, so as to reduce the rate of incomplete detection. We developed a system that is based on convolutional neural networks (CNN) with an architecture that combines temporal logic with a single frame detector, resulting in more accurate detection.
This new system has two principal advantages. The first is that the system improves detection performance by reducing the number of false negatives detections of elusive polyps, those polyps that are particularly difficult for GIs to detect. The second advantage is the very low false positive rate of the system. This low false positive rate makes these systems more likely to be adopted in the clinic.
Examples of the variety of polyps detected by the ML system.
We trained the system on 3600 procedures (86M video frames) and tested it on 1400 procedures (33M frames). All the videos and metadata were de-identified. The system detected 97% of the polyps (i.e., it yielded 97% sensitivity) at 4.6 false alarms per procedure, which is a substantial improvement over previously published results. Of the false alarms, follow-up review showed that some were, in fact, valid polyp detections, indicating that the system was able to detect polyps that were missed by the performing endoscopist and by those who annotated the data. The performance of the system on these elusive polyps suggests its generalizability in that the system has learned to detect examples that were initially missed by all who viewed the procedure.
We evaluated the system performance on polyps that are in the field of view for less than five seconds, which makes them more difficult for the GI to detect, and for which models typically have much lower sensitivity. In this case the system attained a sensitivity that is about three times that of the sensitivity that the original procedure achieved. When the polyps were present in the field of view for less than 2 seconds, the difference was even more stark — the system exhibited a 4x improvement in sensitivity.
It is also interesting to note that the system is fairly insensitive to the choice of neural network architecture. We used two architectures: RetinaNet and LSTM-SSD. RetinaNet is a leading technique for object detection on static images (used for video by applying it to frames in a consecutive fashion). It is one of the top performers on a variety of benchmarks, given a fixed computational budget, and is known for balancing speed of computation with accuracy. LSTM-SSD is a true video object detection architecture, which can explicitly account for the temporal character of the video (e.g., temporal consistency of detections, ability to deal with blur and fast motion, etc.). It is known for being robust and very computationally lightweight and can therefore run on less expensive processors. Comparable results were also obtained on the much heavier Faster R-CNN architecture. The fact that results are similar across different architectures implies that one can choose the network meeting the available hardware specifications.
Prospective Clinical Research Study As part of the research reported in our detection paper we ran a clinical validation on 100 procedures in collaboration with Shaare Zedek Medical Center in Jerusalem, where our system was used in real time to help GIs. The system helped detect an average of one polyp per procedure that would have otherwise been missed by the GI performing the procedure, while not missing any of the polyps detected by the GIs, and with 3.8 false alarms per procedure. The feedback from the GIs was consistently positive.
We are encouraged by the potential helpfulness of this system for improving polyp detection, and we look forward to working together with the doctors in the procedure room to further validate this research.
Acknowledgements The research was conducted by teams from Google Health and Google Research, Israel with support from Verily Life Sciences, and in collaboration with Shaare Zedek Medical Center. Verily is advancing this research via a newly established center in Israel, led by Ehud Rivlin. This research was conducted by Danny Veikherman, Tomer Golany, Dan M. Livovsky, Amit Aides, Valentin Dashinsky, Nadav Rabani, David Ben Shimol, Yochai Blau, Liran Katzir, Ilan Shimshoni, Yun Liu, Ori Segol, Eran Goldin, Greg Corrado, Jesse Lachter, Yossi Matias, Ehud Rivlin, and Daniel Freedman. Our appreciation also goes to several institutions and GIs who provided advice along the way and tested our system prototype. We would like to thank all of our team members and collaborators who worked on this project with us, including: Chen Barshai, Nia Stoykova, and many others.
It’s a new month for GFN Thursday, which means a new month full of games on GeForce NOW. August brings a wealth of great new PC game launches to the cloud gaming service, including King’s Bounty II, Humankind and NARAKA: BLADEPOINT. In total, 13 titles are available to stream this week. They’re just a portion Read article >
I’m a novice on ML and mobile development topics, and I’d like to practice and make a basic app which could recognize a class of objects (animals, food, anything with freely available dataset) and returns information of said object.
I see dozens of articles and public repositories on implementing image recognition on mobile, mostly using Tensorflow, and I’ve found a lot of image datasets on Kaggle to train on.
Now I’m confused on how to actually start. I was thinking of using React Native since I’m a bit more experienced with Javascript and using npm packages, but a lot of articles say to just go native for better performance. I don’t know if what I’m doing would be considered “heavy” so I’m a bit confused here.
CFO Commentary to Be Provided in Writing Ahead of CallSANTA CLARA, Calif., Aug. 04, 2021 (GLOBE NEWSWIRE) — NVIDIA will host a conference call on Wednesday, August 18, at 2 p.m. PT (5 p.m. …

 As an undergraduate student excited about AI for healthcare applications, I was thrilled to be joining the NVIDIA Clara Deploy team for an internship. It was the perfect combination: the opportunity to work at a leading technology company enabling the acceleration and adoption of AI while contributing to a team building the future (and the …
As an undergraduate student excited about AI for healthcare applications, I was thrilled to be joining the NVIDIA Clara Deploy team for an internship. It was the perfect combination: the opportunity to work at a leading technology company enabling the acceleration and adoption of AI while contributing to a team building the future (and the …