
An overview of end-to-end entity resolution for big data, Christophides et al., ACM Computing Surveys, Dec. 2020, Article No. 127
The ACM Computing Surveys are always a great way to get a quick orientation in a new subject area, and hot off the press is this survey on the entity resolution (aka record linking) problem. It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects.
Entity Resolution (ER) aims to identify different descriptions that refer to the same real-world entity appearing either within or across data sources, when unique entity identifiers are not available.
When ER is applied to records from the same data source it can be used for deduplication, when used to join records across data sources we call it record linking. Doing this well at scale is non-trivial; at its core, the problem requires comparing each entity to every other, i.e. it is quadratic in input size.
An individual record/document for an entity is called an entity description. A set of such descriptions is an entity collection. Two descriptions that correspond to the same real world entity are called matches or duplicates. The general flow of an ER pipeline looks like this:
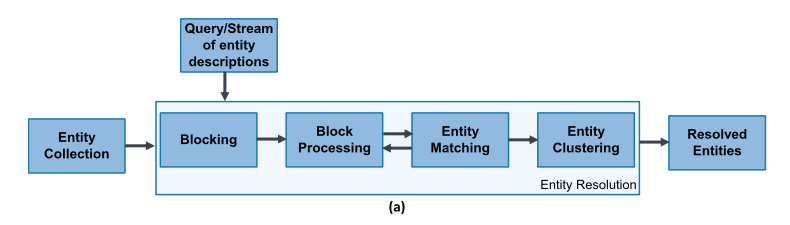
- Blocking takes input entity descriptions and assigns them to one or more blocks based on blocking keys. The point of blocking is to reduce the number of comparisons that have to be made later on – the key idea is that any two entity descriptions that have a chance of referring to the same real-world entity should end up in the same block under at least one of the blocking keys. Therefore we only have to do more detailed comparisons within blocks, but not across blocks. “The key is redundancy, i.e., the act of placing every entity into multiple blocks, thus increasing the likelihood that matching entities co-occur in at least one block.”
- Block processing then strives to further reduce the number of comparisons that will need to be made by eliminating redundant comparisons that occur in multiple blocks, and superfluous comparisons within blocks.
- Matching takes each pair of entity descriptions from a block and applies a similarity function to determine if they refer to the same real-world entity or not. (In an iterative ER process, matching and blocking may be interleaved with the results of each iteration potentially impacting the blocks).
- Clustering groups together all of the identified matches such that all the descriptions within a cluster refer to the same real-world entity. The clustering stage may infer additional indirect matching relations.
The resulting clusters partition the input entity collections into a set of resolved entities.
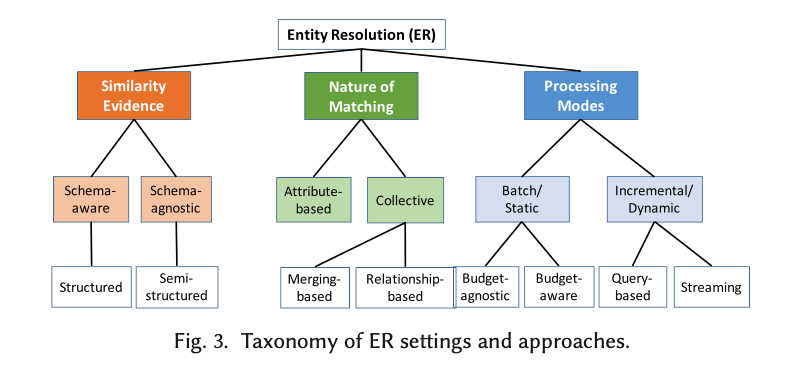
ER solutions can be classified along three dimensions:
- Schema-awareness – is there a schema to give structure to the data or not?
- The nature of the matching process – is it based on a comparison of attributes in the entity descriptions, or is there more complex matching going on such as comparing related entities to give further confidence in matching?
- The processing mode – traditional batch (with or without budget constraints), or incremental.
Let’s dive into each of the major pipeline stages in turn to get a feel for what’s involved…
Blocking
There’s a whole separate survey dedicated just to the problem of blocking for relational data, so in this survey the authors focus their attention on blocking for schema-less data. There are lots of different approaches to this:
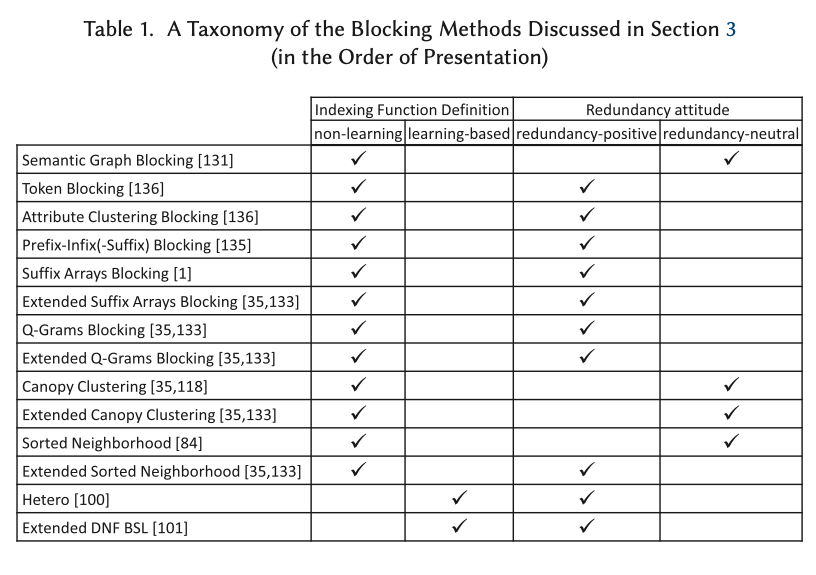
Classic approaches look at relations and attributes. For example Token Blocking makes one block for each unique token in values, regardless of the attribute. Any entity with that token in the value of any attribute is added to the block. Redundancy positive blocking schemes such as token blocking are those in which the probability that two descriptions match increases with the number of blocks that include both of them. For redundancy neutral schemes this is not the case. An example of a redundancy neutral scheme is Canopy Clustering, which uses token-based blocks, but assigns an entity to a block based on a similarity score being greater than a threshold $t_{in}$. Moreover, if the similarity score exceeds $t_{ex} (> t_{in})$ then the description is not added to any further blocks.
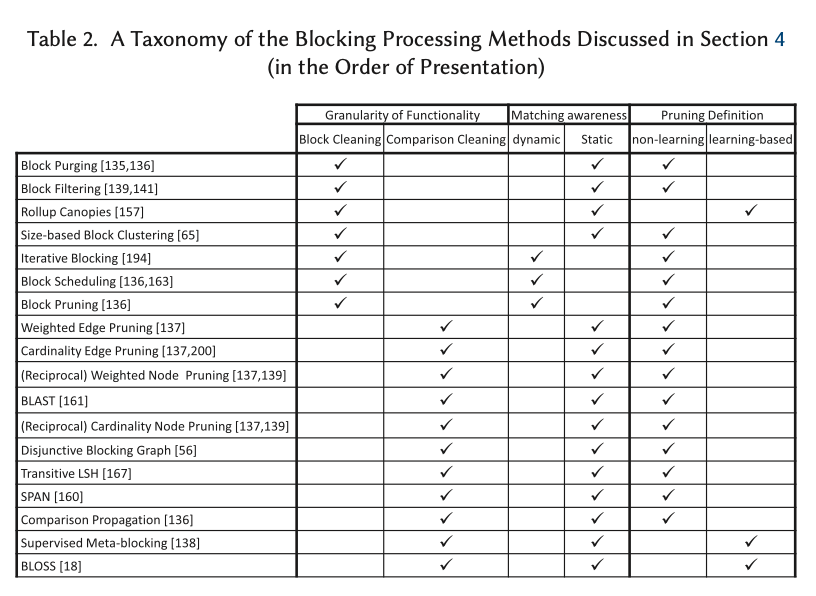
Block processing
As with blocking, there are a multiplicity of approaches to block processing. Block cleaning methods may purge excessively large blocks (as these are likely to be the result of common stop-word tokens and hence less useful for matching) and filter the blocks a given description is present in – for example by removing the description from the largest $r%$ of the blocks it appears in. More sophisticated methods may also split and merge blocks. Dynamic approaches schedule block processing on the fly to maximise efficiency.
Comparison cleaning methods work on redundancy positive block collections. A graph is constructed where nodes are entity descriptions, and there is an edge between every pair of nodes co-located in a block, with an edge weight representing the likelihood of a match, e.g. the number of blocks they are co-located in. Once the graph is constructed, edge-pruning can be used to remove lower weighted edges. There are a variety of strategies both for weighting and for pruning edges. For example, Weighted Edge Pruning removes all edges less than or equal to the average edge weight. After pruning, new blocks are created from the retained edges. Learning-based methods train classifiers for pruning.
Matching
A matching function $M$ takes a pair of entity descriptions and measures their similarity using some similarity function $sim$. If the similarity score exceeds a given threshold they are said to match, otherwise they do not match. In a refinement the match function may also return uncertain for middling scores. The similarity function could be atomic, such as Jaccard similarity, or composite (e.g., using a linear combination of several similarity functions on different attributes). Any similarity measure that satisfies non-negativity, identity, symmetry, and triangle inequality can be used.
Collective based matching processes use an iterative process to uncover new matches as a result of matches already made. Merging-based collective techniques create a new entity description based on merging a matched pair, removing the original paired descriptions. Relationship-based collective techniques use relationships in the original entity graph to provide further similarity evidence. For example, Collective ER…
Collective ER employs an entity graph, following the intution that two nodes are more likely to match, if their edges connect to nodes corresponding to the same entity. To capture this iterative intuitive, hierarchical agglomerative clustering is performed, where, at each iteration, the two most similar clusters are merged, until the similarity of the most similar cluster is below a threshold.
A variety of supervised, semi-supervised, and unsupervised matching techniques have also been developed.
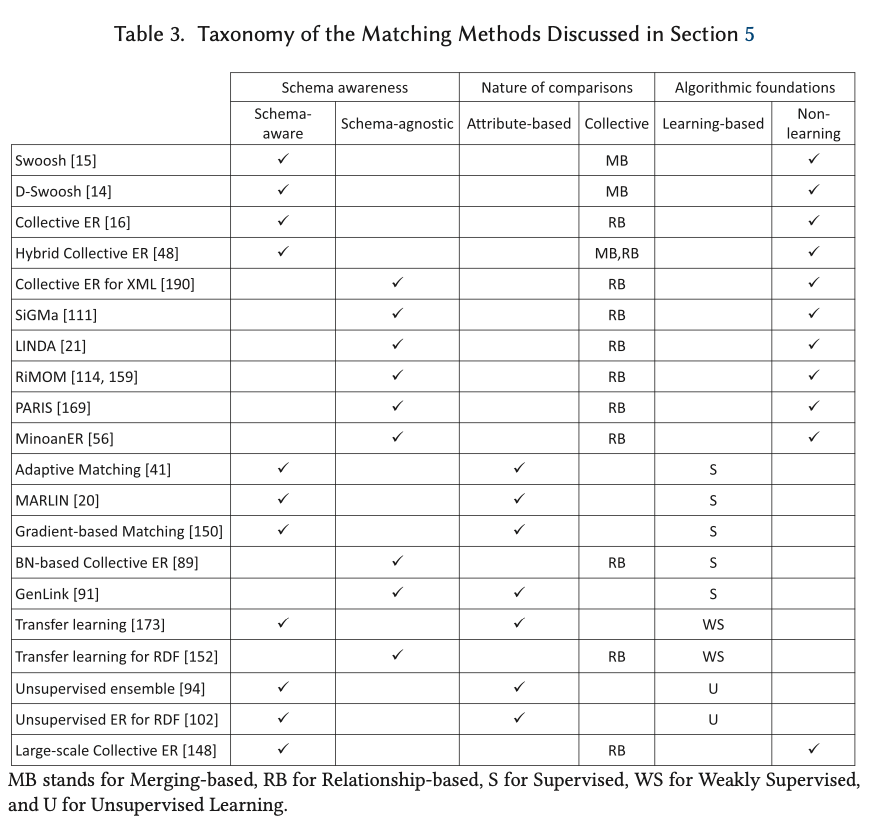
The output of the matching process is a similarity graph with nodes corresponding to descriptions and edges connecting descriptions that matched, weighted by the matching probability.
Clustering
Clustering aims to infer more edges from indirect matching relations, while discarding edges that are unlikely to connect duplicates in favor of edges with higher weights. Hence, its end result is a set of entity clusters, each of which comprises all descriptions that correspond to the same, distinct real-world object.
The simplest approach is just to find Connected Components, but generally more advanced clustering techniques are used. For example, Markov Clustering uses random walks to strengthen intra-cluster edges while weakening inter-cluster ones.
Making it incremental
Section 8 in the survey discusses incremental approaches, but my general takeaway is that these seem rather thin on the ground, and mostly oriented towards assembling the information needed to answer an incoming query on the fly. The exception is Incremental Correlation Clustering which updates the clustering results on the fly based on newly created, updated, and deleted descriptions. All of the discussed approaches require schemas.
Open source ER systems
The survey includes an assessment of open source tools for ER, summarised in the table below.
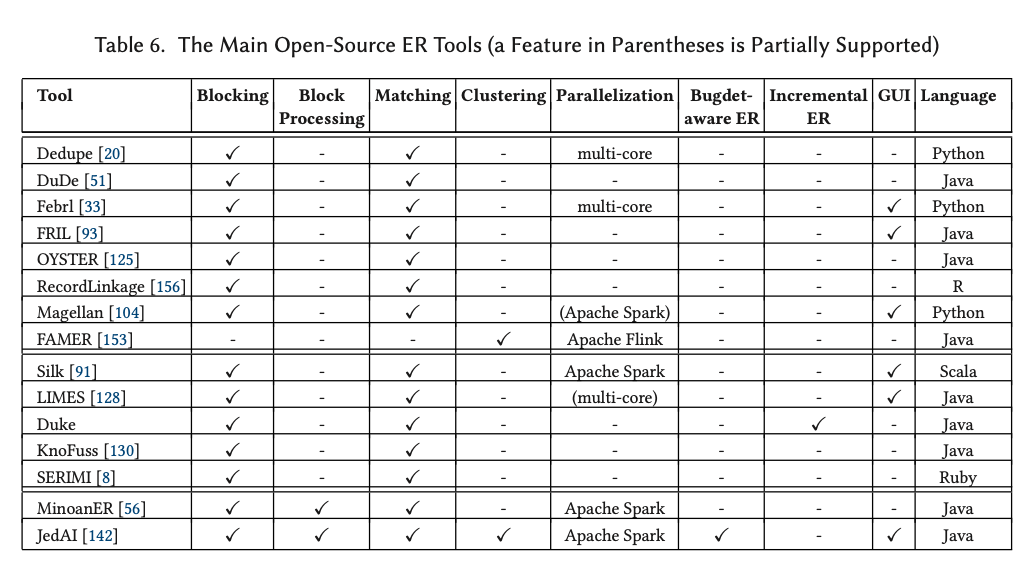
…we share the view of ER as an engineering task by nature, and hence, we cannot just keep developing ER algorithms in a vacuum. In the Big Data era, we opt for open-world ER systems that allow one to plug-and-play different algorithms and can easily integrate with third-party tools for data exploration, data cleaning, or data analytics.