I’m running a classifier that is drawing data from two large datasets using two generators. I build one model and then train it in a loop that looks something like this:
myModelCheckpoint = ModelCheckpoint("dirname") for _ in range( nIterations ): x_train, y_train = getTrainingDataFromGenerators() model.fit( x_train, y_train, ... epochs=10, callbacks=[myModelCheckpoint ])
What I want is for ModelCheckpoint to fire on the single best model over all nIterations. But it seems like it resets and starts over for each model.fit(). I’ve seen a model get saved for a particular val_acc that is lower than the best val_acc of the previous model.fit().
Essentially I want a global ModelCheckpoint, not local to a particular model.fit(). Is that possible?
The latest version provides full support for running deep learning, automotive and scientific analysis on NVIDIA’s Ampere GPUs.
Announcing the availability of MATLAB 2021a on the NGC catalog, NVIDIA’s hub of GPU-optimized AI and HPC software. The latest version provides full support for running deep learning, automotive and scientific analysis on NVIDIA’s Ampere GPUs.
In addition to supporting Ampere GPUs, the latest version also includes the following features and benefits:
With the continued growth of AI models and data sets and the rise of real-time applications, getting optimal inference performance has never been more important. In this post, you learn how to get the best natural language inference performance from AWS G4dn instance powered by NVIDIA T4 GPUs, and how to deploy BERT networks easily using NVIDIA Triton Inference Server.
As the explosive growth of AI models continues unabated, natural language processing and understanding are at the forefront of this growth. As the industry heads toward trillion-parameter models and beyond, acceleration for AI inference is now a must-have.
Many organizations deploy these services in the cloud and seek to get optimal performance and utility out of every instance they rent. Instances like the AWS G4dn, powered by NVIDIA T4 GPUs, is a great platform for delivering AI inference to cutting-edge applications. The combination of Tensor Core technology, TensorRT, INT8 precision, and NVIDIA Triton Inference Server team up to get the best inference performance from AWS.
For starters, here are the dollars and cents. Running BERT-based networks, AWS customers can get a million sentences inferenced for about a dime. Using BERT Large, which is about three times larger than BERT Base, you can get a million sentences inferenced for around 30 cents. The efficiency of the T4 GPU that powers the AWS g4dn.xlarge instance means you can cost effectively deploy smart, powerful natural language applications to attract new customers, and deliver great experiences to existing customers.
Figure 1. NVIDIA T4 on the AWS g4dn.xlarge instance delivers great performance that translates into cost savings and great customer experiences.
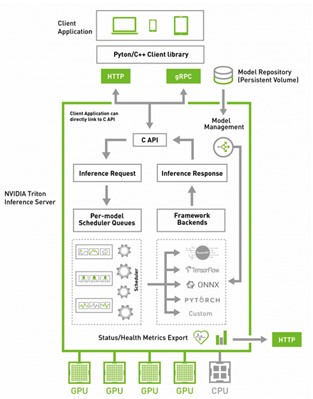
Deploying inference-powered applications is still sometimes harder than it must be. To that end, we created NVIDIA Triton Inference Server. This open-source server software eases deployment, with automatic load balancing, automatic scaling, and dynamic batching. This last feature is especially useful as many natural language AI applications must operate in real time.
Figure 2. Triton Inference Server simplifies model deployment on any CPU or GPU-powered systems.
Currently, NVIDIA Triton supports a variety of major AI frameworks, including TensorFlow, TensorRT, PyTorch, and ONNX. You can also implement your own custom inference workload by using the Python and C++ custom backend.
With the new feature introduced in the NVIDIA Triton tools model analyzer, you can set a latency budget of five milliseconds. NVIDIA Triton automatically sets the optimal batch size for best throughput while maintaining that latency budget. In addition, NVIDIA Triton is tightly coupled with Kubernetes. It can be used with cloud provider-managed Kubernetes services like Amazon EKS, Google Kubernetes Engine, and Azure Kubernetes Service.
BERT inference performance
Because language models are often used in real-time applications, we discuss performance at several latency targets, specifically 5ms and 10ms. To simulate a real-world application, assume that there are multiple end users all sending inference requests with a batch size of one simultaneously. What’s of interest is how many requests can be handled per second.
For these measurements on G4dn, we used NVIDIA Triton to serve the BERT QA model with a sequence length of 128 and precision of INT8. Using INT8 precision, we saw up to an 80% performance improvement compared to FP16, which translates into more simultaneous requests at any given latency requirement.
Much higher throughput can be obtained with the NVIDIA Triton optimizations of concurrent model execution and dynamic batching. You can also make use of the model analyzer tool to help you find the optimal configurations to maximize the throughput under the required latency of 5 ms and 10 ms.
Batch throughput
Real-time throughput
Batch inference cost per 1M inferences
Real-time inference Cost per 1M inferences
BERT Base
1,794
1,794
$0.08
$0.08
BERT Large
525
449
$0.33
$0.28
Table 1. Low-latency performance and cost per million inferences. Throughput measured in sentences/second.
For BERT Base, you can see that T4 can get nearly 1,800 sentences/sec within a 10ms latency budget. T4 very quickly achieves its maximum throughput, and so the real-time throughput is about the same as the high batch throughput. This performance means that a single T4 GPU can simultaneously deliver answers to nearly 1,800 simultaneous requests and deliver a million of these answers for less than a dime, making it a cost-effective solution.
BERT-Large is about three times larger than BERT-Base and can deliver more accurate and refined answers. With this model, T4 on G4dn can deliver 449 samples per second within the 10ms latency limit, and 525 sentences/sec for batch throughput. In terms of cost per million inferences, this translates into an instance cost of 33 cents for real-time and 28 cents for batch throughput, again delivering great performance/dollar.
Optimal inference with TensorRT
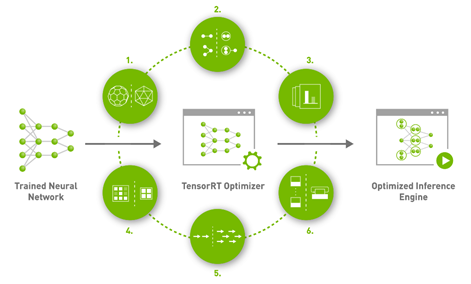
Figure 2. TensorRT delivers optimal performance, latency, accuracy and efficiency on NVIDIA data center platforms.
NVIDIA TensorRT plays a key role in getting the most performance and value out of AWS G4 instances. This inference SDK delivers high-performance, deep learning inference. It includes a deep learning inference optimizer and runtime that brings low latency and high throughput for deep learning inference applications. Figure 2 shows the major features:
Reduce mixed precision: Maximizes throughput by quantizing models to INT8 while preserving accuracy.
Layer and tensor fusion: Optimized use of GPU memory and bandwidth by fusing nodes in a kernel.
Kernel auto-tuning: Selects best layers and algorithms based on the target GPU platform.
Dynamic tensor memory: Minimizes memory footprint and reuses memory for tensors efficiently.
Multi-stream execution: Uses a scalable design to process multiple input streams in parallel.
Time fusion: Optimizes recurrent neural networks over time with dynamically generated kernels.
TensorRT maximizes throughput by quantizing models to INT8 while preserving accuracy, and automatically selects best data layers and algorithms that are optimized for the target GPU platform.
TensorRT and NVIDIA Triton Inference Server software are both available from NGC Catalog, the curated set of NVIDIA GPU-optimized software for AI, HPC, and visualization. The NGC Catalog consists of containers, pretrained models, Helm charts for Kubernetes deployments, and industry-specific AI toolkits with SDKs. TensorRT and NVIDIA Triton are also both available in the NGC Catalog in AWS Marketplace, making it even easier to use these resources on AWS G4 instances.
Amazon EC2 G4 instances
AWS offers the G4dn Instance based on NVIDIA T4 GPUs, and describes G4dn as “the lowest cost GPU-based instances in the cloud for machine learning inference and small scale training.”
Amazon EC2 offers a variety of G4 instances with one or multiple GPUs, and with different amounts of vCPU and memory. You can perform BERT inference below 5 ms on a single T4 GPU with 16 GB, such as on a g4dn.xlarge instance. The cost of this instance at the time of publication is $0.526 per hour on demand in the US East (N. Virginia) Region
Running BERT on AWS G4dn
Here’s how to get the most performance from the popular language model BERT, a transformer-based model introduced by Google a few years ago. We discuss performance for both BERT-Base and BERT-Large and then walk through how to set up NVIDIA Triton to perform inferences on both models.
To experience the outstanding performance shown earlier, follow the detailed steps in the TensorRT demo. To save all the efforts needed for complicated environment setup and configuring, you can start directly with updated monthly, performance-optimized containers available on NGC.
Set up the NGC command line interface and download dataset as well as models. To set up the NGC command line interface, follow the download instructions based on your OS (AMD64 Linux, in this case).
Change to the BERT directory:
cd /workspace/TensorRT/demo/BERT
Download SQuAD v2.0 training and dev dataset.
bash ./scripts/download_squad.sh v2_0
Download TensorFlow checkpoints for BERT base model with sequence length 128, fine-tuned for SQuAD v2.0. It takes few minutes to download the model.
bash scripts/download_model.sh base
Install related packages and Build the TensorRT engine. To build an engine, follow these steps. Install the required package:
pip install pycuda
Create a directory to store the engines:
mkdir -p engines
Run the builder.py script to build the engine with FP16 precision:
Deploy the BERT QA model for inference with NVIDIA Triton Inference Server
NVIDIA Triton supports the following optimization modes:
Concurrent model execution: Enables multiple models, or multiple instances of the same model, to execute in parallel on the same GPU or on multiple GPUs to exploit the parallelism of GPU better.
Dynamic batching: Instruct the server to wait a predefined amount of time to combine individual inference requests into a preferred batch size preconfigured to enhance GPU utilization and improve inference throughput.
For more information about framework-specific optimization, see Optimization.
In this section, we show you how to deploy the TensorRT model with NVIDIA Triton Inference Server and turn on concurrent model execution. We also demonstrate dynamic batching with only a few lines of code. Follow these steps on the g4dn.xlarge instance launched earlier.
In the first step, you regenerate the model files with a larger batch size to enable NVIDIA Triton dynamic batching optimizations. This is supposed to run in the same container as the one in previous sections.
Regenerate the TensorRT engine files with a larger batch size:
In this format, triton_serving is the model repository containing all your models, bert_base_qa is the model name, and 1 is the version number.
If you don’t know what to put into the config.pbtxt file yet, you may use the --strict-model-config False flag to let NVIDIA Triton serve the model with an automatically generated configuration.
In addition to the default configuration automatically generated by the NVIDIA Triton server, we recommend finding an optimal configuration based on the actual workload that users need. Download our example config.pbtxt file.
As you can see from the config.pbtxt file, you only need four lines of code to enable dynamic batching:
Here, the preferred_batch_size option means the preferred batch size that you would like to combine your input requests into. The max_queue_delay_microseconds option is how long the NVIDIA Triton server waits when the preferred size cannot be created from the available requests.
For concurrent model execution, directly specify the model concurrency per GPU by changing the count number in the instance_group.
instance_group {
count: 2
kind: KIND_GPU
}
For more information about the configuration files, see Model Configuration.
Start the NVIDIA Triton server by running the following command:
docker run --gpus all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $HOME/triton_serving/:/models nvcr.io/nvidia/tritonserver:21.04-py3 tritonserver --model-repository=/models (--strict-model-config False)
The --strict-model-config False is only needed if you are not including the config.pbtxt file in your NVIDIA Triton server directory.
With that, congratulations on having your first NVIDIA Triton server running! Feel free to use the HTTP and grpc protocols to send your request or use the Performance Analyzer tool to test the server performance.
NVIDIA Triton performance benchmarking with perf_analyzer
For the following benchmark, you use the perf_analyzer application to generate concurrent inference requests and measure the throughput and latency of those requests. By default, perf_analyzer sends requests with concurrency number 1 and batch size 1. The whole process works as follows:
The perf_analyzer sends one inference request to NVIDIA Triton, waits for the response, and only sends the subsequent request once the previous response is received.
To simulate multiple end users using the service simultaneously, increase the request concurrency number to generate more loads to the NVIDIA Triton server.
While the NVIDIA Triton server from the previous step is still running, open a new terminal, connect using SSH to the instance that you were running, and run the NGC NVIDIA Triton SDK container:
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:21.04-py3-sdk
This starts the perf analyzer sending the request with the default request concurrency 1 and batch size 1. A detailed log of throughput and latency with breakdown is printed for further analysis. You may also add the --concurrency-range and -b flags to increase the request concurrency and batch size to simulate more heavy load scenarios. For example:
The preceding command sends the request with request concurrency 8 and batch size 1 to the NVIDIA Triton server.
Tables 2 and 3 show the inference throughput and latency results.
Instance
Batch size
Request concurrency
Model concurrency GPU
Preferred batch size for dynamic batching
Throughput (sentences/sec)
p99 latency (ms)
g4dn.xlarge
1
1
1
Not enabled
427
2.5
g4dn.xlarge
1
8
2
4
1,639
5.2
g4dn.xlarge
1
16
2
8
1,794
9.4
Table 2. NVIDIA Triton serving BERT-Base QA inference performance (concurrent model execution and dynamic batching).
Instance
Batch size
Request concurrency
Model concurrency GPU
Preferred batch size for dynamic batching
Throughput (sentences/sec)
p99 latency (ms)
g4dn.xlarge
1
1
1
Not enabled
211
4.8
g4dn.xlarge
1
4
2
2
449
9.5
Table 3. NVIDIA Triton serving BERT-Large QA inference performance (concurrent model execution and dynamic batching).
Table 3 shows that NVIDIA Triton can provide higher throughput with the concurrent model execution and dynamic batching features compared to the baseline without these optimizations on the same infrastructure.
With the default configuration for BERT-Base, you can reduce P99 latency down to 2.5 ms. You can achieve a throughput of 1639 sentences/sec with P99 latency around 5ms and 1794 sentences/sec with P99 latency less than 10ms by combining dynamic batching and concurrent model execution.
With dynamic batching and concurrent model execution enabled, you can do inference for BERT-Large:
A P99 latency of 4.8 ms with the lowest latency
A best throughput of 449 sentences/sec under 10 ms P99 latency
Conclusion
To summarize, you converted a fine-tuned BERT model for QA tasks into a TensorRT engine, which is highly optimized for inference. The optimized BERT QA engine was then deployed on NVIDIA Triton Inference Server, with concurrent model execution and dynamic batching to get the best performance from NVIDIA T4 GPUs.
Be sure to visit NGC, where you can find GPU-optimized AI, high-performance computing (HPC), and data analytics applications, as well as enterprise-grade containers, pretrained AI models, and industry-specific SDKs to aid in the development of your own workload. Also, stay tuned for the upcoming TensorRT 8, which includes new features like sparsity optimization for NVIDIA Ampere Architecture GPUs, quantization-aware training, and an enhanced compiler to accelerate transformer-based networks.
With live sports making a comeback, one thing remains a constant: Nobody likes to miss big plays while waiting in line for a cold drink or snack. Zippin offers sports fans checkout-free refreshments, and it’s racking up wins among stadiums as well as retailers, hotels, apartments and offices. The startup, based in San Francisco, develops Read article >
Posted by Daniel Seita, Research Intern and Andy Zeng, Research Scientist, Robotics at Google
While the robotics research community has driven recentadvances that enable robots to grasp a wide range of rigid objects, less research has been devoted to developing algorithms that can handle deformable objects. One of the challenges in deformable object manipulation is that it is difficult to specify such an object’s configuration. For example, with a rigid cube, knowing the configuration of a fixed point relative to its center is sufficient to describe its arrangement in 3D space, but a single point on a piece of fabric can remain fixed while other parts shift. This makes it difficult for perception algorithms to describe the complete “state” of the fabric, especially under occlusions. In addition, even if one has a sufficiently descriptive state representation of a deformable object, its dynamics are complex. This makes it difficult to predict the future state of the deformable object after some action is applied to it, which is often needed for multi-step planning algorithms.
In “Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks,” to appear at ICRA 2021, we release an open-source simulated benchmark, called DeformableRavens, with the goal of accelerating research into deformable object manipulation. DeformableRavens features 12 tasks that involve manipulating cables, fabrics, and bags and includes a set of model architectures for manipulating deformable objects towards desired goal configurations, specified with images. These architectures enable a robot to rearrange cables to match a target shape, to smooth a fabric to a target zone, and to insert an item in a bag. To our knowledge, this is the first simulator that includes a task in which a robot must use a bag to contain other items, which presents key challenges in enabling a robot to learn more complex relative spatial relations.
The DeformableRavens Benchmark DeformableRavens expands our prior work on rearranging objects and includes a suite of 12 simulated tasks involving 1D, 2D, and 3D deformable structures. Each task contains a simulated UR5 arm with a mock gripper for pinch grasping, and is bundled with scripted demonstrators to autonomously collect data for imitation learning. Tasks randomize the starting state of the items within a distribution to test generality to different object configurations.
Examples of scripted demonstrators for manipulation of 1D (cable), 2D (fabric), and 3D (bag) deformable structures in our simulator, using PyBullet. These show three of the 12 tasks in DeformableRavens. Left: the task is to move the cable so it matches the underlying green target zone. Middle: the task is to wrap the cube with the fabric. Right: the task is to insert the item in the bag, then to lift and move the bag to the square target zone.
Specifying goal configurations for manipulation tasks can be particularly challenging with deformable objects. Given their complex dynamics and high-dimensional configuration spaces, goals cannot be as easily specified as a set of rigid object poses, and may involve complex relative spatial relations, such as “place the item inside the bag”. Hence, in addition to tasks defined by the distribution of scripted demonstrations, our benchmark also contains goal-conditioned tasks that are specified with goal images. For goal-conditioned tasks, a given starting configuration of objects must be paired with a separate image that shows the desired configuration of those same objects. A success for that particular case is then based on whether the robot is able to get the current configuration to be sufficiently close to the configuration conveyed in the goal image.
Goal-Conditioned Transporter Networks To complement the goal-conditioned tasks in our simulated benchmark, we integrated goal-conditioning into our previously released Transporter Network architecture — an action-centric model architecture that works well on rigid object manipulation by rearranging deep features to infer spatial displacements from visual input. The architecture takes as input both an image of the current environment and a goal image with a desired final configuration of objects, computes deep visual features for both images, then combines the features using element-wise multiplication to condition pick and place correlations to manipulate both the rigid and deformable objects in the scene. A strength of the Transporter Network architecture is that it preserves the spatial structure of the visual images, which provides inductive biases that reformulate image-based goal conditioning into a simpler feature matching problem and improves the learning efficiency with convolutional networks.
An example task involving goal-conditioning is shown below. In order to place the green block into the yellow bag, the robot needs to learn spatial features that enable it to perform a multi-step sequence of actions to spread open the top opening of the yellow bag, before placing the block into it. After it places the block into the yellow bag, the demonstration ends in a success. If in the goal image the block were placed in the blue bag, then the demonstrator would need to put the block in the blue bag.
An example of a goal-conditioned task in DeformableRavens. Left: A frontal camera view of the UR5 robot and the bags, plus one item, in a desired goal configuration. Middle: The top-down orthographic image of this setup, which is size 160×320 and passed as the goal image to specify the task success criterion. Right: A video of the demonstration policy showing that the item goes into the yellow bag, instead of the blue one.
Results Our results suggest that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Results additionally suggest that the proposed approach is more sample-efficient than alternative approaches that rely on using ground-truth pose and vertex position instead of images as input.
For example, the learned policies can effectively simulate bagging tasks, and one can also provide a goal image so that the robot must infer into which bag the item should be placed.
An example of policies trained using Transporter Networks applied in action on bagging tasks, where the objective is to first open the bag, then to put one (left) or two (right) items in the bag, then to insert the bag into the target zone. The left animation is zoomed in for clarity.
An example of the learned policy using Goal-Conditioned Transporter Networks. Left: The frontal camera view. Middle: The goal image that the Goal-Conditioned Transporter Network receives as input, which shows that the item should go in the red bag, instead of the blue distractor bag. Right: The learned policy putting the item in the red bag, instead of the distractor bag (colored yellow in this case).
Future Work This work exposes several directions for future development, including the mitigation of observed failure modes. As shown below, one failure is when the robot pulls the bag upwards and causes the item to fall out. Another is when the robot places the item on the irregular exterior surface of the bag, which causes the item to fall off. Future algorithmic improvements might allow actions that operate at a higher frequency rate, so that the robot can react in real time to counteract such failures.
Examples of failure cases from the learned Transporter-based policies on bag manipulation tasks. Left: the robot inserts the cube into the opening of the bag, but the bag pulling action fails to enclose the cube. Right: the robot fails to insert the cube into the opening, and is unable to perform recovery actions to insert the cube in a better location.
Another area for advancement is to train Transporter Network-based models for deformable object manipulation using techniques that do not require expert demonstrations, such as example-based control or model-based reinforcement learning. Finally, the ongoing pandemic limited access to physical robots, so in future work we will explore the necessary ingredients to get a system working with physical bags, and to extend the system to work with different types of bags.
Acknowledgments This research was conducted during Daniel Seita’s internship at Google’s NYC office in Summer 2020. We thank our collaborators Pete Florence, Jonathan Tompson, Erwin Coumans, Vikas Sindhwani, and Ken Goldberg.
TL;DR: Google famously noted that “speed isn’t just a feature, it’s the feature,” This is not only true for search engines but all of RAPIDS. In this post, we will showcase performance improvements for string processing across cuDF and cuML, which enables acceleration across diverse text processing workflows. Introduction In our previous post, we showed … Continued
This post was originally published on the RAPIDS AI Blog.
TL;DR: Google famously noted that “speed isn’t just a feature, it’s the feature,” This is not only true for search engines but all of RAPIDS. In this post, we will showcase performance improvements for string processing across cuDF and cuML, which enables acceleration across diverse text processing workflows.
Introduction
In our previous post, we showed basic text preprocessing with RAPIDS. Since then, we have come a long way in speed improvements, memory reductions, and API simplification.
Here is what we’ll cover in this post:
Built-in, Simplified String and Categorical Support
GPU TextVectorizers: Leaner and Meaner
Accelerating Diverse String Workflows
Built-in Support for Strings and Categoricals
Goodbye, cuStrings, nvStrings, and nvCategory! We hardly knew ye. Our first couple of posts about string manipulation on GPUs involved separate, specialized libraries for working with string data on the device. It also required significant expertise to integrate with other RAPIDS libraries like cuDF and cuML. Since then, we open-sourced, rearchitected, and migrated those string and text-related features into more user-friendly DataFrame APIs as part of cuDF. In addition, we adopted the “Apache Arrow” format for cuDF’s string representation, resulting in substantial memory savings and speedups.
As a concrete, non-toy example of these improvements, consider our recently updated Gutenberg corpus analysis notebook. Previously we had to (slowly) jump through a few hoops, but no longer!
With our improved Pandas string API coverage, we not only have simpler code, but we also get double the performance. We took 2.31s previously, now we only take 1.05s, pushing our overall speedup against Pandas to 151x.
Check out the comparison between the previous versus updated notebooks below.
We recently launched the feature.text subpackage in cuML by adding Count and TF-IDF vectorizers, kick starting a series of natural language processing (NLP) transformers on GPUs.
In our recent NLP post, we analyzed 5 million COVID-related tweets by first vectorizing them using TF-IDF and then clustering and searching in the vector space. With our recent improvements (GitHub 2554, 2575, 5666), we have improved that TF-IDF vectorization of that workflow on both memory and run time fronts.
Peak memory usage decreased from 19 GB to 8 GB.
Run time improved from 26s to 8 s, pushing our overall speed up to 21x over scikit-learn.
All the preceding improvements mean that your TF-IDF work can scale much further.
In the next installment where we put all these features through their paces in a specialized NLP benchmark. In the meantime,try RAPIDS in your NLP work on Google Colab or blazingsql notebooks, see our documentation docs page, and if you see something missing, we welcome feature requests on GitHub!
When I came to the step starting tensorboard, I’m facing :
No dashboards are active for the current data set.
After two steps, training the model, now I’m facing a lot warnings and eventually an error:
Traceback (most recent call last): File "model_main_tf2.py", line 113, in <module> tf.compat.v1.app.run() File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/platform/app.py", line 40, in run _run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef) File "/usr/local/lib/python3.7/dist-packages/absl/app.py", line 303, in run _run_main(main, args) File "/usr/local/lib/python3.7/dist-packages/absl/app.py", line 251, in _run_main sys.exit(main(argv)) File "model_main_tf2.py", line 110, in main record_summaries=FLAGS.record_summaries) File "/usr/local/lib/python3.7/dist-packages/object_detection-0.1-py3.7.egg/object_detection/model_lib_v2.py", line 639, in train_loop loss = _dist_train_step(train_input_iter) File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/def_function.py", line 828, in __call__ result = self._call(*args, **kwds) File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/def_function.py", line 888, in _call return self._stateless_fn(*args, **kwds) File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/function.py", line 2943, in __call__ filtered_flat_args, captured_inputs=graph_function.captured_inputs) # pylint: disable=protected-access File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/function.py", line 1919, in _call_flat ctx, args, cancellation_manager=cancellation_manager)) File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/function.py", line 560, in call ctx=ctx) File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute inputs, attrs, num_outputs) tensorflow.python.framework.errors_impl.ResourceExhaustedError: 2 root error(s) found. (0) Resource exhausted: OOM when allocating tensor with shape[100,51150] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[node Loss/Compare_9/IOU/Intersection/Minimum_1 (defined at /local/lib/python3.7/dist-packages/object_detection-0.1-py3.7.egg/object_detection/core/box_list_ops.py:257) ]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. [[Func/Loss/localization_loss_1/write_summary/summary_cond/then/_0/input/_71/_348]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. (1) Resource exhausted: OOM when allocating tensor with shape[100,51150] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[node Loss/Compare_9/IOU/Intersection/Minimum_1 (defined at /local/lib/python3.7/dist-packages/object_detection-0.1-py3.7.egg/object_detection/core/box_list_ops.py:257) ]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. 0 successful operations. 0 derived errors ignored. [Op:__inference__dist_train_step_51563] Errors may have originated from an input operation. Input Source operations connected to node Loss/Compare_9/IOU/Intersection/Minimum_1: Loss/Compare_9/IOU/Intersection/split (defined at /local/lib/python3.7/dist-packages/object_detection-0.1-py3.7.egg/object_detection/core/box_list_ops.py:250) Input Source operations connected to node Loss/Compare_9/IOU/Intersection/Minimum_1: Loss/Compare_9/IOU/Intersection/split (defined at /local/lib/python3.7/dist-packages/object_detection-0.1-py3.7.egg/object_detection/core/box_list_ops.py:250) Function call stack: _dist_train_step -> _dist_train_step
How can I handle these issues? And tensorboard plays important role? Or it activating tensorboard plays an important part or it just is something like optional?
GeForce NOW is always evolving, and so is this week’s GFN Thursday. Biomutant, the new open-world action RPG from Experiment 101 and THQ Nordic, is coming to GeForce NOW when it releases on May 25. Everybody Was Kung Fu Fighting Biomutant puts you in the role of an anthropomorphic rodent with swords, guns and martial Read article >
MintNV, an AI/ML educational exercise that showcases how an adversary can bypass defensive ML mechanisms to compromise a host, is now on the NVIDIA NGC catalog.
Machine Learning (ML) comes in many forms that have evaded the standard tools and techniques of cybersecurity professionals. Attacking ML requires an intersection of knowledge between data science and offensive security to answer the question, “How can this be attacked?” Cybersecurity professionals and data scientists need to hone these new skills to answer this difficult question. NVIDIA wants to inspire the ecosystem to better address this gap.
MintNV, an AI/ML educational exercise that showcases how an adversary can bypass defensive ML mechanisms to compromise a host, is now on the NVIDIA NGC catalog, NVIDIA’s hub of GPU-optimized HPC and AI applications. The MintNV docker container challenges the user to apply an adversarial thought process to ML. Creating MintNV as a vulnerable environment is a step in the right direction for ML, aligning closely with other NVIDIA contributions such as the Adversarial ML Threat Matrix.
MintNV is a bridge between AI/ML researchers and cybersecurity professionals throughout the ML landscape. It enables the offensive security community to practice adversarial ML techniques. We will continue contributing research, tools and training to promote community growth and to inspire more of this kind.
Share this exercise and enjoy learning about various offensive security concepts such as enumeration, networking protocols, and administrative functions as you compromise MintNV. Learning about potential vulnerabilities of a ML system using the MintNV simulation helps ML developers understand how to build more secure solutions.
NVIDIA would like to thank Will Pearce from Microsoft for providing the guidance necessary to implement Machine Learning elements into this educational exercise.
Happy Hacking!
NVIDIA Product Security Team
About NVIDIA Product Security Team:
NVIDIA takes security seriously and values contributions to secure, safe and unbiased use of Artificial Intelligence and Machine Learning. We will continue to create additional educational opportunities for the community. If you have any questions or feedback, please contact [email protected] or tweet us at @NVIDIAPSIRT. See NVIDIA’s Corporate Social Responsibility website and NVIDIA’s 2020 CSR Report for more information.

 The latest version provides full support for running deep learning, automotive and scientific analysis on NVIDIA’s Ampere GPUs.
The latest version provides full support for running deep learning, automotive and scientific analysis on NVIDIA’s Ampere GPUs.  With the continued growth of AI models and data sets and the rise of real-time applications, getting optimal inference performance has never been more important. In this post, you learn how to get the best natural language inference performance from AWS G4dn instance powered by NVIDIA T4 GPUs, and how to deploy BERT networks easily using NVIDIA Triton Inference Server.
With the continued growth of AI models and data sets and the rise of real-time applications, getting optimal inference performance has never been more important. In this post, you learn how to get the best natural language inference performance from AWS G4dn instance powered by NVIDIA T4 GPUs, and how to deploy BERT networks easily using NVIDIA Triton Inference Server.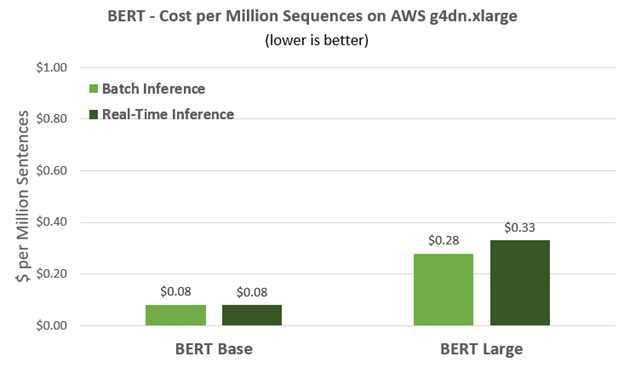






 TL;DR: Google famously noted that “speed isn’t just a feature, it’s the feature,” This is not only true for search engines but all of RAPIDS. In this post, we will showcase performance improvements for string processing across cuDF and cuML, which enables acceleration across diverse text processing workflows. Introduction In our previous post, we showed …
TL;DR: Google famously noted that “speed isn’t just a feature, it’s the feature,” This is not only true for search engines but all of RAPIDS. In this post, we will showcase performance improvements for string processing across cuDF and cuML, which enables acceleration across diverse text processing workflows. Introduction In our previous post, we showed … 


 MintNV, an AI/ML educational exercise that showcases how an adversary can bypass defensive ML mechanisms to compromise a host, is now on the NVIDIA NGC catalog.
MintNV, an AI/ML educational exercise that showcases how an adversary can bypass defensive ML mechanisms to compromise a host, is now on the NVIDIA NGC catalog.