New NVIDIA Studio laptops from Dell, HP, Lenovo, Gigabyte, MSI and Razer were announced today as part of the record-breaking GeForce laptop launch. The new Studio laptops are powered by GeForce RTX 30 Series and NVIDIA RTX professional laptop GPUs, including designs with the new GeForce RTX 3050 Ti and 3050 laptop GPUs, and the Read article >
Yep, seems odd but I am unsure how to take it now.
A little bit of background: I have been participating in Deep Learning related competitions for a pretty long time. I am 25 right now, started in the field when I was 20. Started from Keras, then PyTorch then eventually chose Tensorflow because that gave me an edge with GPU parallelization and every firm around my region uses TF / helping me get a better job.
I dropped out of college, left my degree that majored in statistics and realised that AI was something that I could learn without spending a buck. It worked out pretty well. I eventually applied to a Speakers Giant ( can’t name ofc ) for the position of a data scientist and they gave it to me. Which was pretty fricking nuts given that I was doing research in NLP on a scale that was not professional.
That jump gave me hope in life that I won’t die as a dork with new cash. I eventually got a girlfriend. She was my colleague there, she left tho, to work at another firm 5 months ago.
The downfall started when I came across this ML challenge at a website called AIcrowd. I had participated and won a ton at Kaggle but this was new. I started making submissions and boom there it was. The ping noise. The sheer tension between me and time as I rushed to make more submissions. They were giving the participants like $10000+ for winning this thing and I was not even focused on that. Four days went away before I actually got out of my room, these were my stretches. Separating these sounds and making submissions felt like sex. I had never seen anything like this before.
I stopped answering my girlfriend’s texts initially, I would complete office assignments at night. I pretended to have a throat allergy to avoid office calls. We had been dating for a year and she had always hated my instinct to participate in these challenges which she looked down upon. She felt that I did them for the quick money, when I did it for the growth in my skills (Well Kaggle paid okayish, this AIcrowd’s prizes are nuts tho).
She called me a couple of days ago, asked me what would I do if she left due to my obsession. I told her that let me tighten up my ranking and then we could talk. Lol she broke up over text. F*ck.
I am still on top of the challenge’s leader board tho.
EDIT: Got it working, there were two bugs. First, I had mistakenly initialized batch_size twice during all my editing, and so I was mismatching between batch_size depending on where in the code I was. The second bug, which I still haven’t entirely fixed, is that if the batch size does not evenly divide the input generator the code fails, even though I have it set with a take amount that IS divisible by the batch_size. I get the same error even if I set steps per epoch to 1 (so it should never be reaching the end of the batches). I can only assume it’s an error during graph generation where it’s trying to define that last partial batch even though it will never be trained over. Hmm.
EDIT EDIT: Carefully following the size of my dataset throughout my pipeline, I discovered the source of the second issue, which is actually just that I didn’t delete my cache files when I previously had a larger take. The last thing I would still like to do is fix the code such that it actually CAN handle variable length batches so I don’t have to worry about making sure I don’t have partial batches. However, from what I can see, tf.unstack along variable length dimensions is straight up not supported, so this will require refactoring my computation to use some other method, like loops maybe. To be honest, though, it’s not worth my time to do so right now when I can just use drop_remainder = True and drop the last incomplete batch. In my real application there will be a lots of data per epoch, so losing 16 or so random examples from each epoch is rather minor.
So, I am making a project where I randomly crop images. In my data pipeline, I was trying to write code such that I could crop batches of my data at once, as the docs suggested that vectorizing my operations would reduce scheduling overhead.
However, I have run into some issues. If I use tf.image.random_crop, the problem is that the same random crop will be used on every image in the batch. I, however, want different random crops for every image. Moreover, since where I randomly crop an image will affect my labels, I need to track every random crop performed per image and adjust the label for that image.
I was able to write code that seems like it would work by using unstack, doing my operation per element, then restacking, like so:
images = tf.unstack( img, num=None, axis=0, name='unstack' ) xshifts = [] yshifts = [] newimages =[] for image in images: if not is_valid: x = np.random.randint(0, width - dx + 1) y = np.random.randint(0, height - dy + 1) else: x = 0 y = 0 newimages.append(image[ y:(y+dy), x:(x+dx), :]) print(image[ y:(y+dy), x:(x+dx), :]) xshifts.append((float(x) / img.shape[2]) * img_real_size) yshifts.append((float(y) / img.shape[1]) * img_real_size) images = tf.stack(newimages,0)
But oh no! Whenever I use this code in a map function, it doesn’t work because in unstack I set num=None, which requires it to infer how much to unstack from the actual batch size. But because tensorflow for reasons decided that batches should have size none when specifying things, the code fails because you can’t infer size from None. If I patch the code to put in num=batch_size, it changes my datasets output signature to be hard coded to batch_size, which seems like it shouldn’t be a problem, except this happens.
Which is to say, it’s failing because instead of receiving the expected batch input with the appropriate batch_size (2 for testing), it’s receiving a single input image, and 2 does not equal 1. The documentation strongly implied to me that if I batch my dataset before mapping (which I do), then the map function should be receiving the entire batch and should therefore be vectorized. But is this not the case? I double checked my batch and dataset sizes to make sure that it isn’t just an error arising due to some smaller final batch.
To sum up: I want to crop my images uniquely per image and alter labels as I do so. I also want to do this per batch, not just per image. The code I wrote that does this requires me to unstack my batch. But unstacking my batch can’t have num=None. But tensorflow batches have shape none, so the input of my method has shape none at specification. But if I change unstack’s num argument to anything but None, it changes my output specification to that number (which isn’t None), and the output signature of my method must ALSO have shape none at specification. How can I get around this?
Or, if someone can figure out why my batched dataset, batched before my map function, is apparently feeding in single samples instead of full batches, that would also solve the mystery.
I bought new macair M1 and was installing tensorflow on it, downloaded python3.8 using xcode-select-install but got error i between, “…arm64.whl” not supported, any help is appreciated.
‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work. This month we spotlight Marco Aldinucci, Full Professor at the University of Torino, Italy, whose research focuses on parallel programming models, language, and tools. Since March 2021, Marco Aldinucci has been the Director … Continued
‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work.
Since March 2021, Marco Aldinucci has been the Director of the brand new “HPC Key Technologies and Tools” national lab at the Italian National Interuniversity Consortium for Informatics (CINI), which affiliates researchers interested in HPC and cloud from 35 Italian universities.
He is the recipient of the HPC Advisory Council University Award in 2011, the NVIDIA Research Award in 2013, and the IBM Faculty Award in 2015. He has participated in over 30 EU and national research projects on parallel computing, attracting over 6M€ of research funds to the University of Torino. He is also the founder of HPC4AI, the competence center on HPC-AI convergence that federates four labs in the two universities of Torino.
What are your research areas of focus?
I like to define myself as a pure computer scientist with a natural inclination for multi-disciplinarity. Parallel and High-Performance Computing is useful when applied to other scientific domains, such as chemistry, geology, physics, mathematics, medicine. It is, therefore, crucial for me to work with domain experts, and do so while maintaining my ability to delve into performance issues regardless of a particular application. To me, Artificial Intelligence is also a class of applications.
When did you know that you wanted to be a researcher and wanted to pursue this field?
I was a curious child and I would say that discovering new things is simply the condition that makes me feel most satisfied. I got my MSc and Ph.D. at the University of Pisa, Italy’s first Computer Science department, established in the late 1960s. The research group on Parallel Computing was strong. As a Ph.D. student, I have deeply appreciated their approach to distilling and abstracting computational paradigms independent of the specific domain and, therefore, somehow universal. That is mesmerizing.
What motivated you to pursue your recent research area of focus in supercomputing and the fight against COVID?
People remember the importance of research only in times of need, but sometimes it’s too late. When COVID arrived, all of us researchers felt the moral duty to be the front-runners in investing our energy and our time well beyond regular working hours. When CLAIRE (“Confederation of Laboratories for Artificial Intelligence Research in Europe”) proposed I lead a task force of volunteer scientists to help develop tools to fight against COVID, I immediately accepted. It was the task force on the HPC plus AI-based classification of interstitial pneumonia. I presented the results in my talk at GTC ’21; they are pretty interesting.
** Click here to watch the presentation from GTC ’21, “The Universal Cloud-HPC Pipeline for the AI-Assisted Explainable Diagnosis of of COVID-19 Pneumonia“.
The CLAIRE-COVID19 universal pipeline, designed to compare different training algorithms to define a baseline for such techniques and to allow the community to quantitatively measure AI’s progress in the diagnosis of COVID-19 and similar diseases. [source]
What problems or challenges does your research address?
I am specifically interested in what I like to call “the modernization of HPC applications,” which is the convergence of HPC and AI, but also all the methodologies needed to build portable HPC applications running on the compute continuum, from HPC to cloud to edge. The portability of applications and performances is a severe issue for traditional HPC programming models.
In the long term, writing scalable parallel programs that are efficient, portable, and correct must be no more onerous than writing sequential programs. To date, parallel programming has not embraced much more than low-level libraries, which often require the application’s architectural redesign. In the hierarchy of abstractions, they are only slightly above toggling absolute binary in the machine’s front panel. This approach cannot effectively scale to support the mainstream of software development where human productivity, total cost, and time to the solution are equally, if not more, important aspects. Modern AI toolkits and their cloud interfaces represent a tremendous modernization opportunity because they contaminate the small world of MPI and the batch jobs with new concepts: modular design, the composition of services, segregation of effects and data, multi-tenancy, rapid prototyping, massive GPU exploitation, interactive interfaces. After the integration with AI, HPC will not be what it used to be.
What challenges did you face during the research process, and how did you overcome them?
Technology is rapidly evolving, and keeping up with the new paradigms and innovative products that appear almost daily is the real challenge. Having a solid grounding in computer science and math is essential to being an HPC and AI researcher in this ever-changing world. Technology evolves every day, but revolutions are rare events. I happen to say to my students: it doesn’t matter how many programming languages you know; the problem is how much effort is needed to learn the next.
How is your work impacting the community?
I have always imagined the HPC realm as organized around three pillars: 1) infrastructures, 2) enabling technologies for computing, and 3) applications. We were strong on infrastructures and applications in Italy, but excellencies in technologies for computing were spread around different universities as leopard spots.
For this, we recently started a new national laboratory called “HPC Key technologies and Tools” (HPC-KTT). I am the founding Director. HPC-KTT co-affiliates hundreds of researchers from 35 Italian universities to reach the critical mass to impact international research with our methods and tools. In the first year of activity, we gathered EU research projects in competitive calls for a total cost 95M€ (ADMIRE, ACROSS, TEXTAROSSA, EUPEX, The European Pilot). We have just started, more information can be found in:
M. Aldinucci et al, “The Italian research on HPC key technologies across EuroHPC,” in ACM Computing Frontiers, Virtual Conference, Italy, 2021. doi:10.1145/3457388.3458508
What are some of your most proudest breakthroughs?
I routinely use both NVIDIA hardware and software. Most of the important research results I recently achieved in multi-disciplinary teams have been achieved thanks to NVIDIA technologies that are capable to accelerate machine learning tasks. Among recent results, I can mention a couple of important papers that appeared on “the Lancet” and “Medical image analysis“, but also HPC4AI (High-Performance Computing for Artificial Intelligence), a new data center I started at my university. HPC4AI runs an OpenStack cloud with almost 5000 cores, 100 GPUs (V100/T4), and six different storage systems. HPC4AI is the living laboratory where researchers and students of the University of Torino understand how to build performant data-centric applications across the entire HPC-cloud stack, from bare metal configuration to algorithms to services.
What’s next for your research?
We are working on two new pieces of software: a next-generation Workflow Management System called StreamFlow and CAPIO (Cross-Application Programmable I/O), a system for fast data transfer between parallel applications with support for parallel in-transit data filtering. We can sue them separately, but together, they express the most significant potential.
StreamFlow enables the design of workflows and pipelines portable across the cloud (on Kubernetes), HPC systems (via SLURM/PBS), or across them. It adopts an open standard interface (CWL) to describe the data dependencies among workflow steps but separate deployment instructions, making it possible to re-deploy the same containerized code onto different platforms. Using StreamFlow, we make the CLAIRE COVID universal pipeline” and QuantumESPRESSO almost everywhere, from a single NVIDIA DGX Station to the CINECA MARCONI100 supercomputer (11th in the TOP500 List — NVIDIA GPUs, and dual-rail Mellanox EDR InfiniBand), and across them. And they are quite different systems.
CAPIO, which is still under development, aims at efficiently (in parallel, in memory) moving data across different steps of the pipelines. The nice design feature of CAPIO is that it turns files into streams across applications without requiring code changes. It supports parallel and programmable in-transit data filtering. The essence of many AI pipelines is moving a lot of data around the system; we are embracing the file system interface to get compositionality and segregation. We do believe we will get performance as well.
Any advice for new researchers, especially to those who are inspired and motivated by your work?
cuSOLVERMp provides a distributed-memory multi-node and multi-GPU solution for solving systems of linear equations at scale! In the future, it will also solve eigenvalue and singular value problems.
Today, cuSOLVERMp version 0.0.1 is now available at no charge for members of the NVIDIA Developer Program.
The Early Access release targets P9 + IBM’s Spectrum MPI
About cuSOLVERMp
cuSOLVERMp provides a distributed-memory multi-node and multi-GPU solution for solving systems of linear equations at scale! In the future, it will also solve eigenvalue and singular value problems.
Future releases will be hosted in the HPC SDK. It will provide additional functionality and support for x86_64 + OpenMPI.
Posted by Nachiappan Valliappan, Senior Software Engineer and Kai Kohlhoff, Staff Research Scientist, Google Research
Eye movement has been studied widely across vision science, language, and usability since the 1970s. Beyond basic research, a better understanding of eye movement could be useful in a wide variety of applications, ranging across usability and user experience research, gaming, driving, and gaze-based interaction for accessibility to healthcare. However, progress has been limited because most prior research has focused on specialized hardware-based eye trackers that are expensive and do not easily scale.
In “Accelerating eye movement research via accurate and affordable smartphone eye tracking”, published in Nature Communications, and “Digital biomarker of mental fatigue”, published in npj Digital Medicine, we present accurate, smartphone-based, ML-powered eye tracking that has the potential to unlock new research into applications across the fields of vision, accessibility, healthcare, and wellness, while additionally providing orders-of-magnitude scaling across diverse populations in the world, all using the front-facing camera on a smartphone. We also discuss the potential use of this technology as a digital biomarker of mental fatigue, which can be useful for improved wellness.
Model Overview The core of our gaze model was a multilayer feed-forward convolutional neural network (ConvNet) trained on the MIT GazeCapture dataset. A face detection algorithm selected the face region with associated eye corner landmarks, which were used to crop the images down to the eye region alone. These cropped frames were fed through two identical ConvNet towers with shared weights. Each convolutional layer was followed by an average pooling layer. Eye corner landmarks were combined with the output of the two towers through fully connected layers. Rectified Linear Units (ReLUs) were used for all layers except the final fully connected output layer (FC6), which had no activation.
Architecture of the unpersonalized gaze model. Eye regions, extracted from a front-facing camera image, serve as input into a convolutional neural network. Fully-connected (FC) layers combine the output with eye corner landmarks to infer gaze x– and y-locations on screen via a multi-regression output layer.
The unpersonalized gaze model accuracy was improved by fine-tuning and per-participant personalization. For the latter, a lightweight regression model was fitted to the model’s penultimate ReLU layer and participant-specific data.
Model Evaluation To evaluate the model, we collected data from consenting study participants as they viewed dots that appeared at random locations on a blank screen. The model error was computed as the distance (in cm) between the stimulus location and model prediction. Results show that while the unpersonalized model has high error, personalization with ~30s of calibration data led to an over fourfold error reduction (from 1.92 to 0.46cm). At a viewing distance of 25-40 cm, this corresponds to 0.6-1° accuracy, a significant improvement over the 2.4-3° reported in previous work [1, 2].
Additional experiments show that the smartphone eye tracker model’s accuracy is comparable to state-of-the-art wearable eye trackers both when the phone is placed on a device stand, as well as when users hold the phone freely in their hand in a near frontal headpose. In contrast to specialized eye tracking hardware with multiple infrared cameras close to each eye, running our gaze model using a smartphone’s single front-facing RGB camera is significantly more cost effective (~100x cheaper) and scalable.
Using this smartphone technology, we were able to replicate key findings from prior eye movement research in neuroscience and psychology, including standard oculomotor tasks (to understand basic visual functioning in the brain) and natural image understanding. For example, in a simple prosaccade task, which tests a person’s ability to quickly move their eyes towards a stimulus that appears on the screen, we found that the average saccade latency (time to move the eyes) matches prior work for basic visual health (210ms versus 200-250ms). In controlled visual search tasks, we were able to replicate key findings, such as the effect of target saliency and clutter on eye movements.
Example gaze scanpaths show the effect of the target’s saliency (i.e., color contrast) on visual search performance. Fewer fixations are required to find a target (left) with high saliency (different from the distractors), while more fixations are required to find a target (right) with low saliency (similar to the distractors).
For complex stimuli, such as natural images, we found that the gaze distribution (computed by aggregating gaze positions across all participants) from our smartphone eye tracker are similar to those obtained from bulky, expensive eye trackers that used highly controlled settings, such as laboratory chin rest systems. While the smartphone-based gaze heatmaps have a broader distribution (i.e., they appear more “blurred”) than hardware-based eye trackers, they are highly correlated both at the pixel level (r = 0.74) and object level (r = 0.90). These results suggest that this technology could be used to scale gaze analysis for complex stimuli such as natural and medical images (e.g., radiologists viewing MRI/PET scans).
Similar gaze distribution from our smartphone approach vs. a more expensive (100x) eye tracker (from the OSIE dataset).
We found that smartphone gaze could also help detect difficulty with reading comprehension. Participants reading passages spent significantly more time looking within the relevant excerpts when they answered correctly. However, as comprehension difficulty increased, they spent more time looking at the irrelevant excerpts in the passage before finding the relevant excerpt that contained the answer. The fraction of gaze time spent on the relevant excerpt was a good predictor of comprehension, and strongly negatively correlated with comprehension difficulty (r = −0.72).
Digital Biomarker of Mental Fatigue Gaze detection is an important tool to detect alertness and wellbeing, and is studied widely in medicine, sleep research, and mission-critical settings such as medical surgeries, aviation safety, etc. However, existing fatigue tests are subjective and often time-consuming. In our recent paper published in npj Digital Medicine, we demonstrated that smartphone gaze is significantly impaired with mental fatigue, and can be used to track the onset and progression of fatigue.
A simple model predicts mental fatigue reliably using just a few minutes of gaze data from participants performing a task. We validated these findings in two different experiments — using a language-independent object-tracking task and a language-dependent proofreading task. As shown below, in the object-tracking task, participants’ gaze initially follows the object’s circular trajectory, but under fatigue, their gaze shows high errors and deviations. Given the pervasiveness of phones, these results suggest that smartphone-based gaze could provide a scalable, digital biomarker of mental fatigue.
Example gaze scanpaths for a participant with no fatigue (left) versus with mental fatigue (right) as they track an object following a circular trajectory.
The corresponding progression of fatigue scores (ground truth) and model prediction as a function of time on task.
Beyond wellness, smartphone gaze could also provide a digital phenotype for screening or monitoring health conditions such as autism spectrum disorder, dyslexia, concussion and more. This could enable timely and early interventions, especially for countries with limited access to healthcare services.
Another area that could benefit tremendously is accessibility. People with conditions such as ALS, locked-in syndrome and stroke have impaired speech and motor ability. Smartphone gaze could provide a powerful way to make daily tasks easier by using gaze for interaction, as recently demonstrated with Look to Speak.
Ethical Considerations Gaze research needs careful consideration, including being mindful of the correct use of such technology — applications should obtain explicit approval and fully informed consent from users for the specific task at hand. In our work, all data was collected for research purposes with users’ explicit approval and consent. In addition, users were allowed to opt out at any point and request their data to be deleted. We continue to research additional ways to ensure ML fairness and improve the accuracy and robustness of gaze technology across demographics, in a responsible, privacy-preserving way.
Conclusion Our findings of accurate and affordable ML-powered smartphone eye tracking offer the potential for orders-of-magnitude scaling of eye movement research across disciplines (e.g., neuroscience, psychology and human-computer interaction). They unlock potential new applications for societal good, such as gaze-based interaction for accessibility, and smartphone-based screening and monitoring tools for wellness and healthcare.
Acknowledgements This work involved collaborative efforts from a multidisciplinary team of software engineers, researchers, and cross-functional contributors. We’d like to thank all the co-authors of the papers, including our team members, Junfeng He, Na Dai, Pingmei Xu, Venky Ramachandran; interns, Ethan Steinberg, Kantwon Rogers, Li Guo, and Vincent Tseng; collaborators, Tanzeem Choudhury; and UXRs: Mina Shojaeizadeh, Preeti Talwai, and Ran Tao. We’d also like to thank Tomer Shekel, Gaurav Nemade, and Reena Lee for their contributions to this project, and Vidhya Navalpakkam for her technical leadership in initiating and overseeing this body of work.
Background Predictive maintenance is used for early fault detection, diagnosis, and prediction when maintenance is needed in various industries including oil and gas, manufacturing, and transportation. Equipment is continuously monitored to measure things like sound, vibration, and temperature to alert and report potential issues. To accomplish this in computers, the first step is to determine … Continued
Background
Predictive maintenance is used for early fault detection, diagnosis, and prediction when maintenance is needed in various industries including oil and gas, manufacturing, and transportation. Equipment is continuously monitored to measure things like sound, vibration, and temperature to alert and report potential issues. To accomplish this in computers, the first step is to determine the root cause of any type of failure or error. The current industry-standard practice uses complex rulesets to continuously monitor specific components, but such systems typically only alert on previously observed faults. In addition, these regular expressions (regex) rulesets do not scale. As data becomes more voluminous and heterogeneous, maintaining these rulesets presents a neverending catch-up task. Since they only alert on what has been seen in the past, they cannot detect new root causes with patterns that were unknown to analysts before.
The approach
To create a more proactive approach for predictive maintenance, we’ve implemented uses Natural Language Processing (NLP) to monitor and interpret kernel logs. The RAPIDS CLX team collaborated with the NVIDIA Enterprise Experience (NVEX) team to test and run a proof-of-concept (POC) to evaluate this NLP-based solution. The project seeks to:
Drastically reduce the time spent manually analyzing kernel logs of NVIDIA DGX systems by pinpointing important lines in the vast amount of logs,
Probabilistically classify sequences, giving the team the capability to fine-tune a threshold to decide whether a line in the log is a root cause or not.
Figure 1: Workflow using NVIDIA DGX Systems for Log Parsing in and Predictive Maintenance Use Case.
A complete example of a root cause workflow can be found in the RAPIDS CLX GitHub repository. For final deployment past the POC, the team is using NVIDIA Morpheus, an open AI framework for developers to implement cybersecurity-specific inference pipelines. Morpheus provides a simple interface for security developers and data scientists to create and deploy end-to-end pipelines that address cybersecurity, information security, and general log-based pipelines. It is built on a number of other pieces of technology, including RAPIDS, Triton, TensorRT, Streamz, CLX, and more.
The POC is outlined as follows:
The first step identifies root causes that caused past failures. NVEX provides a dataset that contains lines in kernel logs that have been marked as a root cause to date.
Next, the problem is framed as a classification problem by sorting the logs into two groups, ordinary, and root cause. Ordinary logs are labeled as 0 and root cause lines as 1.
We have fine-tuned a pre-trained BERT model from HuggingFace to perform classification. More information about the BERT model can be found in the original paper. The code block below shows the pre-trained model called “bert-base-uncased” is loaded to be used for sequence classification.
Like validation accuracy, test set accuracy is also close to one, which means most of the predicted classes are the same as the original labels. We performed an inference run for classification with two goals:
Check the number of false positives. In our context, this means the number of lines in the kernel logs that are predicted to be a root cause but are not of interest.
Check the number of false negatives. In our context, this refers to the lines that are root causes but predicted to be ordinary.
Unlike the conventional evaluation of classification tasks, having a labelled test set does not translate into interpretable results as one of our main targets is to predict previously unseen root causes. The best way to understand how the model performs is to check the resulting confusion matrix.
Table 1: Confusion matrix for root cause analysis prediction
In our use case, the confusion matrix gives the following outputs:
TN (True Negatives): These are the ordinary lines that were not labeled as a root cause, and the model correctly marks 82668 of them.
FN (False Negatives): Zero false negatives mean the model does not mark any of the known root causes as ordinary.
NRC (New Root Causes): 65 new lines that were marked as ordinary are predicted to be root causes. These are the lines that would have been missed with the existing methods.
KRC (Known Root Causes): This is the number of lines correctly marked as root cause.
NVEX analysts have reviewed our predictions and noticed some interesting logs that were not marked as a root cause of issues with the conventional methods. With regex-based methods, such new issues might have cost a significant amount of person-hours to triage, develop, and harden.
Applying our solution to more use cases
In the next phase, we plan to position similar solutions in NVIDIA platforms to alert users of potential problems or execute corrective actions with Morpheus. By building on the success of root cause analysis here, we seek to extend this into a predictive maintenance task by continuous monitoring of the logs. This use case is certainly not limited to DGX systems. For example, telecommunication infrastructure equipment, including radio, core, and transmission devices, generate a diverse set of logs. Their outages may result in loss of service and severe fines. Identifying the root cause of outages imposes a significant cost, both in terms of dollars spent and person-hours. We believe all systems that generate text-based logs, especially the ones that run mission-critical applications, would benefit from such NLP based predictive maintenance solutions immensely as it would reduce the mean time to resolution.
Recently, at GTC21, the NVIDIA CloudXR team ran a Connect with Experts session about the CloudXR SDK. We shared how CloudXR can deliver limitless virtual and augmented reality over networks (including 5G) to low cost, low-powered headsets and devices, all while maintaining the high-quality experience traditionally reserved for high-end headsets that are plugged into high-performance … Continued
Recently, at GTC21, the NVIDIA CloudXR team ran a Connect with Experts session about the CloudXR SDK. We shared how CloudXR can deliver limitless virtual and augmented reality over networks (including 5G) to low cost, low-powered headsets and devices, all while maintaining the high-quality experience traditionally reserved for high-end headsets that are plugged into high-performance computers.
Q&A session
At the end of this session, we hosted a Q&A with our panel of professional visualization solution architects and received a large number of questions from our audience. VR and AR director David Weinstein and senior manager Greg Jones from the NVIDIA CloudXR team provided answers to the top questions:
How do I get started with CloudXR?
Apply for CloudXR through the NVIDIA DevZone. If you have any questions about your application status, contact [email protected].
What did you announce at GTC?
There were three key CloudXR announcements at GTC. You can get more information about each by clicking the post links.
How are you addressing instances of running XR with large crowds such as convention centers or large public places?
The number of users at a single physical location is gated by the wireless spectrum capacity at that given location.
Do you need separate apps on both the client and the server?
The CloudXR SDK provides sample CloudXR clients (including source code) for a variety of client devices. The server side of CloudXR gets installed as a SteamVR plug-in and can stream all OpenVR applications.
Can I use CloudXR if I do not have high-end hardware?
CloudXR will run with a variety of hardware. For the server side, all VR-Ready GPUs from the Pascal and later architectures are supported. For the client side, CloudXR has been tested with HTC Vive, HTC Vive Pro, HTC Focus Plus, Oculus Quest, Oculus Quest 2, Valve Index, and HoloLens2.
Can the server be shared for multiple simultaneous clients or is this one server per one client only?
Currently, we only support one server per one client device. In a virtualized environment this means one virtual machine per one client.
Is connectivity (server to network to client) bidirectional?
Yes, the connectivity is bidirectional. The pose information and controller input data is streamed from the client to the server; frames, audio and haptics are streamed from the server to the client.
Figure 1. CloudXR configurations
What type of applications run with NVIDIA CloudXR?
OpenVR applications run with CloudXR.
More information
To learn more, visit the CloudXR page where there are plenty of videos, blog posts, webinars, and more to help you get started. Did you miss GTC21? The AR/VR sessions are available for free through NVIDIA On-Demand.


 ‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work. This month we spotlight Marco Aldinucci, Full Professor at the University of Torino, Italy, whose research focuses on parallel programming models, language, and tools. Since March 2021, Marco Aldinucci has been the Director …
‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work. This month we spotlight Marco Aldinucci, Full Professor at the University of Torino, Italy, whose research focuses on parallel programming models, language, and tools. Since March 2021, Marco Aldinucci has been the Director … 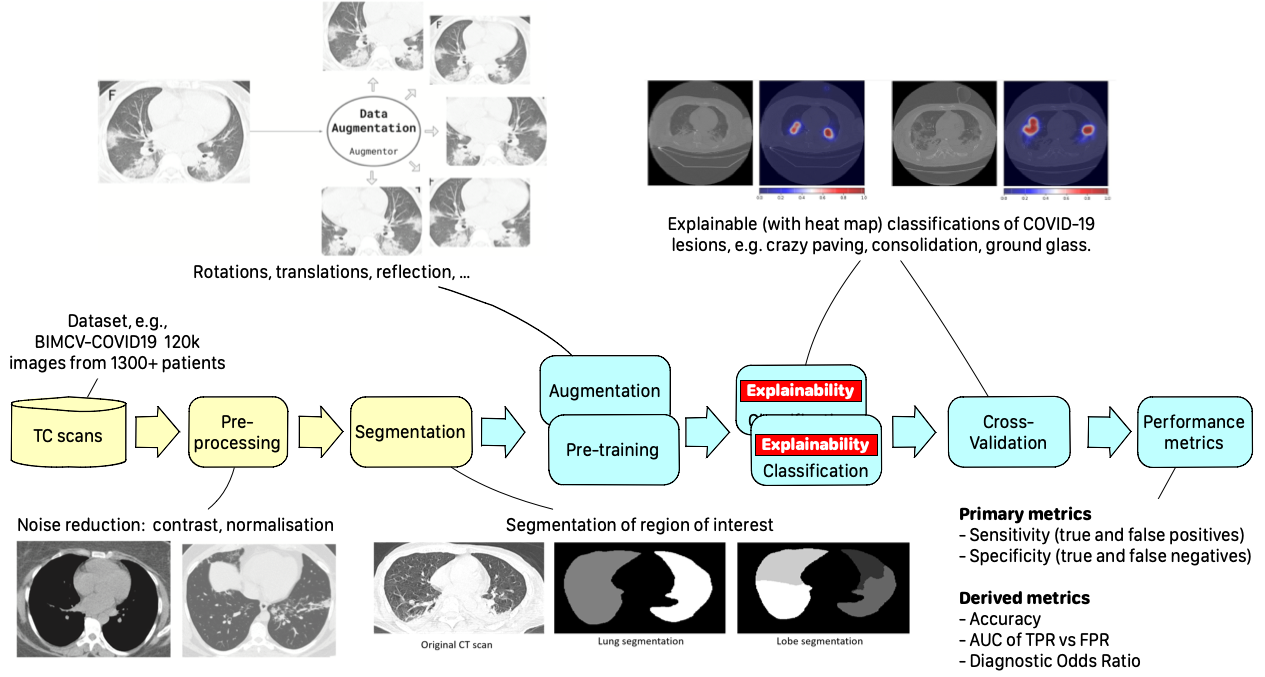
 cuSOLVERMp provides a distributed-memory multi-node and multi-GPU solution for solving systems of linear equations at scale! In the future, it will also solve eigenvalue and singular value problems.
cuSOLVERMp provides a distributed-memory multi-node and multi-GPU solution for solving systems of linear equations at scale! In the future, it will also solve eigenvalue and singular value problems.





 Background Predictive maintenance is used for early fault detection, diagnosis, and prediction when maintenance is needed in various industries including oil and gas, manufacturing, and transportation. Equipment is continuously monitored to measure things like sound, vibration, and temperature to alert and report potential issues. To accomplish this in computers, the first step is to determine …
Background Predictive maintenance is used for early fault detection, diagnosis, and prediction when maintenance is needed in various industries including oil and gas, manufacturing, and transportation. Equipment is continuously monitored to measure things like sound, vibration, and temperature to alert and report potential issues. To accomplish this in computers, the first step is to determine … 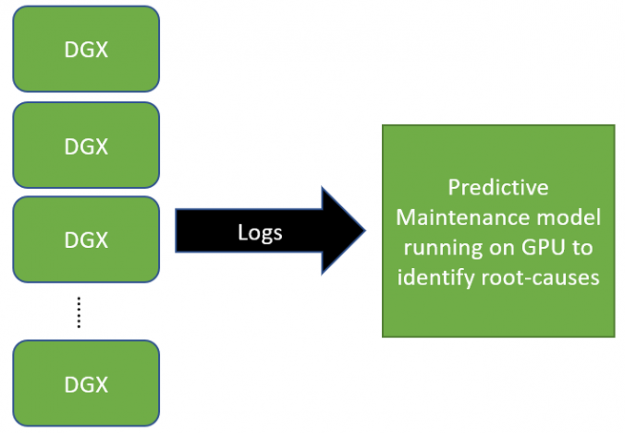

 Recently, at GTC21, the NVIDIA CloudXR team ran a Connect with Experts session about the CloudXR SDK. We shared how CloudXR can deliver limitless virtual and augmented reality over networks (including 5G) to low cost, low-powered headsets and devices, all while maintaining the high-quality experience traditionally reserved for high-end headsets that are plugged into high-performance …
Recently, at GTC21, the NVIDIA CloudXR team ran a Connect with Experts session about the CloudXR SDK. We shared how CloudXR can deliver limitless virtual and augmented reality over networks (including 5G) to low cost, low-powered headsets and devices, all while maintaining the high-quality experience traditionally reserved for high-end headsets that are plugged into high-performance … 