
|
submitted by /u/TuxThePenguin [visit reddit] [comments] |

 DataBloom
DataBloom
|
|
submitted by /u/TuxThePenguin [visit reddit] [comments] |
NVIDIA today officially launched Cambridge-1, the United Kingdom’s most powerful supercomputer, which will enable top scientists and healthcare experts to use the…
 The NVIDIA Nsight Perf SDK is a graphics profiling toolbox for DirectX, Vulkan, and OpenGL, enabling you to collect GPU performance metrics directly from your application.
The NVIDIA Nsight Perf SDK is a graphics profiling toolbox for DirectX, Vulkan, and OpenGL, enabling you to collect GPU performance metrics directly from your application.
The Nsight Perf SDK v2021.1 public release is now available for download.
New features include:
New: Ray Tracing Samples
Below is a screenshot of Microsoft’s Real Time Denoised Ambient Occlusion sample, containing Nsight Perf SDK instrumentation. Each render pass or phase of execution has been annotated to take a measurement.

From the DispatchRay call’s HTML report, the following tables show the shader’s pipeline utilization and latency reasons. Quickly spot the most utilized pipelines via the bar charts, and inspect the exact numbers of operations performed.
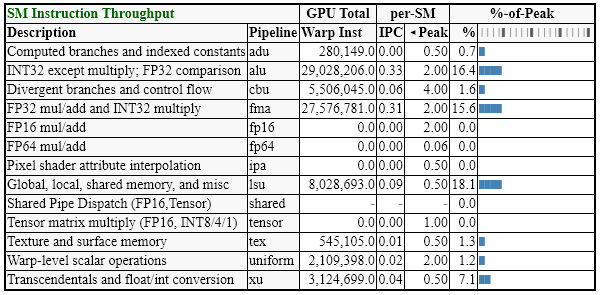
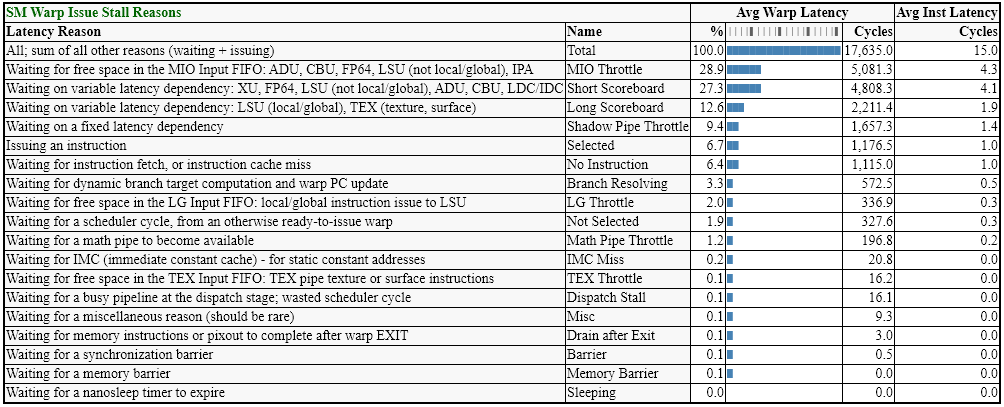
This sample is bundled with the Nsight Perf SDK, which you can download from the product page. To try this out yourself, simply open the sample’s solution file in Visual Studio, build, and run. Step-by-step instructions are included in the Getting Started Guide. If you have any questions, don’t hesitate to reach out via the Nsight Perf Forum.
For more details on the Nsight Perf SDK, check out the product page.
We want to hear from you! If you have any questions or suggestions, feel free to post them in the Nsight Perf Forum.
 NVIDIA released the NVIDIA DOCA 1.1 software framework for NVIDIA BlueField DPUs, the world’s most advanced Data Processing Unit (DPU).
NVIDIA released the NVIDIA DOCA 1.1 software framework for NVIDIA BlueField DPUs, the world’s most advanced Data Processing Unit (DPU).
Today NVIDIA released the NVIDIA DOCA 1.1 software framework for NVIDIA BlueField DPUs, the world’s most advanced Data Processing Unit (DPU). This latest release aims to continue the momentum of the DOCA early access program with additional DOCA SDK, Runtime, and Services to enable developers to accelerate the development of applications on the DPU.
DPUs are increasingly useful for offloading, accelerating, and isolating networking functions and virtualized resources. Modern workload demands that impose too much networking overhead on the CPU cores provide tremendous motivation to adopt DPUs in every host. DPUs can handle all this virtualization (Open vSwitch (OVS), SR-IOV, RDMA) faster and more efficiently than standard CPUs. In addition, DPUs provide the benefit of security and operational isolation by running separately from the main CPU. The DPU can detect and block malicious behavior without requiring involvement from the CPU or host operating system.
DOCA is the key to unlocking the potential of the DPU. DOCA enables application developers and NVIDIA technology partners to accelerate delivery of services running on the DPU residing in every data center node. The DPU creates an isolated and secure services domain for networking, security, storage, and infrastructure management.
The DOCA 1.1 release builds on the momentum of DOCA 1.0 and includes the following updates:
According to a recently published whitepaper from Bob Wheeler, Principle Analyst at The Linley Group, “The FLOW-Gateway library implements a hardware accelerated gateway, building on the data path’s SFT. Compared with the DPDK’s generic flow API (rte_flow), the library provides higher-level abstraction for gateway applications that filter and distribute network traffic. Similarly, the Deep Packet Inspection (DPI) library combines SFT and RegEx acceleration, exposing a high-level API to the application layer. It enables unanchored searches of packet payloads against a compiled signature database.”
You can read more about DOCA in Wheeler’s whitepaper, “DPU-Based Hardware Acceleration: A software Perspective.”
What is in the DOCA Stack?
Below is a high-level view of the DOCA stack:
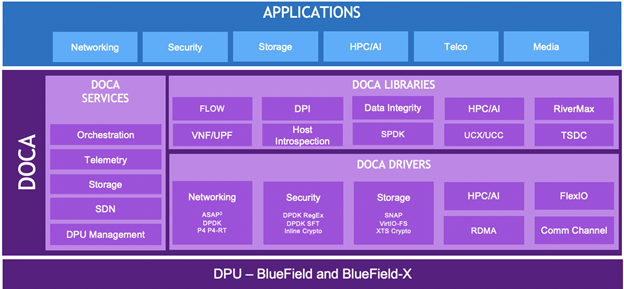
There are three main components of DOCA: drivers, libraries, and services. Each of these runs on the DPU – including BlueField and BlueField-X (a tightly coupled DPU-GPU converged solution). DOCA also includes reference applications available or being developed and deployed on the DPU, including Networking, Security, Storage, HPC/AI, Telco, and Media. All of these applications can be offloaded, accelerated, and Isolated from the CPU to dramatically improve performance and increase efficiency, enabling data center transformation into state-of-the-art virtual private clouds with public cloud scalability that are accelerated, fully programmable, and secure.
For a detailed description of each of the DOCA components, watch the recent GTC 21 session by Ami Badani and Ariel Kit of NVIDIA titled, “Program Data Center Infrastructure Acceleration with the Release of DOCA and the Latest DPU Software.”
Summary of DOCA Benefits
DOCA aids the developer journey to realize NVIDIA’s vision of an accelerated Data Center that includes the DPU as the third pillar in conjunction with the CPU and GPU. Through DOCA, NVIDIA is enabling access to all DPU features while also simplifying the creation of new applications or integrating existing applications on the DPU. DOCA offers several benefits as noted below:
Beyond the DOCA 1.1 release, NVIDIA will continue to add to the DOCA libraries, drivers, and services with application examples to enable application development for a wide range of Networking, Storage, Security, and Infrastructure Management use cases.
In addition, NVIDIA will continue to drive momentum with joint solutions from our ecosystem partners, the first of which will soon be announced. The ecosystem of DOCA/DPU partners and Early Access developers is growing rapidly, enabling customers access to best-in-class network, security, and storage solutions from industry leaders today.

Try DOCA Today
You can experience DOCA today with the BlueField DPU software package, which includes DOCA runtime accelerated libraries for networking, storage, and security. The libraries help you program your data center infrastructure running on the DPU.
The DOCA Early Access program is open now for submissions. To receive news and updates about DOCA or to become an early access member/partner, register on the DOCA page.
If you are interested in learning more about DOCA, please find several DOCA resources below:
DOCA product page
Early Access Registration page
DOCA Getting Started page (Requires registration)
NVIDIA DOCA Developer Forum
Bob Wheeler, The Linley Group whitepaper: DPU-Based Hardware Acceleration: A Software Perspective
DOCA On-Demand Session: Program Data Center Infrastructure Acceleration with the Release of DOCA and the Latest DPU Software
DOCA and BlueField DPU Developer Blog posts:
Sparklyr 1.7 delivers much-anticipated improvements, including R interfaces for image and binary data sources, several new spark_apply() capabilities, and better integration with sparklyr extensions.
Sparklyr 1.7 delivers much-anticipated improvements, including R interfaces for image and binary data sources, several new spark_apply() capabilities, and better integration with sparklyr extensions.
Hello everyone
So I have an object detection model in a flask app
https://github.com/fayez-als/obj-api/blob/main/app.py
The model receives an image and send the detected object back, I can’t figure out where to deploy it, aws ec2 serves it over http not https, heroku gives an error that the model is above 500mg.
Any suggestions are highly appreciated
submitted by /u/RepeatInfamous9988
[visit reddit] [comments]
Currently training a CNN on images that are 1024 x 768, these are scaled down to an input shape of 256, 192
Struggling to get the model accurate with real world predictions but can’t add much more complexity to the model without getting insufficient memory errors.
Tried using tf.keras.experimental.set_memory_growth to True without much improvement.
Does anyone have any tips to reduce the amount of Vram required or do I need to get a GPU with more Vram?
GPU: RTX 3070 8GB
Tensorflow: 2.5
CUDA: 11.2
submitted by /u/Cooperrrrr
[visit reddit] [comments]


|
submitted by /u/kschroeder97 [visit reddit] [comments] |
How to use a tf hub model inside a model built with the functional API?
submitted by /u/Aselvija
[visit reddit] [comments]