Researchers from the U.S. National Institutes of Health have collaborated with NVIDIA experts on an AI-accelerated method to monitor COVID-19 disease severity over time from patient chest CT scans.
Researchers from the U.S. National Institutes of Health have collaborated with NVIDIA experts on an AI-accelerated method to monitor COVID-19 disease severity over time from patient chest CT scans.
Published today in Scientific Reports, this work studied the progression of lung opacities in chest CT images of COVID patients, and extracted insights about the temporal relationships between CT features and lab measurements.
Quantifying CT opacities can tell doctors how severe a patient’s condition is. A better understanding of the progression of lung opacities in COVID patients could help inform clinical decisions in patients with pneumonia, and yield insights during clinical trials for therapies to treat the virus.
Selecting a dataset of more than 100 sequential chest CTs from 29 COVID patients from China and Italy, the researchers used an NVIDIA Clara AI segmentation model to automate the time-consuming task of segmenting the total lung in each CT scan. Expert radiologists reviewed the total lung segmentations, and manually segmented the lung opacities.
To track disease progression, the researchers used generalized temporal curves, which correlated the CT imaging data with lab measurements such as white blood cell count and procalcitonin levels. They then used 3D visualizations to reconstruct the evolution of COVID opacities in one of the patients.
The team found that lung opacities appeared between one and five days before symptom onset, and peaked a day after symptoms began. They also analyzed two opacity subtypes — ground glass opacity and consolidation — and discovered that ground glass opacities appeared earlier in the disease, and persisted for a time after the resolution of the consolidation.
In the paper, the researchers showed how CT dynamic curves could be used as a clinical reference tool for mild COVID-19 cases, and might help spot cases that grow more severe over time. These curves could also assist clinicians in identifying chronic lung effects by flagging cases where patients have residual opacities visible in CT scans long after other symptoms dissipate.
Learn more about NVIDIA’s work in healthcare at the GPU Technology Conference, April 12-16. Registration is free. The healthcare track includes 16 live webinars, 18 special events, and over 100 recorded sessions.
Posted by Benjamin Eysenbach, Student Researcher, Google Research
A general goal of robotics research is to design systems that can assist in a variety of tasks that can potentially improve daily life. Most reinforcement learning algorithms for teaching agents to perform new tasks require a reward function, which provides positive feedback to the agent for taking actions that lead to good outcomes. However, actually specifying these reward functions can be quite tedious and can be very difficult to define for situations without a clear objective, such as whether a room is clean or if a door is sufficiently shut. Even for tasks that are easy to describe, actually measuring whether the task has been solved can be difficult and may require adding many sensors to a robot’s environment.
Alternatively, training a model using examples, called example-based control, has the potential to overcome the limitations of approaches that rely on traditional reward functions. This new problem statement is most similar to priormethods based on “success detectors”, and efficient algorithms for example-based control could enable non-expert users to teach robots to perform new tasks, without the need for coding expertise, knowledge of reward function design, or the installation of environmental sensors.
In “Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification,” we propose a machine learning algorithm for teaching agents how to solve new tasks by providing examples of success (e.g., if “success” examples show a nail embedded into a wall, the agent will learn to pick up a hammer and knock nails into the wall). This algorithm, recursive classification of examples (RCE), does not rely on hand-crafted reward functions, distance functions, or features, but rather learns to solve tasks directly from data, requiring the agent to learn how to solve the entire task by itself, without requiring examples of any intermediate states. Using a version of temporal difference learning — similar to Q-learning, but replacing the typical reward function term using only examples of success — RCE outperforms prior approaches based on imitation learning on simulated robotics tasks. Coupled with theoretical guarantees similar to those for reward-based learning, the proposed method offers a user-friendly alternative for teaching robots new tasks.
Top: To teach a robot to hammer a nail into a wall, most reinforcement learning algorithms require that the user define a reward function. Bottom: The example-based control method uses examples of what the world looks like when a task is completed to teach the robot to solve the task, e.g., examples where the nail is already hammered into the wall.
Example-Based Control vs Imitation Learning While the example-based control method is similar to imitation learning, there is an important distinction — it does not require expertdemonstrations. In fact, the user can actually be quite bad at performing the task themselves, as long as they can look back and pick out the small fraction of states where they did happen to solve the task.
Additionally, whereas previousresearch used a stage-wise approach in which the model first uses success examples to learn a reward function and then applies that reward function with an off-the-shelf reinforcement learning algorithm, RCE learns directly from the examples and skips the intermediate step of defining the reward function. Doing so avoids potential bugs and bypasses the process of defining the hyperparameters associated with learning a reward function (such as how often to update the reward function or how to regularize it) and, when debugging, removes the need to examine code related to learning the reward function.
Recursive Classification of Examples The intuition behind the RCE approach is simple: the model should predict whether the agent will solve the task in the future, given the current state of the world and the action that the agent is taking. If there were data that specified which state-action pairs lead to future success and which state-action pairs lead to future failure, then one could solve this problem using standard supervised learning. However, when the only data available consists of success examples, the system doesn’t know which states and actions led to success, and while the system also has experience interacting with the environment, this experience isn’t labeled as leading to success or not.
Left: The key idea is to learn a future success classifier that predicts for every state (circle) in a trajectory whether the task will be solved in the future (thumbs up/down). Right: In the example-based control approach, the model is provided only with unlabeled experience (grey circles) and success examples (green circles), so one cannot apply standard supervised learning. Instead, the model uses the success examples to automatically label the unlabeled experience.
Nonetheless, one can piece together what these data would look like, if it were available. First, by definition, a successful example must be one that solves the given task. Second, even though it is unknown whether an arbitrary state-action pair will lead to success in solving a task, it is possible to estimate how likely it is that the task will be solved if the agent started at the next state. If the next state is likely to lead to future success, it can be assumed that the current state is also likely to lead to future success. In effect, this is recursive classification, where the labels are inferred based on predictions at the next time step.
The underlying algorithmic idea of using a model’s predictions at a future time step as a label for the current time step closely resembles existing temporal-difference methods, such as Q-learning and successor features. The key difference is that the approach described here does not require a reward function. Nonetheless, we show that this method inherits many of the same theoretical convergenceguarantees as temporal difference methods. In practice, implementing RCE requires changing only a few lines of code in an existing Q-learning implementation.
Evaluation We evaluated the RCE method on a range of challenging robotic manipulation tasks. For example, in one task we required a robotic hand to pick up a hammer and hit a nail into a board. Previous research into this task [1, 2] have used a complex reward function (with terms corresponding to the distance between the hand and the hammer, the distance between the hammer and the nail, and whether the nail has been knocked into the board). In contrast, the RCE method requires only a few observations of what the world would look like if the nail were hammered into the board.
We compared the performance of RCE to a number of prior methods, including those that learn an explicit reward function and those based on imitation learning , all of which struggle to solve this task. This experiment highlights how example-based control makes it easy for users to specify even complex tasks, and demonstrates that recursive classification can successfully solve these sorts of tasks.
Compared with prior methods, the RCE approach solves the task of hammering a nail into a board more reliably that prior approaches based on imitation learning [SQIL, DAC] and those that learn an explicit reward function [VICE, ORIL, PURL].
Conclusion We have presented a method to teach autonomous agents to perform tasks by providing them with examples of success, rather than meticulously designing reward functions or collecting first-person demonstrations. An important aspect of example-based control, which we discuss in the paper, is what assumptions the system makes about the capabilities of different users. Designing variants of RCE that are robust to differences in users’ capabilities may be important for applications in real-world robotics. The code is available, and the project website contains additional videos of the learned behaviors.
Acknowledgements We thank our co-authors, Ruslan Salakhutdinov and Sergey Levine. We also thank Surya Bhupatiraju, Kamyar Ghasemipour, Max Igl, and Harini Kannan for feedback on this post, and Tom Small for helping to design figures for this post.
NVIDIA and Arm are working together to open new opportunities for partners, users, and developers, driving a new wave of computing around the world. Explore all the Arm accelerated computing and ecosystem sessions at GTC.
From powering the world’s largest supercomputers and cloud data centers, to edge devices on factory floors and city streets, the NVIDIA accelerated computing platform is used to help solve the world’s most challenging computational problems.
NVIDIA and Arm are working together to open new opportunities for partners, users, and developers, driving a new wave of computing around the world.
AI, 5G, and the internet of things are sparking the world’s potential. And for many hardware engineers and software developers, these technologies will also become the challenge of their careers. The question is how to invisibly integrate the new intelligence everywhere by creating more responsive infrastructure that links people, processes, devices, and data seamlessly. Getting there will require architectural leaps, new partnerships, and plenty of creativity. Arm President Rene Haas will discuss the forces pushing these advances and how Arm’s global developer ecosystem will react to drive the next wave of compute.
Speaker: Rene Haas, President, IP Products Group, Arm
Introducing Developer Tools for Arm and NVIDIA Systems
NVIDIA GPUs on Arm servers are here. In migrating to, or developing on, Arm servers with NVIDIA GPUs, developers using native code, CUDA, and OpenACC continue to need tools and toolchains to succeed and to get the most out of applications. We’ll explore the role of key tools and toolchains on Arm servers, from Arm, NVIDIA and elsewhere — and show how each tool fits in the end-to-end journey to production science and simulation.
Speaker: Daniel Owens, Product Director, Infrastructure Software, Arm
The Arm HPC User Group: An Open Community for Arm-Based Research and Engagement
We’ll introduce the newly created Arm HPC User Group, which provides a forum for application developers, system integrators, tool vendors, and implementers to share their experiences. Learn about the history of Arm for HPC and see what plans the Arm HPC User Group has to engage with users and researchers over the coming year. You don’t need an in-depth technical knowledge of either Arm systems or HPC to attend or appreciate this talk.
Speaker: Jeffrey Young, Senior Research Scientist, Georgia Tech
HPC Applications on Arm and NVIDIA A100
By design, HPC applications have radically different performance characteristics across domains of expertise. Achieving a balanced computing platform that addresses a breadth of HPC applications is a fundamental advance in the HPC state of the art. We demonstrate that Arm-based CPUs (such as the Ampere Altra), paired with NVIDIA GPUs (such as the NVIDIA A100), comprise a balanced, performant, and scalable supercomputing platform for any HPC application, whether CPU-bound, GPU-accelerated, or GPU-bound. We present the runtime performance profiles of representative applications from genomics.
Speakers: Thomas Bradley, Director of Developer Technology at NVIDIA John Linford, Director of HPC Applications, Arm
Scalable, Efficient, Software-Defined 5G-Enabled Edge Based on NVIDIA GPUs and Arm Servers
We’ll demonstrate a scalable, performance-optimized 5G-enabled edge cloud that’s based on Arm servers with NVIDIA GPUs. We’ll focus on fully software-defined 5G Distributed Unit (DU) with an NVIDIA GPU/Aerial-based PHY layer with the upper layers based on Ampere Altra server based on Arm Neoverse N1 CPU. We’ll cover the performance, scale, and power benefits of this architecture for a centralized radio access network architecture.
Speakers: Anupa Kelkar, Product Manager, NVIDIA Mo Jabbari, Senior Segment Marketing Manager, Arm
Register today for free and start building your schedule. Once you are signed in, you can view all Arm sessions here.
You can also explore all GTC conference topics here. Topics include areas of interest such as GPU programming, HPC, deep learning, data science, and autonomous machines, or industries including healthcare, public sector, retail, and telecommunications.
Autonomous vehicles are born in the data center, and at GTC 2021, attendees can learn exactly how high-performance compute is vital to developing, training, testing and validating the next generation of transportation. The NVIDIA GPU Technology Conference returns to the virtual stage April 12-16, featuring autonomous vehicle leaders in a range of talks, panels and […]
Autonomous vehicles are born in the data center, and at GTC 2021, attendees can learn exactly how high-performance compute is vital to developing, training, testing and validating the next generation of transportation.
The NVIDIA GPU Technology Conference returns to the virtual stage April 12-16, featuring autonomous vehicle leaders in a range of talks, panels and virtual networking events. Attendees will also have access to hands-on training for self-driving development and other deep learning topics. Registration is free of charge.
The array of redundant and diverse deep neural networks that run in autonomous vehicles all begin development in the data center and continue to be iterated upon as the car learns new features and capabilities.
Bryan Goodman, senior technical leader of Ford’s AI Advancement center, Wadim Kehl, senior machine learning engineer at Toyota, and Norm Marks, global director of automotive business development at NVIDIA, will come together for a panel discussion on the challenges and best practices for scaling data center infrastructure for this type of comprehensive DNN development.
Additionally, experts will discuss how to use GPUs to enable the scale necessary for autonomous vehicle development. Sammy Sidhu, perception engineer at Lyft, Travis Addair, senior software engineer at Uber, Michael Del Balso, founder of Tecton.ai, and Manish Harsh, manager of developer relations at NVIDIA, will cover their experience in building the machine learning operations platforms for self-driving cars.
Validation in the Virtual World
Once self-driving DNNs are developed, they must undergo exhaustive testing and validation before they can operate in the real world. With simulation, these algorithms can experience millions of miles of eventful driving data in a fraction of the time and cost it would take to drive in the real world.
Nicolas Orand, senior director at R&D Autonomy, Klaus Lamberg, strategic product manager at dSpace, Blake Gasca, senior director of business development at SmartDrive, and Justyna Zander, head of AV verification and validation at NVIDIA, will discuss the simulation toolchain, from scenario databases and sensor modeling to full system validation.
GTC will also feature the latest in simulation technology, with Gavriel State, senior director of system software at NVIDIA, showcasing the NVIDIA DRIVE Sim platform on Omniverse, generating synthetic data to comprehensively train deep neural networks for autonomous vehicle applications.
AI at the Edge
Data center operations don’t end once algorithms are validated. These DNNs are continuously improving to deliver cutting edge capabilities.
Alexandra Baleta and Thomas Schmitt of VMWare will join Christophe Couvreur, vice president of product at Cerence, Sunil Samil, vice president of products at Akridata, and Dean Harris, automotive business development manager at NVIDIA, will share how they enable AI applications in autonomous vehicles, leveraging near edge compute infrastructure for scale and cost optimization.
Florian Baumann, CTO of automotive and AI at Dell, will cover the ways autonomous vehicle developers can leverage enterprise AI, data science, and big data analytics to optimize the self-driving car experience.
Finally, General Motor’s Jayaraman Sivakumar and Brian Roginski, Tata Consultancy Services Head of Cognitive Business Sivakumar Shanmugam and Sean Young, NVIDIA Director BD Manufacturing, will discuss how GM has adopted virtualization to meet new demands for advanced engineering and design.
GTC will also include NVIDIA DRIVE Developer Days, running from April 20-22, which will consist of deep dive sessions on DRIVE end-to-end solutions.
Don’t miss out on the opportunity to learn from the premier experts in autonomous vehicle development — take advantage of free GTC registration today.
Many topics will be covered including solutions in computational fluid dynamics, predictive maintenance, inspection, and factory logistics across Industrial Manufacturing, Aerospace, Oil and Gas, Electronic Design Automation, Engineering Simulation, and more.
Industrial-Scale AI content is at GTC. From April 12-16, 1,400 live and on-demand sessions will be at your fingertips. Many topics will be covered including solutions in computational fluid dynamics, predictive maintenance, inspection, and factory logistics across Industrial Manufacturing, Aerospace, Oil and Gas, Electronic Design Automation (EDA), Engineering Simulation (CAE), and more.
Free registration provides access to topic experts, meet-and-greet networking events, and a keynote loaded with announcements from NVIDIA CEO Jensen Huang.
Here’s some of the top sessions for Industrial-scale AI at GTC21:
GE Renewable Energy: Advances in Renewable Energy: Enabling Our Decarbonized Energy Future with Technology Innovations and Smart Operations
Synopsys: GPU-Powered Order-of-Magnitude Speedup for IC Simulation
Cadence Design Systems: Accelerating PCB Layout Editor Using Modern GPU Architecture for Complex Designs
C3.ai: Transformer-Based Deep Learning for Asset Predictive Maintenance
Siemens: Physics-Informed Neural Network for Fluid-Dynamics Simulation and Design
BMW: A Simulation-First Approach in Leveraging Collaborative Robots for Inspecting BMW Vehicles
Data Monsters: Industrial Edge AI Challenges: Is Scaling Impossible?
CascadeTechnologies: Leveraging GPUs for High-Throughput, High-Fidelity Flow Simulations
See more featured speakers and events on the Manufacturing topic page. If you have already registered, there are pre-selected playlists for you to scroll through and build out your GTC schedule.
If you’re looking for a curated list of Edge AI sessions at GTC, we’ve put together top sessions in each Robotics category.
From Jetson 101 fundamental walk-throughs, to technical deep dive tutorials, GTC is hosting over 1,400 sessions for all technical abilities and applications. Free registration provides access to topic experts, meet-and-greet networking events, and a keynote loaded with breakthrough announcements from NVIDIA CEO Jensen Huang.
If you’re looking for a curated list of Edge AI sessions at GTC, we’ve put together top sessions in each Robotics category.
Special Events
[CWES1134]Connect with Experts: All Things Jetson Join Jetson experts from various teams including product, system software, hardware, and AI/deep learning for an engaging discussion with you.
[SE3283/SE3258]Ask and Learn about NVIDIA Jetson with Us Do you have questions about DLI topics on Getting Started with Jetson Nano, Jetbot, and Hello AI World? Come to these office hours.
[CWES1963]Connect with Experts (EMEA): AI at the Edge for Autonomous Machines, Robotics, and IVA Developing solutions for vision, autonomous machines, or robotics? Share your questions with our experts.
NVIDIA-Run DIY Maker Sessions
[S32700] Jetson 101: Learning Edge AI Fundamentals
[S32750] Build Edge AI Projects with the Jetson Community
[S32354] Optimizing for Edge AI on Jetson
[S31824] Sim-to-Real in Isaac Sim
Robotics in Education and Research
[S32637] Duckietown on NVIDIA Jetson: Hands-on AI in the classroom. (ETH Zurich)
[S32702] Hands-on deep learning robotics curriculum in high schools with Jetson Nano (CAVEDU)
Using Deep Learning and Simulation to Teach Robots Manipulation in Complex Environments (Dieter Fox, NVIDIA)
[S31905] Deep Learning Warm-Starts Grasp-Optimized Motion Planning (UC Berkeley)
[S31238] Robot Manipulator Joint Space Control via Deep Reinforcement Learning (NVIDIA)
[S31221] Improving Reinforcement Learning for Robot Manipulation via Composing Hierarchical Objecting-Centric Controllers (Carnegie Mellon University)
Commercial AI Applications
[S32588] A Mask-Detecting Smart Camera Using the Jetson Nano: The Developer Journey (Berkeley Design Technology, Inc)
[S31824] Sim-to-Real in Isaac Sim (NVIDIA)
[S32641] A New Kind of Collaboration: AI-Enabled Robotics and Humans Work Together to Automate Real-World Warehouse Tasks (Plus One Robotics)
[S32250] How AI is Revolutionizing Recycling: Practical Robotics at Scale (AMP Robotics)
[S31530] A Digital-Twin Use Case for Industrial Collaborative Robotics Applications Using Isaac Sim (Mondragon Unibertsitatea)
There’s a deep lineup of IVA sessions covering applications in smart spaces such as airports, railway transit hubs, smart traffic systems, and autonomous machines, with developer sessions for vision-AI optimization with Pre-trained models, DeepStream SDK, and Transfer Learning Toolkit.
Find out how to make our important physical spaces smarter using the most widely deployed IoT devices – video cameras.
NVIDIA GTC will be hosted on April 12-16. With over 1,400 breakthrough sessions for all technical levels, those registered have access to topic experts, networking events, and a front-row seat to NVIDIA CEO Jensen Huang’s keynote.
There’s a deep lineup of Intelligent Video Analytics sessions covering applications in smart spaces such as airports, railway transit hubs, smart traffic systems, and autonomous machines, with developer sessions for vision-AI optimization with Pre-trained models, DeepStream SDK, and Transfer Learning Toolkit.
Here are a few spotlight sessions to look out for:
[S32797] Train Smarter not Harder with NVIDIA Pre-trained models and Transfer Learning Toolkit 3.0 Learn how the world’s top AI teams combine pre-trained models and transfer learning to supercharge their AI vision development,
[S32798] Bringing Scale and Optimization to Video Analytics Pipelines with NVIDIA DeepStream SDK This talk provides a sneak peek at the next version of DeepStream. With all new intuitive GUI and development tools, it offers a zero-coding paradigm which further simplifies application development.
[CWES1127] Transfer Learning Toolkit and DeepStream SDK for Vision AI/Intelligent Video Analytics Get your questions answered on how to build and deploy vision AI applications for traffic engineering, parking management, sports analytics, retail, or smart workspaces for occupancy analytics and more.
[S31869] How Cities are Turning AI into Cost Savings Learn how the City of Raleigh, North Carolina, is building new AI-powered video analytics capabilities with ESRI’s ArcGIS into their traffic operations and turning real-time roadway insights into cost savings.
[S32032] Accelerating Azure Edge AI Vision Deployments Explore how GPU-accelerated model training and inference can span from the cloud to the edge, and how to leverage Azure Machine Learning and Live Video Analytics to create compelling solutions.
[S31845] AI-Enabled Video Analytics Improves Airline Operational Efficiency Get insights on how Seattle-Tacoma International Airport (SEA-TAC) is implementing AI video analytics to help improve overall airport operations.
[E31902] How AI Enabled Video Analytics Saves Lives and Money at Metropolitan Rail Networks Learn how AI-based video analytics solutions can be used to save money and increase safety operational efficiency in Metro rail networks with a case study from the UK rail industry.
[SS32770] Driving Operational Efficiency with NVIDIA Transfer Learning Toolkit, Pre-trained Models, and DeepStream SDK Learn how to build business value from Vision AI deployments using NVIDIA TLT, pre-trained models, and DeepStream SDK with ADLINK, including examples such as detecting loitering and intrusion
[SS33151] Designing AI Enabled Real-time Video Analytics at Scale Join experts from Quantiphi to learn how to address several engineering and costing challenges faced when going from an intelligent video analytics pilot to large-scale implementation.
[SS33127] Building Efficient and Intelligent Networks Using Network Edge AI Platform Lanner will partner with Tensor Network to discuss how NVIDIA AI can be structured in a networked approach where AI workloads can be distributed within the edge networks.
Posted by Aurko Roy, Research Scientist, Google Research
Open-domain long-form question answering (LFQA) is a fundamental challenge in natural language processing (NLP) that involves retrieving documents relevant to a given question and using them to generate an elaborate paragraph-length answer. While there has been remarkable recent progress in factoid open-domain question answering (QA), where a short phrase or entity is enough to answer a question, much less work has been done in the area of long-form question answering. LFQA is nevertheless an important task, especially because it provides a testbed to measure the factuality of generative text models. But, are current benchmarks and evaluation metrics really suitable for making progress on LFQA?
In “Hurdles to Progress in Long-form Question Answering” (to appear at NAACL 2021), we present a new system for open-domain long-form question answering that leverages two recent advances in NLP: 1) state-of-the-art sparse attention models, such as Routing Transformer (RT), which allow attention-based models to scale to long sequences, and 2) retrieval-based models, such as REALM, which facilitate retrievals of Wikipedia articles related to a given query. To encourage more factual grounding, our system combines information from several retrieved Wikipedia articles related to the given question before generating an answer. It achieves a new state of the art on ELI5, the only large-scale publicly available dataset for long-form question answering.
However, while our system tops the public leaderboard, we discover several troubling trends with the ELI5 dataset and its associated evaluation metrics. In particular, we find 1) little evidence that models actually use the retrievals on which they condition; 2) that trivial baselines (e.g., input copying) beat modern systems, like RAG / BART+DPR; and 3) that there is a significant train/validation overlap in the dataset. Our paper suggests mitigation strategies for each of these issues.
Text Generation The main workhorse of NLP models is the Transformer architecture, in which each token in a sequence attends to every other token in a sequence, resulting in a model that scales quadratically with sequence length. The RT model introduces a dynamic, content-based sparse attention mechanism that reduces the complexity of attention in the Transformer model from n2to n1.5, where n is the sequence length, which enables it to scale to long sequences. This allows each word to attend to other relevant words anywhere in the entire piece of text, unlike methods such as Transformer-XL where a word can only attend to words in its immediate vicinity.
The key insight of the RT work is that each token attending to every other token is often redundant, and may be approximated by a combination of local and global attention. Local attention allows each token to build up a local representation over several layers of the model, where each token attends to a local neighborhood, facilitating local consistency and fluency. Complementing local attention, the RT model also uses mini-batch k-means clustering to enable each token to attend only to a set of most relevanttokens.
Attention maps for the content-based sparse attention mechanism used in Routing Transformer. The word sequence is represented by the diagonal dark colored squares. In the Transformer model (left), each token attends to every other token. The shaded squares represent the tokens in the sequence to which a given token (the dark square) is attending. The RT model uses both local attention (middle), where tokens attend only to other tokens in their local neighborhood, and routing attention (right), in which a token only attends to clusters of tokens most relevant to it in context. The dark red, green and blue tokens only attend to the corresponding color of lightly shaded tokens.
We pre-train an RT model on the Project Gutenberg (PG-19) data-set with a language modeling objective, i.e, the model learns to predict the next word given all the previous words, so as to be able to generate fluent paragraph long text.
Information Retrieval To demonstrate the effectiveness of the RT model on the task of LFQA, we combine it with retrievals from REALM. The REALM model (Guu et al. 2020) is a retrieval-based model that uses the maximum inner product search to retrieve Wikipedia articles relevant to a particular query or question. The model was fine-tuned for factoid-based question answering on the Natural Questions dataset. REALM utilizes the BERT model to learn good representations for a question and uses SCANN to retrieve Wikipedia articles that have a high topical similarity with the question representation. This is then trained end-to-end to maximize the log-likelihood on the QA task.
We further improve the quality of REALM retrievals by using a contrastive loss. The idea behind this is to encourage the representation of a question to get close to its ground truth answer and diverge from the other answers in its mini-batch. This ensures that when the system retrieves relevant items using this question representation, it returns articles that are “similar” to ground truth answers. We call this retriever contrastive-REALM or c-REALM.
The combined RT + c-REALM system for LFQA.
Evaluation We test the model on long-form question answering using the ELI5 dataset, which is a part of the KILT benchmark, and is the only publicly available large-scaleLFQA dataset. The KILT benchmark measures text retrievals using Precision (R-Prec) and text generation using ROUGE-L. The two scores are combined to give a KILT R-L score, which determines a model’s ranking on the leaderboard. We fine-tune the pre-trained RT model together with retrievals from c-REALM on the ELI5 dataset from KILT.
Our submission tops the KILT leaderboard for long-form question answering on ELI5 with a combined KILT R-L score of 2.36. It improves on the previous leaderboard entry of BART + DPR (KILT R-L score of 1.9), while having a similar number of parameters as the other models on the leaderboard. In terms of text generation quality, we see an improvement of +4.11, +5.78 and +9.14 Rouge-L over T5, BART + DPR and RAG, respectively.
Our results on the KILT leaderboard for long form question answering on ELI5.
Example Generations from the RT Model
Q: Why are almost all boats white?
Boats are generally painted white for obvious reasons, as they are inexpensive and easy to clean. Ships are also often painted to provide a visible visual contrast to the sea. Boats also often have high visibility ports to allow for easy international trade. In addition, many boats have an air-breathing function that makes them easier to spot and stay afloat, which is a good thing if you’re a pirate or trying to get into some country’s waters. Lastly, many ships are built in the last few decades, so they are not as exotic looking as they were thirty years ago. And lastly, many ships are made out of materials that are easy to work with, and so many of them are painted white as a practical matter. There are many, many more reasons for why ships are white, but those are the ones I know of. I’m sure there are many other reasons, but those are the ones I know of. Edit: I forgot to mention that the other answers about visibility and easy to see ports are also true. Ships are painted to appear to be larger, and more expensive. That makes them appear more impressive, and so they are more likely to be bought by people who want to show off their wealth and status.
Q: What causes the trail behind jets at high altitude?
The same thing that causes the clouds you see at the start of a storm to form in the first place. The air pressure changes as the jet moves through the air, causing it to cool down and condense into water droplets. These droplets are in fact a lot bigger than the water droplets in the clouds, so when the plane passes through them, they can cause the air pressure to change, causing the water droplets to condense into clouds. This is what you see when you look at a cloud formation from the ground. In addition to this, when the plane passes through the clouds, it also moves through the air, causing it to change its temperature, causing the water droplets to condense and form clouds. These clouds are often quite large, and can block out the sun. This is what you see when you look at a contrail. Finally, the water vapor that forms at high altitudes is cooled by the air above, and as it cools, it condenses into clouds. This is what you see when you look at a cumulonimbus cloud. These clouds are even larger than the water droplets in the clouds, and they block out the sun.
Q: How do shampoo and conditioner work?
The key ingredients in shampoo and conditioner are usually surfactants, they tend to attract oil from your skin. Shampoo will usually contain an anti-dandruff agent (dandruff is caused by fungi in your skin which cause dandruff). They also contain some moisturizing agents (moisturizers are things that stay in your skin longer and protect your scalp from cleaning), and a lot of anti-dandruff (dandruff is a side effect of high doses of both surfactants and moisturizers) Conditioner will contain moisturizing agents, like a skin moisturizer. They tend to cause oils to be separated from your hair (e.g. wash your hair with conditioner instead of shampoo). They both have a foaming agent that makes them foam up (usually Hydrogen Peroxide). They also have a foaming agent that stops dirt from attaching to your hair. Some conditioner will also suppress the action of the shampoo (to help prevent dirt from attaching to your hair).
Q: When glancing at a clock, why does the first second after glancing at it sometimes feel longer than the rest?
This is known as chronostasis. Your brain gets used to seeing the second hand move after the first, so it ignores the first one. If you were to look at the clock a lot, you’d see the second hand move a lot more than the first, and you’d be able to tell the difference between the second and the first. The second hand will appear to move much slower than the first hand because your brain is used to seeing the second hand move a lot more than the first. If you were to go on a long trip, you’d get used to the second hand moving a lot more than the first, and you’d have no problem telling the difference between the second and the first hand. It’s kind of like how you don’t notice your nose when you’re driving, but if you look at it for a while, you start to notice it. Your brain is just getting used to seeing the nose move a lot more than the other, and it can’t tell the difference between the two. It’s kind of like that with your eyes.
Q: Why do Britain and other English empire countries still bow to monarchs? What real purpose does the queen serve?
Depends what you define as “purpose”. There is no specific purpose for the British monarch – rather, they are figureheads that serve a role. The role is to have a high degree of influence over a country, though the rules of the monarchy can somewhat vary from country to country, and the ceremony of “kissing the royal corpse” does not always involve kissing the monarch. Whether that’s the only reason for the custom, or if it was the only reason, I can’t say, but that’s the reasoning. When the U.K. was in full power, the monarch was a puppet of Parliament, and the powers of the monarch were transferred to the Prime Minister and thus to the Prime Minister’s deputy, who then became the Prime Minister. Since then, Parliament has been able to vote on legislation that goes through the monarch, although they may still act as the monarch’s representative in negotiating treaties, which can have very very deep consequences. The Queen’s role, as a representative of Britain, doesn’t necessarily involve her formal approval of any of the laws or legislation that goes through Parliament, though.
Q: What exactly is fire, in detail? How can light and heat come from something we can’t really touch?
Fire is the chemical reaction of fuel (oxygen) with (what we call) impurities (ash, soot, oil etc). These impurities are created due to a number of things. If you were to study the chemical composition of a log (or a candle) and analyse it you would discover the chemical formula (A, C, and G) which is a simplified version of what actually happens. There is always fuel, and there is always the ash/soot. Wood is made up of mostly carbon and hydrogen and these are the fuels that create the fire. Hydrogen and oxygen are reactive, and they form water (H2O) and CO2 (CO2). If we split a log into smaller pieces, we start to see the process of combustion as it occurs. The carbon is burned, and with the explosion of CO, H2O and H2CO2, we get water and carbon dioxide (mostly). If we smash a log together, we start to see what happens when we also hit another log with another log…imagine smashing two sand castles together. We see how the sand castles and brick castles form and collapse at different rates…then it starts to burn. The smoke, ash and flames are the actual combustion of fuel.
Q: What goes on in those tall tower buildings owned by major banks?
The actual buildings are not there for profit but for show. There are many real world historical buildings that have little to no effect other than being a symbol of an economic entity or symbol of an era or location, and nothing more. For example look at Sears, Sears didn’t care what went on inside, it was all about the _appearance_ of its location, the prestige of the location, the facilities and so on. It didn’t care about how long it took it to operate, it was about how much people would pay to go see it. Sears was a landmark as a cultural movement and other big companies followed suit, so if you want to see a building you’ve never seen before, you have to go see Sears, just like you have to see a Toyota Camry for Toyota Camry. They used to be all about building new factories, some of them if I recall, but now that they’re bigger, that means that more factory jobs are coming to them. You’ve probably seen them in stores as stores where people buy and sell stuff, so there aren’t that many places for them to come from. Instead, it’s just for show, a symbol of rich people.
Hurdles Towards Progress in LFQA However, while the RT system described here tops the public leaderboard, a detailed analysis of the model and the ELI5 dataset reveal some concerning trends.
Many held-out questions are paraphrased in the training set. Best answer to similar train questions gets 27.4 ROUGE-L.
Simply retrieving answers to random unrelated training questions yields relatively high ROUGE-L, while actual gold answers underperform generations.
Conditioning answer generation on random documents instead of relevant ones does not measurably impact its factual correctness. Longer outputs get higher ROUGE-L.
We find little to no evidence that the model is actually grounding its text generation in the retrieved documents — fine-tuning an RT model with random retrievals from Wikipedia (i.e., random retrieval + RT) performs nearly as well as the c-REALM + RT model (24.2 vs 24.4 ROUGE-L). We also find significant overlap in the training, validation and test sets of ELI5 (with several questions being paraphrases of each other), which may eliminate the need for retrievals. The KILT benchmark measures the quality of retrievals and generations separately, without making sure that the text generation actually use the retrievals.
Trivial baselines get higher Rouge-L scores than RAG and BART + DPR.
Moreover, we find issues with the Rouge-L metric used to evaluate the quality of text generation, with trivial nonsensical baselines, such as a Random Training Set answer and Input Copying, achieving relatively high Rouge-L scores (even beating BART + DPR and RAG).
Conclusion We proposed a system for long form-question answering based on Routing Transformers and REALM, which tops the KILT leaderboard on ELI5. However, a detailed analysis reveals several issues with the benchmark that preclude using it to inform meaningful modelling advances. We hope that the community works together to solve these issues so that researchers can climb the right hills and make meaningful progress in this challenging but important task.
Acknowledgments The Routing Transformer work has been a team effort involving Aurko Roy, Mohammad Saffar, Ashish Vaswani and David Grangier. The follow-up work on open-domain long-form question answering has been a collaboration involving Kalpesh Krishna, Aurko Roy and Mohit Iyyer. We wish to thank Vidhisha Balachandran, Niki Parmar and Ashish Vaswani for several helpful discussions, and the REALM team (Kenton Lee, Kelvin Guu, Ming-Wei Chang and Zora Tung) for help with their codebase and several useful discussions, which helped us improve our experiments. We are grateful to Tu Vu for help with the QQP classifier used to detect paraphrases in ELI5 train and test sets. We thank Jules Gagnon-Marchand and Sewon Min for suggesting useful experiments on checking ROUGE-L bounds. Finally we thank Shufan Wang, Andrew Drozdov, Nader Akoury and the rest of the UMass NLP group for helpful discussions and suggestions at various stages in the project.
A Swedish physician who helped pioneer chemistry 200 years ago just got another opportunity to innovate. A supercomputer officially christened in honor of Jöns Jacob Berzelius aims to establish AI as a core technology of the next century. Berzelius (pronounced behr-zeh-LEE-us) invented chemistry’s shorthand (think H20) and discovered a handful of elements including silicon. A Read article >
Hi folks, so I have followed this tutorial and Im pretty new to tensor flow but basically what I need to know is, is there any tutorials similar to this which teach you how to make the model run it in app but instead of live detecting in camera that it detects from images from the users gallery/camera roll. Any links/advice would be great thanks https://codelabs.developers.google.com/codelabs/recognize-flowers-with-tensorflow-on-android/#0

 Researchers from the U.S. National Institutes of Health have collaborated with NVIDIA experts on an AI-accelerated method to monitor COVID-19 disease severity over time from patient chest CT scans.
Researchers from the U.S. National Institutes of Health have collaborated with NVIDIA experts on an AI-accelerated method to monitor COVID-19 disease severity over time from patient chest CT scans. 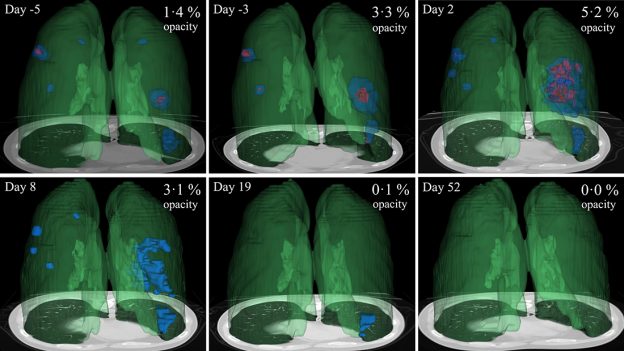





 Autonomous vehicles are born in the data center, and at GTC 2021, attendees can learn exactly how high-performance compute is vital to developing, training, testing and validating the next generation of transportation. The NVIDIA GPU Technology Conference returns to the virtual stage April 12-16, featuring autonomous vehicle leaders in a range of talks, panels and […]
Autonomous vehicles are born in the data center, and at GTC 2021, attendees can learn exactly how high-performance compute is vital to developing, training, testing and validating the next generation of transportation. The NVIDIA GPU Technology Conference returns to the virtual stage April 12-16, featuring autonomous vehicle leaders in a range of talks, panels and […] Many topics will be covered including solutions in computational fluid dynamics, predictive maintenance, inspection, and factory logistics across Industrial Manufacturing, Aerospace, Oil and Gas, Electronic Design Automation, Engineering Simulation, and more.
Many topics will be covered including solutions in computational fluid dynamics, predictive maintenance, inspection, and factory logistics across Industrial Manufacturing, Aerospace, Oil and Gas, Electronic Design Automation, Engineering Simulation, and more.  If you’re looking for a curated list of Edge AI sessions at GTC, we’ve put together top sessions in each Robotics category.
If you’re looking for a curated list of Edge AI sessions at GTC, we’ve put together top sessions in each Robotics category. There’s a deep lineup of IVA sessions covering applications in smart spaces such as airports, railway transit hubs, smart traffic systems, and autonomous machines, with developer sessions for vision-AI optimization with Pre-trained models, DeepStream SDK, and Transfer Learning Toolkit.
There’s a deep lineup of IVA sessions covering applications in smart spaces such as airports, railway transit hubs, smart traffic systems, and autonomous machines, with developer sessions for vision-AI optimization with Pre-trained models, DeepStream SDK, and Transfer Learning Toolkit.





