In both the cases when I pass an input through the layer, and then check for the trainable weights, I only see the bias, and the kernel disappears. So what have I gotten wrong here? Is it the build() method?
Machine learning techniques attract a great deal of popular attention: it isn’t difficult to find articles explaining how to extract features or train models. But the end-to-end discovery process that produces a usable machine learning system consists of more than mere techniques. Furthermore, solving business problems with data extends beyond machine learning to encompass exploratory … Continued
Machine learning techniques attract a great deal of popular attention: it isn’t difficult to find articles explaining how to extract features or train models. But the end-to-end discovery process that produces a usable machine learning system consists of more than mere techniques. Furthermore, solving business problems with data extends beyond machine learning to encompass exploratory data science, business analytics, and scalable data processing.
This is the second installment of a series describing an end-to-end blueprint for predicting customer churn. In this article, we show how reporting and exploratory data analysis fit into discovery workflows and machine learning systems. We also explain how the RAPIDS Accelerator for Apache Spark makes it possible to execute these workloads on NVIDIA GPUs — enabling nearly a 700% speedup on the analytics portion of our churn prediction application.
If you haven’t yet read the first installment, in which we described the problem, discovery workflows, and data federation and preparation, check it out first!
Exploratory analysis
The first step in the data science discovery workflow is formalizing the problem we’re trying to solve, which depends on understanding the data and understanding the business. A well-defined problem can help to codify the ways in which our analytics efforts ultimately provide business value (rather than merely achieving excellent model performance metrics). Exploratory analysis can support formalizing the problem, developing these necessary understandings, and more:
Understanding the business impact of an effective solution is important for prioritizing efforts
Business context helps practitioners identify finer-grained success criteria.
Data scientists and business analysts need to define meaningful prediction targets for the models they’ll ultimately be training.
Better understanding of the data can inspire novel modeling approaches.
Exploratory analysis can support the data science workflow’s “inner loop” of feature extraction, model training, and validation, and simulation (see Figure 1).
Figure 1: A machine learning discovery workflow. Analytics tasks are at the left and inform a data scientist’s “inner loop” of feature engineering, model training and tuning, and validation and simulation.
Prioritizing efforts to maximize business impact
Understanding the business impact of an effective solution is important for prioritizing efforts (not to mention that individual data scientists, like other employees, are interested in avenues to demonstrate the quantifiable impact of their work). While data scientists may take great pride in producing robust, general models with minimal prediction error, the business impact — not merely the predictive power of their models — should guide their efforts, and exploratory analysis is an important tool to identify the extent to which improved predictive performance might affect business metrics.
Tightening success criteria with business context
Business context helps practitioners identify finer-grained success criteria. While any organization wants to treat every customer equally in providing excellent service, it may not want to treat the risk of churn for every customer as equally important to the business. We may thus be interested in ranking churn risks by their expected remaining lifetime account value, by the expected cost to acquire a comparable account, or by other metrics.
Defining meaningful prediction targets
Data scientists and business analysts need to define meaningful prediction targets for the models they’ll ultimately be training. On a long enough timeline, every customer will fail to renew their subscription, but a model that asserts “yes, eventually” for every customer isn’t useful or actionable. A model that exclusively identifies that customers who have recently begun the process to close their accounts are likely to churn is similarly dubious. Exploratory analysis can inform a carefully crafted prediction target by enabling data scientists and analysts to simulate the plausibility and impact of various prediction targets on historical data.
Inspiring novel modeling approaches
Better understanding of the data can inspire novel modeling approaches. For example, two customer attributes may not be strongly correlated with churning individually, but their combination may be. Exploratory analysis can thus inform the process of feature engineering.
Supporting discovery workflows with ubiquitous exploratory analysis
Exploratory analysis can support the data science workflow’s “inner loop” of feature extraction, model training and tuning, and validation and simulation in two ways: directly, by providing summary statistics, domains for categorical features, and distributions for numerical features, and indirectly, by enabling data scientists to disregard uninformative features before training a model and thus making the model and the system built around it more robust.
Business analytics and reporting
While exploratory analysis is a valuable part of the early stages of the data science discovery workflow, similar workloads are important in production and can provide insight and value even without training a model. The main difference between these workloads is one of context: while exploratory analysis is generally ad hoc, business analytics workloads are typically run regularly in production. Techniques or queries used in exploratory analysis may inform or even become parts of automated reporting or analytics workloads.
Analytics in churn modeling
In our blueprint application, we’ll incorporate a pair of analytics workloads. The first workload produces a machine-readable summary report that is — along with the single wide table of customer data we described in the previous installment — part of the input to the model training application. The second workload produces a series of reports intended to help analysts and stakeholders better understand the factors that make customers more likely to renew or churn, in order to guide human decisions in the modeling process as well as to inform business decisions and service offerings that incorporate effective renewal incentives. We’ll now examine each of these in turn.
Calculating feature summaries and domains
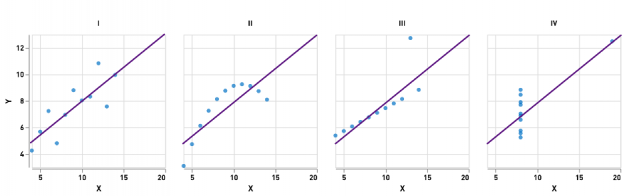
Part of understanding our data is understanding each feature individually; this is also a prerequisite to effective feature engineering or model training. Basic summary statistics — like minimum, count, mean, median, variance, and so on — are useful but may insufficient to characterize a dataset alone, since radically different datasets may have similar summary statistics. A famous example of this phenomenon is Anscombe’s Quartet (Figure 2), which is four two-variable datasets that have identical means, variances, correlations, and linear relationships but which exhibit obviously different shapes when plotted.
Figure 2: Anscombe’s Quartet, a set of synthetic datasets that have identical summary statistics but different shapes.
In order to more faithfully characterize our datasets, we’ll need to compute more descriptive summaries of individual features in addition to the basic descriptive statistics. One such summary is the cumulative distribution, which can both inform feature engineering decisions and provide valuable business context. For example, in many cases, it is more useful to know that a given customer’s monthly spend is in the 97th percentile than to know that that customer’s monthly spend is two standard deviations above the mean. Apache Spark supports efficient techniques for calculating approximate quantiles of columns in data frames, which we can use to produce cumulative distributions of these values.
We also produce a report including basic summary statistics, such as mean, minimum, maximum, and variance (for numeric features) and the identities and counts of distinct values (for discrete or categorical columns). These statistics and distributions are useful in themselves but will also make the data scientist’s job easier, since they can inform feature encoding approaches.
Exploratory analysis and reporting in churn modeling
The second component of our analytics workload simulates both exploratory analysis and scheduled reporting by producing two kinds of reports:
A set of data cubes, or multidimensional spreadsheets, showing the counts of customers with combinations of given attributes that churned or renewed, and
A collection of rollup reports showing the total lifetime account value of every customer that churned in a given quarter.
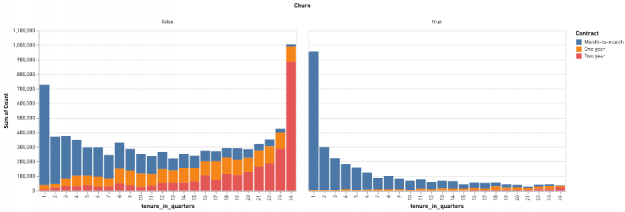
The data cube reports enable analysts to quickly drill down on a combination of features and see which are most strongly correlated with renewal or churn. It is worth noting that many real-world analytics pipelines may end at this point, since reports like this can provide actionable insight even without a trained predictive model. Figures 3 and 4 show the value of these reports: by drilling down to plot the interaction of a customer’s contract status (month-to-month, annual, or two-year) and their tenure in quarters, we can clearly establish that most of the customers who churn are relatively new and on month-to-month contracts.
Figure 3: The distributions of a customer’s tenure and contract status for customers who renewed (on the left) and who churned (on the right), demonstrating that new customers on month-to-month contracts represent the majority of churning customers.
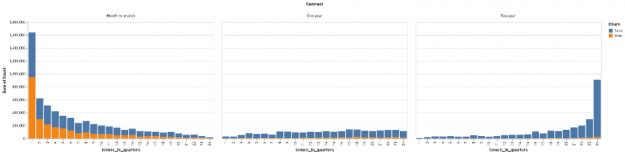
Figure 4: The distribution of renewing (blue) and churning (orange) customers by tenure in quarters, grouped by contract type, from least restrictive (on the left) to most restrictive (on the right).
These figures show another advantage of exploratory analysis and reporting: since some of the features we consider in our summaries are numeric (e.g., months of tenure), we can also use data cube reports to investigate the impact of various quantization or bucketing strategies. Instead of seeing how many customers churned at each discrete month of tenure, for example, we might be more interested in abstracting the tenure of our customers by looking at how many quarters, half-years, or years an account had been active. (In Figures 3 and 4, we bucketed customer tenures by quarter.) Identifying how best to abstract numeric data in order to convey the most information to human stakeholders and to downstream analyses alike is another goal of exploratory analysis.
Performance improvements and future work
In our previous installment, we saw how the RAPIDS Accelerator for Apache Spark could execute data federation workloads on NVIDIA GPUs. While some organizations may execute federation pipelines regularly, others may execute federation pipelines only when the pipelines themselves or the source data materially change. Exploratory analytics and reporting are more performance-sensitive, though: exploratory analytics workloads are typically interactive and human time is precious, and reporting workloads may be batch scheduled but run regularly. These workloads are also typically more complex than data federation workloads and thus also more amenable to performance improvement. By executing our analytics workloads on NVIDIA GPUs with the RAPIDS Accelerator for Apache Spark, we were able to achieve speedups of nearly 700% relative to CPU execution.
In future installments of this series, we’ll provide more details on our overall system as well as show how we improved the performance of our federation and analytics workloads. Stay tuned for more!
From real-time ray tracing, to streaming from the cloud, find out more about the breakthroughs that are helping organizations across industries enhance their XR workflows.
NVIDIA technology has powered some of the most stunning extended reality experiences across all industries. This year at GTC, several sessions showcased how the latest advancements are driving the future of XR — and all of these sessions are now available on NVIDIA On-Demand.
From real-time ray tracing, to streaming from the cloud, find out more about the breakthroughs that are helping organizations across industries enhance their XR workflows.
Check out some of the most popular XR sessions you might have missed at GTC ’21 (note: some sessions may require a free NVIDIA Developer Program membership).
See a beautifully detailed car presented by Autodesk VRED, and learn how the car was streamed to a mobile device using NVIDIA CloudXR. This was shown using a single NVIDIA RTX 8000 GPU and a Varjo XR-3 headset.
Learn how to connect a VR headset to an instance running in Google Cloud using NVIDIA CloudXR. Explore the advantages and limitations of this solution, and see a number of use cases to test performance.
Check out how NVIDIA CloudXR helps creatives use high-performance software on a lightweight mobile headset. This marks a major milestone on the path to democratizing 3D content creation.
Get an inside look at how Lucid Motors partnered with ZeroLight. The two companies launched a cloud-powered purchase journey for customers interested in exploring, customizing, or buying the new Lucid Air pure-electric luxury vehicle. Learn how this experience reflects the need to provide a digital shopping experience — linking the virtual and physical worlds.
Explore the various streaming approaches and strategies being developed, and dive into the pros and cons vis-à-vis different devices and use cases. Experience the NVIDIA CloudXR SDK, and learn more about how it works and how you can use it.
See how flexible, no-setup XR experiences can support manufacturing use cases, such as virtual 3P Workshops (Production Preparation Process). Learn how XR can enhance exploring, validating, and confirming designed manufacturing processes against the physical factory layout situation and assets on location, as well as improve workflows for digital designed products, human-centric assembly processes and worker ergonomics.
NVIDIA CloudXR continues to add additional client device support. With the NVIDIA CloudXR SDK Release 2.1, iOS devices can now use NVIDIA GPUs for advanced AR rendering, inferencing and real-time graphics. This session provided a step-by-step walkthrough of the NVIDIA CloudXR client build, deploying to a device, and testing with advanced real-time visualization tools.
Did you miss GTC? All of the AR/VR sessions are available at no charge on NVIDIA On-Demand.
Posted by Chao Jia and Yinfei Yang, Software Engineers, Google Research
Learning good visual and vision-language representations is critical to solving computer vision problems — image retrieval, image classification, video understanding — and can enable the development of tools and products that change people’s daily lives. For example, a good vision-language matching model can help users find the most relevant images given a text description or an image input and help tools such as Google Lens find more fine-grained information about an image.
To learn such representations, current state-of-the-art (SotA) visual and vision-language models rely heavily on curated training datasets that require expert knowledge and extensive labels. For vision applications, representations are mostly learned on large-scale datasets with explicit class labels, such as ImageNet, OpenImages, and JFT-300M. For vision-language applications, popular pre-training datasets, such as Conceptual Captions and Visual Genome Dense Captions, all require non-trivial data collection and cleaning steps, limiting the size of datasets and thus hindering the scale of the trained models. In contrast, natural language processing (NLP) models have achieved SotA performance on GLUE and SuperGLUE benchmarks by utilizing large-scale pre-training on raw text without human labels.
In “Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision“, to appear at ICML 2021, we propose bridging this gap with publicly available image alt-text data (written copy that appears in place of an image on a webpage if the image fails to load on a user’s screen) in order to train larger, state-of-the-art vision and vision-language models. To that end, we leverage a noisy dataset of over one billion image and alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. We show that the scale of our corpus can make up for noisy data and leads to SotA representation, and achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations also set new SotA results on Flickr30K and MS-COCO benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable zero-shot image classification and cross-modality search with complex text and text + image queries.
Creating the Dataset Alt-texts usually provide a description of what the image is about, but the dataset is “noisy” because some text may be partly or wholly unrelated to its paired image.
Example image-text pairs randomly sampled from the training dataset of ALIGN. One clearly noisy text label is marked in italics.
In this work, we follow the methodology of constructing the Conceptual Captions dataset to get a version of raw English alt-text data (image and alt-text pairs). While the Conceptual Captions dataset was cleaned by heavy filtering and post-processing, this work scales up visual and vision-language representation learning by relaxing most of the cleaning steps in the original work. Instead, we only apply minimal frequency-based filtering. The result is a much larger but noisier dataset of 1.8B image-text pairs.
ALIGN: A Large-scale ImaGe and Noisy-Text Embedding For the purpose of building larger and more powerful models easily, we employ a simple dual-encoder architecture that learns to align visual and language representations of the image and text pairs. Image and text encoders are learned via a contrastive loss (formulated as normalized softmax) that pushes the embeddings of matched image-text pairs together while pushing those of non-matched image-text pairs (within the same batch) apart. The large-scale dataset makes it possible for us to scale up the model size to be as large as EfficientNet-L2 (image encoder) and BERT-large (text encoder) trained from scratch. The learned representation can be used for downstream visual and vision-language tasks.
The resulting representation can be used for vision-only or vision-language task transfer. Without any fine-tuning, ALIGN powers cross-modal search – image-to-text search, text-to-image search, and even search with joint image+text queries, examples below.
Evaluating Retrieval and Representation The learned ALIGN model with BERT-Large and EfficientNet-L2 as text and image encoder backbones achieves SotA performance on multiple image-text retrieval tasks (Flickr30K and MS-COCO) in both zero-shot and fine-tuned settings, as shown below.
Image-text retrieval results (recall@1) on Flickr30K and MS-COCO datasets (both zero-shot and fine-tuned). ALIGN significantly outperforms existing methods including the cross-modality attention models that are too expensive for large-scale retrieval applications.
ALIGN is also a strong image representation model. Shown below, with frozen features, ALIGN slightly outperforms CLIP and achieves a SotA result of 85.5% top-1 accuracy on ImageNet. With fine-tuning, ALIGN achieves higher accuracy than most generalist models, such as BiT and ViT, and is only worse than Meta Pseudo Labels, which requires deeper interaction between ImageNet training and large-scale unlabeled data.
ImageNet classification results comparison with supervised training (fine-tuning).
Zero-Shot Image Classification Traditionally, image classification problems treat each class as independent IDs, and people have to train the classification layers with at least a few shots of labeled data per class. The class names are actually also natural language phrases, so we can naturally extend the image-text retrieval capability of ALIGN for image classification without any training data.
The pre-trained image and text encoder can directly be used in classifying an image into a set of classes by retrieving the nearest class name in the aligned embedding space. This approach does not require any training data for the defined class space.
On the ImageNetvalidation dataset, ALIGN achieves 76.4% top-1 zero-shot accuracy and shows great robustness in different variants of ImageNet with distribution shifts, similar to the concurrent work CLIP. We also use the same text prompt engineering and ensembling as in CLIP.
Top-1 accuracy of zero-shot classification on ImageNet and its variants.
Application in Image Search To illustrate the quantitative results above, we build a simple image retrieval system with the embeddings trained by ALIGN and show the top 1 text-to-image retrieval results for a handful of text queries from a 160M image pool. ALIGN can retrieve precise images given detailed descriptions of a scene, or fine-grained or instance-level concepts like landmarks and artworks. These examples demonstrate that the ALIGN model can align images and texts with similar semantics, and that ALIGN can generalize to novel complex concepts.
Image retrieval with fine-grained text queries using ALIGN’s embeddings.
Multimodal (Image+Text) Query for Image Search A surprising property of word vectors is that word analogies can often be solved with vector arithmetic. A common example, “king – man + woman = queen”. Such linear relationships between image and text embeddings also emerge in ALIGN.
Specifically, given a query image and a text string, we add their ALIGN embeddings together and use it to retrieve relevant images using cosine similarity, as shown below. These examples not only demonstrate the compositionality of ALIGN embeddings across vision and language domains, but also show the feasibility of searching with a multi-modal query. For instance, one could now look for the “Australia” or “Madagascar” equivalence of pandas, or turn a pair of black shoes into identically-looking beige shoes. Also, it is possible to remove objects/attributes from a scene by performing subtraction in the embedding space, shown below.
Image retrieval with image text queries. By adding or subtracting text query embedding, ALIGN retrieves relevant images.
Social Impact and Future Work While this work shows promising results from a methodology perspective with a simple data collection method, additional analysis of the data and the resulting model is necessary before the responsible use of the model in practice. For instance, considerations should be made towards the potential for the use of harmful text data in alt-texts to reinforce such harms. With regard to fairness, data balancing efforts may be required to prevent reinforcing stereotypes from the web data. Additional testing and training around sensitive religious or cultural items should be taken to understand and mitigate the impact from possibly mislabeled data.
Further analysis should also be taken to ensure that the demographic distribution of humans and related cultural items, such as clothing, food, and art, do not cause skewed model performance. Analysis and balancing would be required if such models will be used in production.
Conclusion We have presented a simple method of leveraging large-scale noisy image-text data to scale up visual and vision-language representation learning. The resulting model, ALIGN, is capable of cross-modal retrieval and significantly outperforms SotA models. In visual-only downstream tasks, ALIGN is also comparable to or outperforms SotA models trained with large-scale labeled data.
Acknowledgement We would like to thank our co-authors in Google Research: Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. This work was also done with invaluable help from other colleagues from Google. We would like to thank Jan Dlabal and Zhe Li for continuous support in training infrastructure, Simon Kornblith for building the zero-shot & robustness model evaluation on ImageNet variants, Xiaohua Zhai for help on conducting VTAB evaluation, Mingxing Tan and Max Moroz for suggestions on EfficientNet training, Aleksei Timofeev for the early idea of multimodal query retrieval, Aaron Michelony and Kaushal Patel for their early work on data generation, and Sergey Ioffe, Jason Baldridge and Krishna Srinivasan for the insightful feedback and discussion.
GeForce NOW ensures your favorite games are automatically up to date, avoiding game updates and patches. Simply login, click PLAY, and enjoy an optimal cloud gaming experience. Here’s an overview on how the service keeps your library game ready at all times. Updating Games for All GeForce NOW Members When a gamer downloads an update Read article >
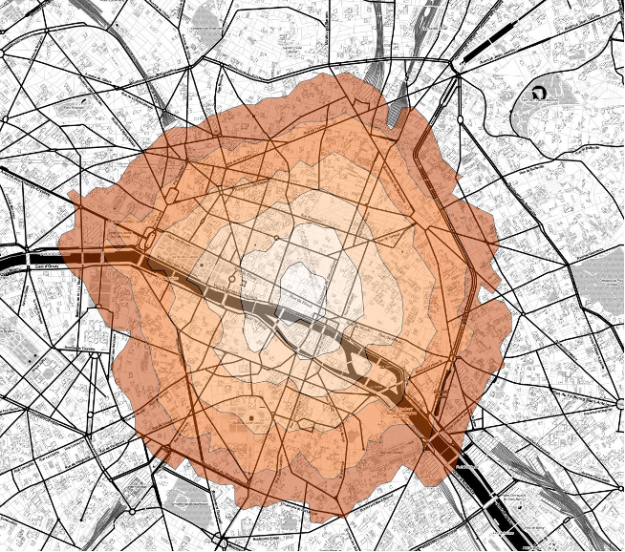
What is geospatial drive time? Geospatial analytics is an important part of real estate decisions for businesses, especially for retailers. There are many factors that go into deciding where to place a new store (demographics, competitors, traffic) and such a decision is often a significant investment. Retailers who understand these factors have an advantage over … Continued
What is geospatial drive time?
Geospatial analytics is an important part of real estate decisions for businesses, especially for retailers. There are many factors that go into deciding where to place a new store (demographics, competitors, traffic) and such a decision is often a significant investment. Retailers who understand these factors have an advantage over their competitors and can thrive. In this blog post, we’ll explore how RAPIDS’ cuDF, cuGraph, cuSpatial, and Plotly Dash with NVIDIA GPUs can be used to solve these complex geospatial analytics problems interactively.
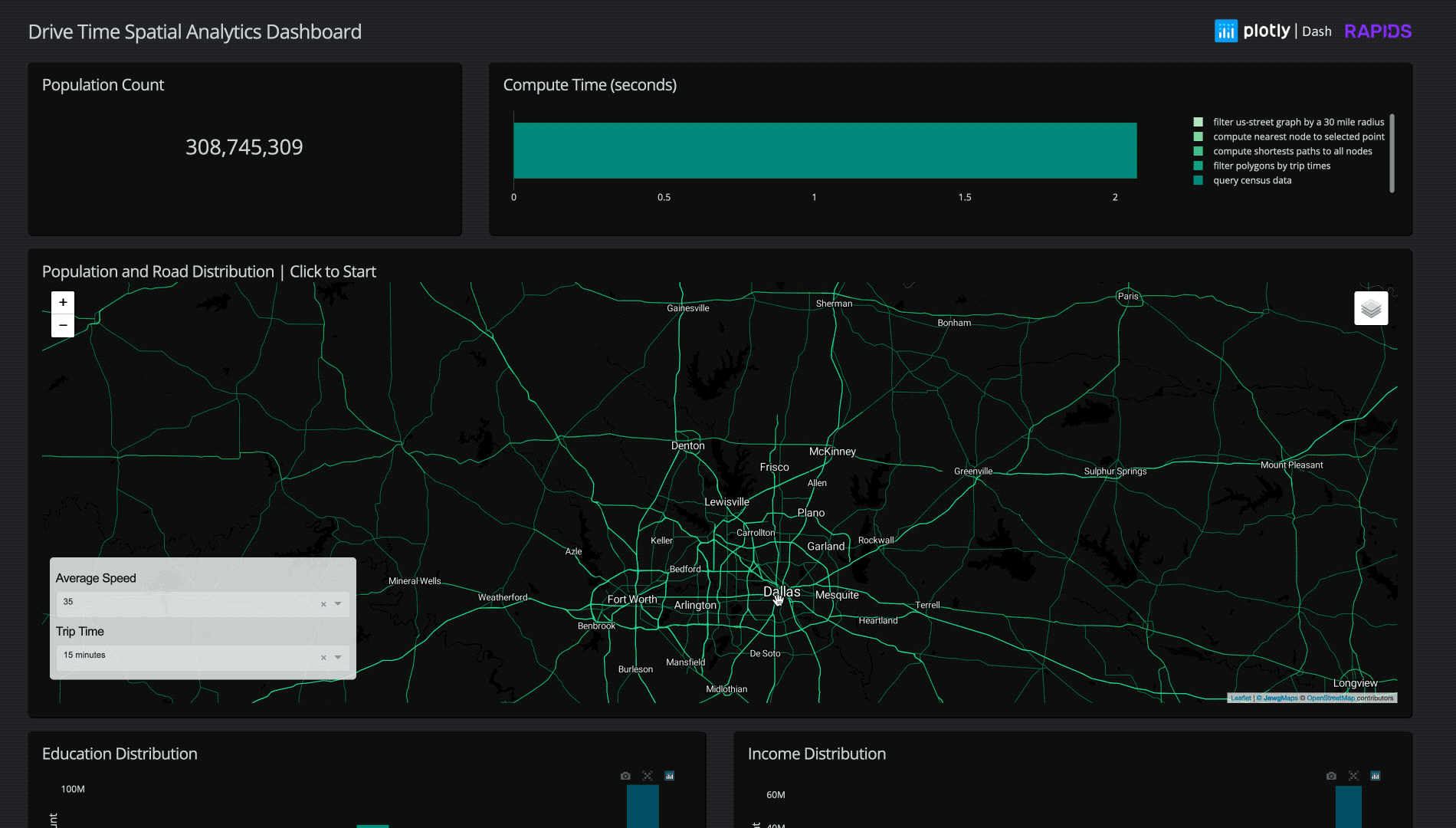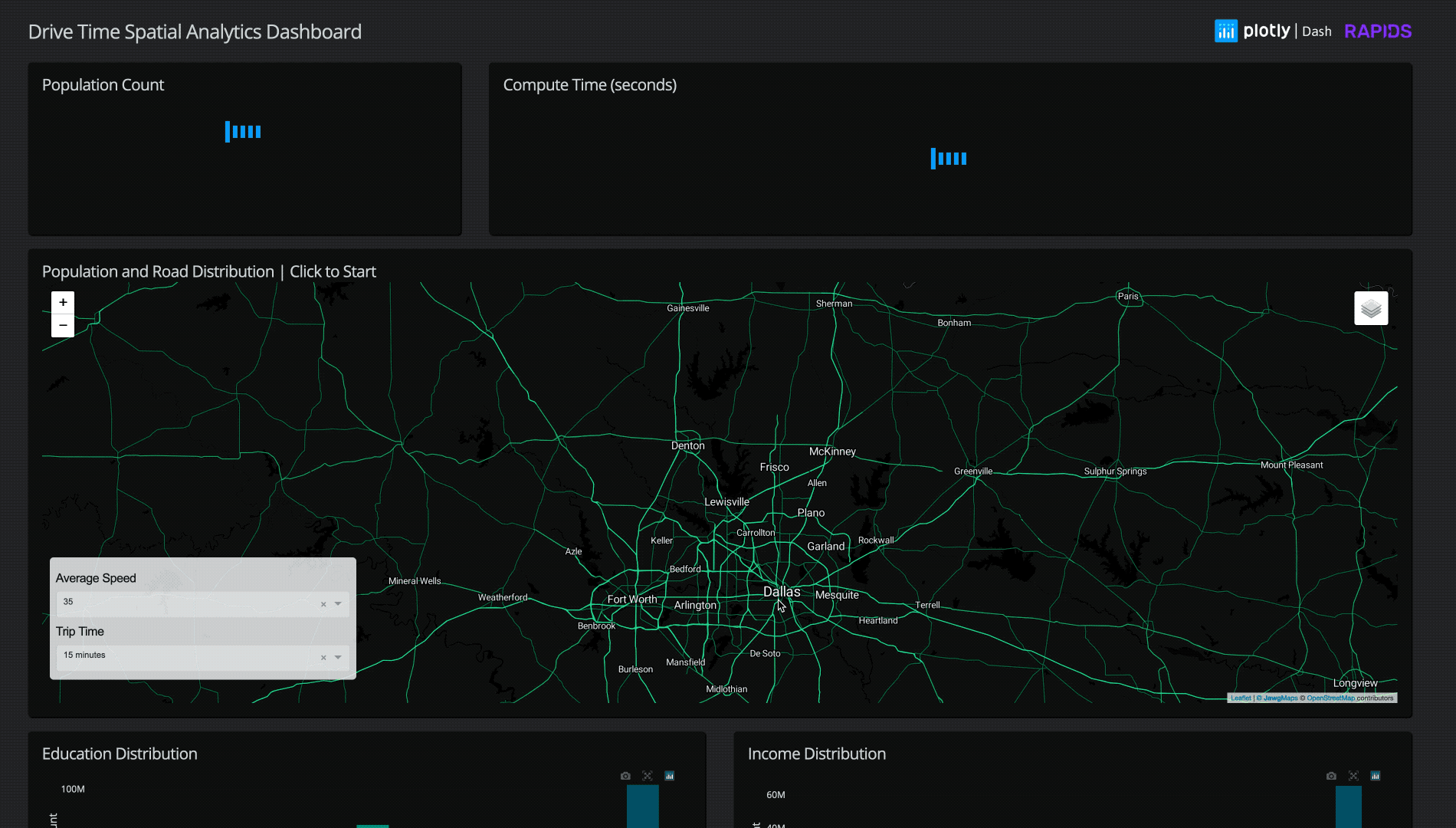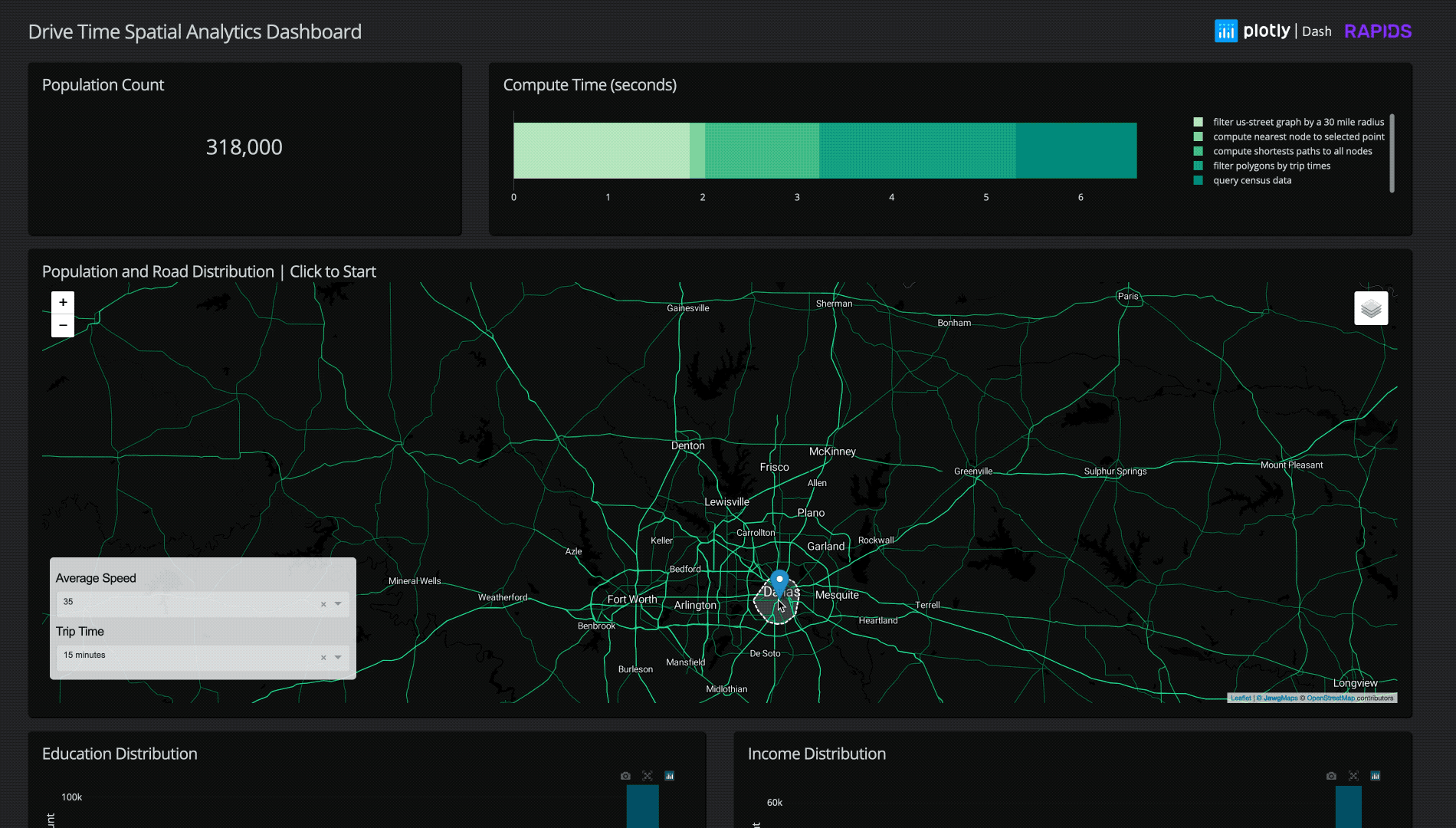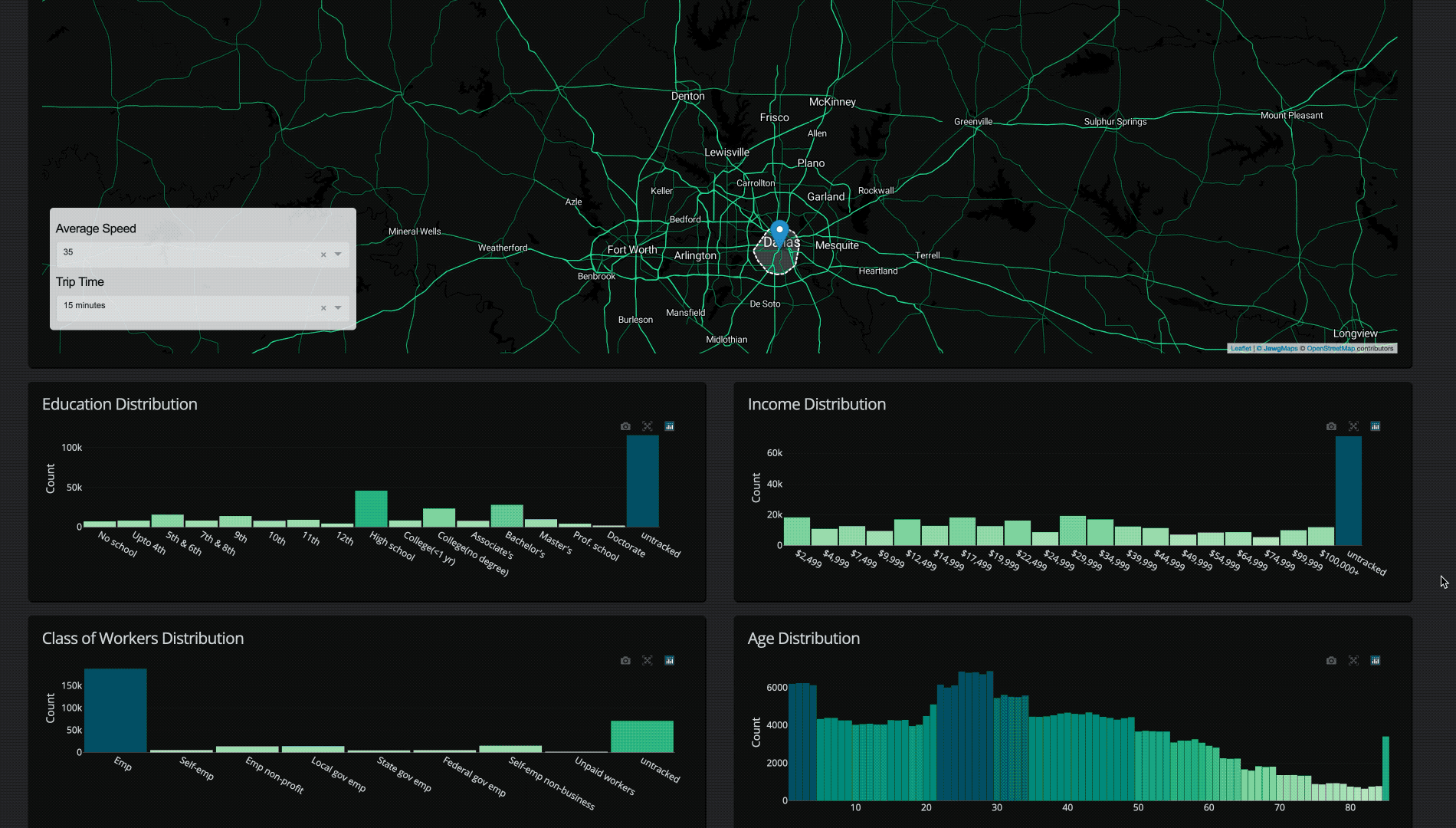
Figure 1: Animation of Plotly Dashboard using cuDF, cuSpatial, and cuGraph. See our video of it in action.
Let’s consider a retailer looking to pick the next location for a store, or in these times of a pandemic, delivery hub. After the retailer picks a candidate location, they consider a surrounding “drive-time trade area”, or more formally, isochrone. An isochrone is the resulting polygon if one starts at one geographic location and drives in all possible directions for a specified time.
Why are isochrones sometimes used instead of “as the crow flies” (i.e. a circle)? In Retail, time is one of the most important factors when going to a store or shipping out a delivery. A location might be 2 miles from a customer, but due to dense traffic, it might take me 10 minutes to get there. Instead, it might be easier to hop on the highway and drive 5 miles but instead arrive in 5 minutes.
Isochrones are also more robust to the differences between urban, suburban and rural areas. If one uses an “as the crow flies” methodology and specifies a 5 mile radius, one might be including too many customers in an urban area or excluding customers in a less dense, rural area.
Once a retailer has calculated the isochrone, they can combine it with other data like demographics or competitor datasets to generate insights about that serviceable area. How many customers live in that isochrone? What is the average household income? How many of my competitors are in the area? Is that area a “food desert” (limited access to supermarkets, general affordable resources) or a “food oasis”? Is this area highly trafficked? Answers to these questions are incredibly valuable when making a decision about a potentially multi-million dollar investment.
However, demographics, competitor, and traffic analytics datasets can be large, diverse, and difficult to crunch – even more so if complex operations like geospatial analytics are involved. Additionally, these algorithms can be challenging to scale across large geographic areas like states or countries and even harder to interact with in real time.
By combining the accelerated compute power of RAPIDS cuDF, cuGraph, and cuSpatial with the interactivity of a Plotly Dash visualization application, we are able to transform this complicated problem into an application with a simple user interface.
Mocking up a GPU accelerated workflow
Let’s think about the algorithm. So how can one calculate a drive-time area? The general flow is as follows:
Pick a point
Build a network representing roads
Identify the node in that network that is closest to that point
Traverse that network using an SSSP (single source shortest path) algorithm and identify all the nodes within some distance
Create a bounding polygon from the furthest nodes
Append data like demographics and competitor information filtered by the point in polygon operations of the polygon area
However, the idealized workflow above needs to be translated into real world functionality. Like all data visualization projects, it will take a few iterations to dial in.
Sourcing data and testing the workflow
While there are large and highly current datasets available for this type of information, they are generally not publicly available or are very costly. For the sake of simplicity and accessibility of this demo, we will use open-source data. For added accessibility, we will also scope the application to run on a single GPU with around 24-32GB of memory.
We started out by prototyping the workflow using a notebook to create a PoC workflow to compute isochrones. Despite the broad data science tooling required to tackle this problem (from graph to geospatial), the ability of the different RAPIDS’ libraries to work easily in conjunction with one another without moving out of GPU memory greatly speeds up development.
Our initial workflow used the Overpass API for OpenStreetMap to download the open-source street data in a graph format. However, a query for a 25 mi radius took approximately 4-5 minutes to complete. For the end goal of making an interactive visualization application, this was way too long
The next step was to then pre-download the entire United States OpenStreetMap data, optimize it, and save it as a parquet file for quick loading by cuDF. With the isochrones workflow producing good results, we then moved on to adding demographic data.
We conveniently had formatted 2010 census data from a previous Plotly Dash Census Visualization available. All together, the datasets were as follows:
2010 Census for Population (expanded to individuals) combined with the 2010 ACS for demographics (~2.9 GB)
US-street data ~240M nodes (~4.4 GB)
US-street data ~300M edges (~3.3 GB)
Combining and filtering datasets
We then prototyped the full workflow with the census data in another notebook. With such a large, combined dataset, computational spikes often resulted in OOM (out of memory) errors or in certain conditions took longer than ~ 10 seconds to complete. We want to enable a user to click on ANY point in the continental US and quickly get a response back. Yet, after that initial click interaction, only a small fraction of the total data set is needed. To increase speed and reduce memory spikes we had to encode some boundary assumptions:
For this use case, a retailer would not be interested in demographic information more than a 30 mi radius away from the point.
While datasets exist for more realistic road speeds (speed limit and traffic based), for simplicity we would assume an average speed.
After adding in these conditions, we were confident that we could port the notebook into a full Plotly Dash visualization dashboard.
Building an interactive dashboard with Plotly Dash
Why build an interactive dashboard? If we can already do the compute in a notebook, why should it be necessary to go through the effort of building a visualization application and optimize the compute to make it more interactive? Not everyone is familiar with using notebooks, but most can use a dashboard (especially those designed for ease of use). Furthermore, an interface that reduces the mental overhead and friction associated with doing what we actually want, asking questions of our data, encourages more experimentation and exploration. This leads to better, higher quality answers.
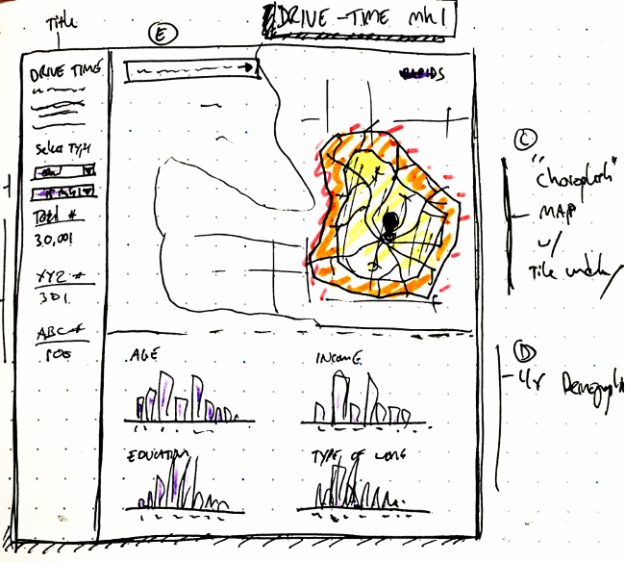
Figure 3: Skitch Mockup to define general functionality.
Starting out with a quick sketch mock-up (highly recommended for any visualization project) we went through several iterations of the dashboard to further optimize memory usage, reduce interaction times, and simplify the UI.
We found that by taking advantage of Dask for segmented data loading, we could drastically optimize loading times. Further optimization of cuSpatia’s PiP (point in polygon) and cuDF groupBy further reduced the compute times to around ~2-3 seconds per query in a sparsely populated area, and ~5-8 seconds in a densely populated area like New York City.
We also experimented with using quad-tree based point in polygon calculations for a 25-30% reduction in compute time, but because the current PiP only takes ~0.4 – 0.5 seconds in our optimized data format, the added memory overhead was not worth the speed up in this case.
For our final implementation, running a chain of operations to filter a radius of road data from the entire continental US to a selected point, load that data, find the nearest point on the road graph, compute the shortest path for the selected drive-time distance, create a polygon, and filter 300 million+ individual’s demographic data typically takes just 3-8 seconds!
Conclusion
Being able to click on any point in the continental US and, within seconds, compute both the drive time radius and demographic information within is impressive. Although this is only using limited open-source data for a generalized business use case, adapting this demo into a fully functional application would only require more precise data and a few minor optimizations.
While the performance of using GPUs is noteworthy, equally important is the speedup from using RAPIDS libraries together. Their ability to seamlessly provide end-to-end acceleration from notebook prototype to stand-alone visualization application enables interactive data science at the speed of thought.
Brings RTX Real-Time Ray Tracing and AI-Based DLSS to Tens of Millions More Gamers and Creators with $799 Portable PowerhousesSANTA CLARA, Calif., May 11, 2021 (GLOBE NEWSWIRE) — NVIDIA today …



 Machine learning techniques attract a great deal of popular attention: it isn’t difficult to find articles explaining how to extract features or train models. But the end-to-end discovery process that produces a usable machine learning system consists of more than mere techniques. Furthermore, solving business problems with data extends beyond machine learning to encompass exploratory …
Machine learning techniques attract a great deal of popular attention: it isn’t difficult to find articles explaining how to extract features or train models. But the end-to-end discovery process that produces a usable machine learning system consists of more than mere techniques. Furthermore, solving business problems with data extends beyond machine learning to encompass exploratory … 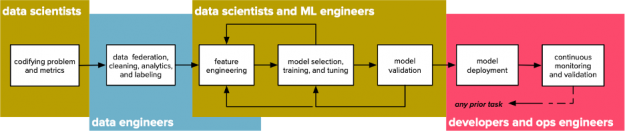




 From real-time ray tracing, to streaming from the cloud, find out more about the breakthroughs that are helping organizations across industries enhance their XR workflows.
From real-time ray tracing, to streaming from the cloud, find out more about the breakthroughs that are helping organizations across industries enhance their XR workflows.









 What is geospatial drive time? Geospatial analytics is an important part of real estate decisions for businesses, especially for retailers. There are many factors that go into deciding where to place a new store (demographics, competitors, traffic) and such a decision is often a significant investment. Retailers who understand these factors have an advantage over …
What is geospatial drive time? Geospatial analytics is an important part of real estate decisions for businesses, especially for retailers. There are many factors that go into deciding where to place a new store (demographics, competitors, traffic) and such a decision is often a significant investment. Retailers who understand these factors have an advantage over …